KV Cache 作为大模型推理的 “显存刺客”,既以 5 倍加速征服行业,又因海量显存开销让 HBM 告急。而当缓存不得不落盘存储时,数据搬运速度又成为新瓶颈 ——GPU 算得再快,没有数据投喂也只能空转。针对这一痛点,DeepSeek 联合北大、清华研究团队推出DualPath 大模型推理系统,通过创新的 “双路径 KV-Cache 加载” 机制,极限压榨存储带宽,解决 Agent 长文本推理场景下的 I/O 瓶颈,让离线推理吞吐量最高提升 1.87 倍,在线服务吞吐量平均提升 1.96 倍。

Agent 时代的推理革命:瓶颈从计算转向 I/O
随着大模型从单轮对话演进为能调用工具、多轮交互的智能体,推理 workload 已发生根本性转变:从 “短平快” 的人类 - LLM 交互,变成 “持久战” 式的人类 - LLM - 环境交互,单次任务平均交互 157 轮,上下文长度达 32.7k tokens,而每轮新增内容仅 429 tokens,KV Cache 命中率高达 98.7%。
这种 “长上下文、短追加” 模式,让推理瓶颈彻底从 “GPU 算得快不快” 转向 “KV Cache 搬得快不快”。论文数据显示,DeepSeek-V3.2 660B 模型的 “缓存 - 计算比” 达 22 GB/PFLOP—— 每 1PFLOP 的计算,需要搬运 22GB 的 KV Cache 数据。高命中率带来的不是效率极致,而是 I/O 成为新的性能枷锁。
传统架构的结构性失衡:一边堵死,一边闲置
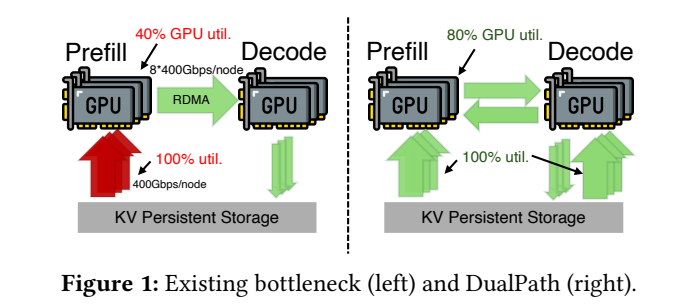
当前主流的预填充 - 解码分离架构(PD-disaggregated architecture),在 Agent 场景下暴露出致命缺陷:
-
预填充引擎(PE):负责加载历史 KV Cache、处理 prompt,所有缓存都需从外部存储读取,导致存储网卡带宽饱和(400Gbps 节点扛不住数十 GB 并发读取);
-
解码引擎(DE):仅负责逐词生成,几乎不读取存储,存储网卡大规模闲置。
这种 “冷热不均” 的结构性失衡,让预填充引擎成为瓶颈,解码引擎的闲置带宽无法利用,整个系统吞吐量被严重限制。
DualPath 核心突破:双路径并行,盘活闲置带宽
DualPath 的核心创新,是打破 “存储→预填充” 的单一路径依赖,引入存储到解码(Storage-to-Decode)路径,形成双路径并行加载机制,让解码节点的闲置带宽参与数据搬运:
-
传统路径(存储→预填充):保留原有加载逻辑,满足基础缓存需求;
-
新增路径(存储→解码→预填充):先将 KV Cache 加载到解码引擎,再通过 RDMA 高速计算网络转发给预填充节点,分流预填充引擎的 I/O 压力。
这就像打仗时开辟 “双线补给”—— 原本粮草只能先运大营再送前线,现在新增一路直接送前线,再通过前线驰道反哺大营,彻底解决大营拥堵、前线断供的问题。通过全局带宽池化与动态调度,系统可根据实时负载分配流量,让两条路径各司其职、负载均衡。
三大解药破解副作用,保障系统稳定高效
引入双路径并非简单 “多开一条路”,还会引发流量干扰、实时决策、负载均衡三大问题,DualPath 针对性给出解决方案:
1. 流量干扰:最高优先级保障推理通信
新增的 KV Cache 传输可能与 MoE 架构 AllToAll、张量并行 ReduceScatter 等延迟敏感的集合通信撞车。DualPath 通过 “以计算网卡为中心的流量管理” 破解:
-
所有 GPU 流量强制走 GPUDirect 路径,利用 InfiniBand 虚拟通道技术,为模型推理通信预留 99% 带宽,设为最高优先级;
-
KV Cache 传输仅 “蹭” 空闲间隙,不占用核心带宽,即使存储网卡跑满,计算通信也不受影响;
-
兼容 RoCE 网络,通过 Traffic Class 和 DSCP 标记实现相同 QoS 隔离效果。
2. 实时决策:自适应调度器毫秒级分配任务
系统需在毫秒级决定请求走哪条路径,避免新瓶颈。DualPath 的 “自适应请求调度器” 实时监控节点磁盘队列长度和 Token 数量,将引擎分为三类:
-
过载引擎(token 数 >β):拒绝新任务;
-
轻载且磁盘队列短(read_q≤α 且 token≤β):优先分配任务,从源头避免拥塞;
-
轻载但磁盘队列长(read_q>α 且 token≤β):暂缓分配,平衡 I/O 压力。
其中 α 为 3 秒可读取 token 数,β 为单 GPU 5 秒可处理 token 数,通过预配置适配不同场景。
3. 负载均衡:层级流式处理避免单向拥堵
为防止压力从预填充节点转移到解码节点,DualPath 采用 “层级流式处理 + 两层调度”:
-
KV Cache 按层传输,计算与通信重叠执行,预填充节点算完一层,下一层数据恰好到达,GPU 无空等;
-
设计 Full Block(存所有层)和 Layer Block(存单层)两种布局,存储用 Full Block 保证效率,传输用 Layer Block 支持细粒度流式处理。
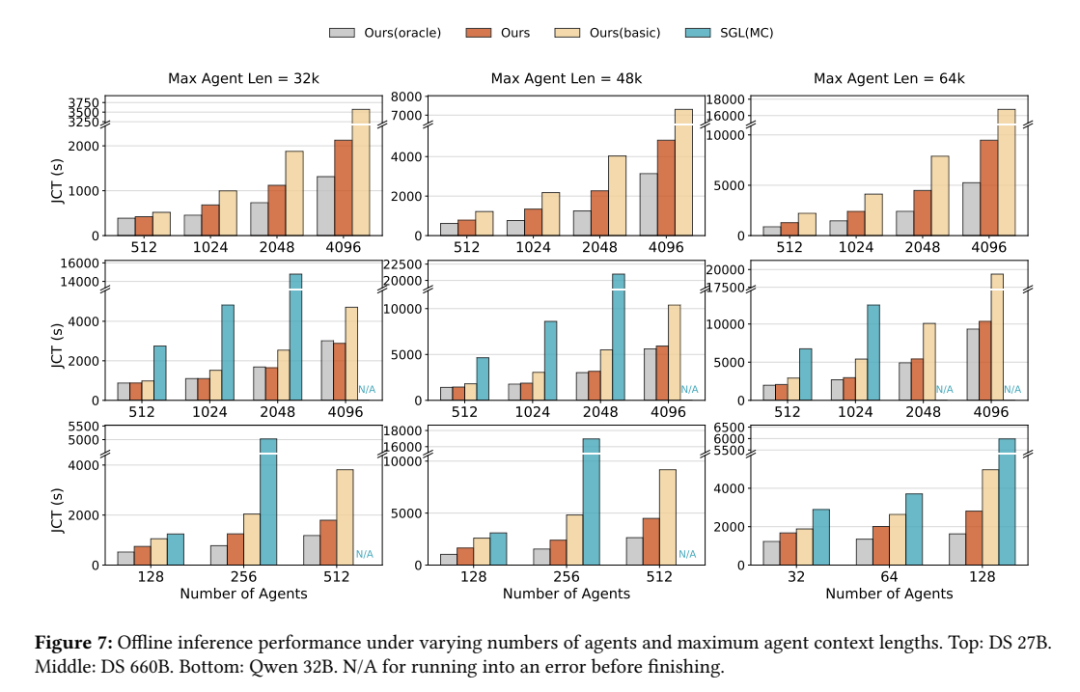
性能实测:吞吐量翻倍,逼近理论极限
DeepSeek 在 InfiniBand 互连的 Hopper 架构 GPU 集群上验证,DualPath 在真实 Agent 工作负载下表现惊艳:
-
离线推理:DS 660B 模型的端到端吞吐量最高提升 1.87 倍,性能接近 Oracle(理论最优),KV Cache 加载的 I/O 瓶颈几乎被消除;
-
在线服务:模拟 Agent 按泊松分布持续到达的生产场景(TTFT≤4 秒、TPOT≤50 毫秒),系统可承载的到达率最高提升 2.25 倍,支持更长上下文(32k/48k/64k tokens)稳定运行;
-
跨模型适配:在 DS 27B、Qwen 32B 等不同规模模型上均表现稳定,未出现报错或性能骤降。
核心逻辑:资源池化是下一代 AI 基建的必由之路
DualPath 的底层逻辑,与内存池化理念异曲同工 —— 打破资源 “属地管理” 的孤立格局,通过高速网络连接分散资源,实现全局调度。其架构依赖 RDMA 网络、高性能存储和精细 QoS 机制,而这与柏睿光存算一体机的技术路线高度契合:
-
智存扩展卡通过 PCIe 直连 GPU,支持存储到 GPU 直接路径,传输带宽远超传统 CPU 拷贝;
-
32 个 100G RoCE 接口提供 25000MB/s 带宽,支持 RDMA,可预留推理通信带宽;
-
硬件深度融合计算、存储、网络,形成分布式存储资源池,完美适配 DualPath 的双路径架构。
DualPath 的发布,不仅解决了 Agent 推理的 I/O 瓶颈,更印证了 “资源池化 + 全局调度” 是下一代 AI 基础设施的核心方向。当大模型竞争从模型本身延伸到工程化优化,这类 “极限压榨效率” 的创新,将成为企业破局的关键。
如果你正在部署 Agent 相关场景,是否会尝试用 DualPath 优化 KV Cache 加载效率?欢迎在评论区分享你的使用场景和期待!