在智能体成为主流 AI 开发范式的当下,大模型推理正面临全新挑战 —— 存储带宽瓶颈。2026 年 2 月 27 日,DeepSeek 联合北京大学、清华大学在 ArXiv 发布重磅论文,推出创新推理系统 DualPath。该系统通过「双路径 KV-Cache 加载」机制,彻底解决预填充 - 解码(PD)分离架构下的负载不平衡问题,实现离线推理吞吐量 1.87 倍、在线服务吞吐量 1.96 倍的跨越式提升,为智能体场景的高效推理提供了系统级解决方案。

核心痛点:智能体场景的存储带宽困境
智能体的多轮互动特性,使其呈现「长上下文、短追加」的负载特征 —— 上下文随轮次累积可达数万 token,而每轮新增内容仅数百 token,导致 KV-Cache 命中率普遍高于 95%。此时,系统性能的核心限制已不再是 GPU 计算能力,而是从存储中加载 KV-Cache 的效率。
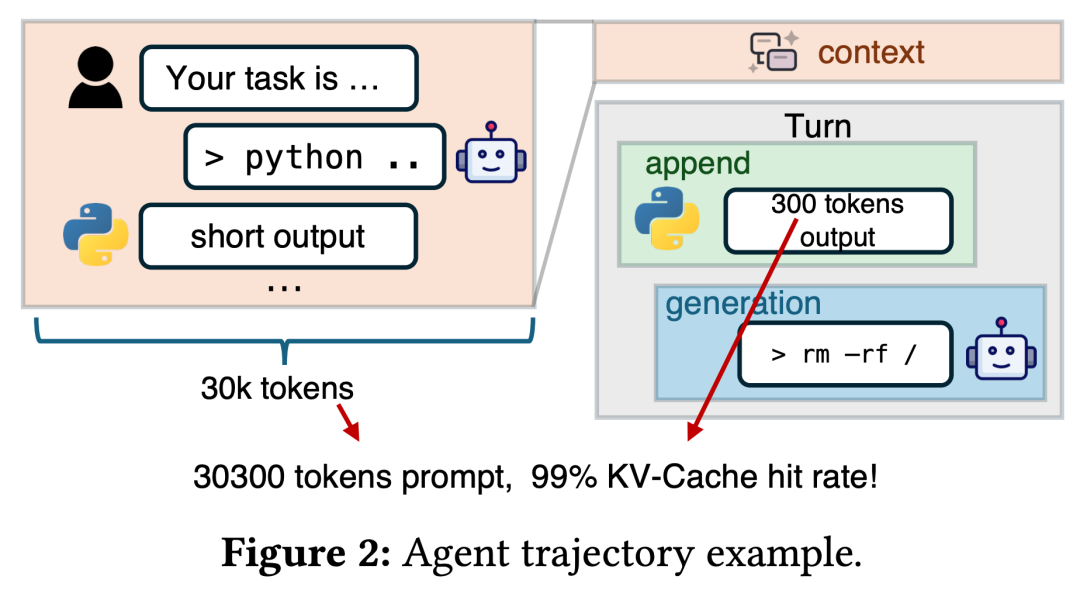
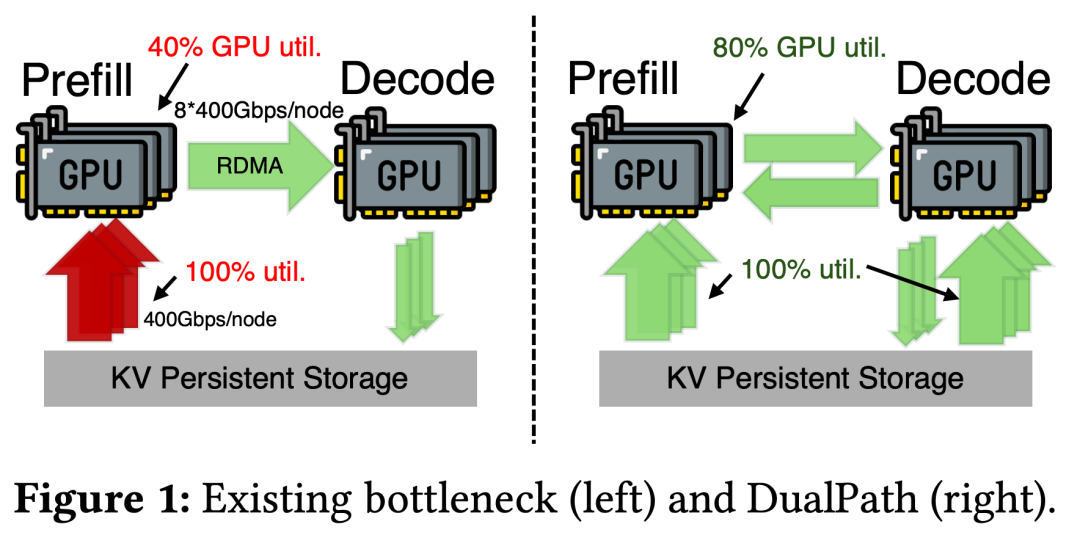
在传统 PD 分离架构中,这一问题被进一步放大:所有存储 I/O 压力完全集中在预填充引擎(PE)的存储网卡上,解码引擎(DE)的存储带宽却处于闲置状态。这种极度不平衡的带宽利用模式,成为制约系统吞吐量的核心障碍,严重影响智能体的实时响应能力。
核心创新:双路径 KV-Cache 加载机制
DualPath 的核心突破在于重新设计了 KV-Cache 的数据加载路径,通过「双路并行 + 带宽池化」,彻底打破单节点 I/O 限制。
1. 双路径并行加载
摒弃传统「存储→预填充引擎」的单一路径,新增「存储→解码引擎→预填充引擎」的第二条路径:
-
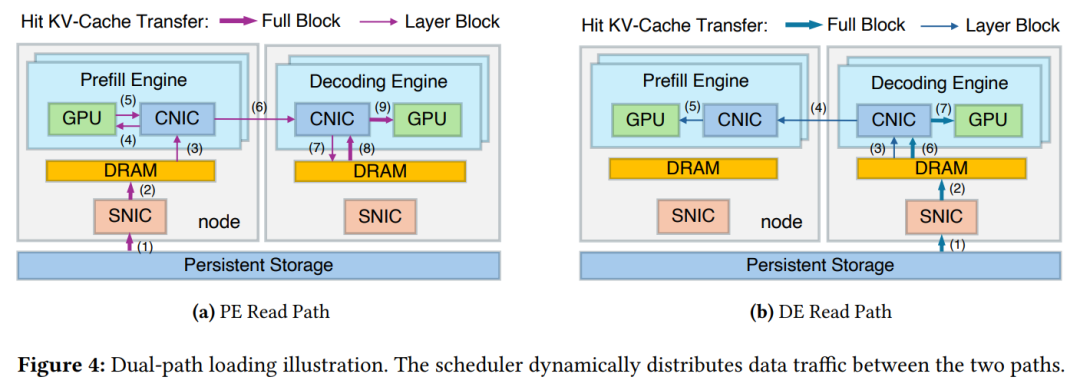
路径一(PE Read Path):KV-Cache 直接从持久化存储读入预填充引擎的缓冲区(PE buffer),再按层传输至 GPU 的 HBM,用于计算未命中的 prompt token;
-
路径二(DE Read Path):KV-Cache 先加载到解码引擎的缓冲区(DE buffer),再通过高带宽 RDMA 计算网络传输至预填充引擎,充分利用解码引擎闲置的存储带宽。
两条路径并行工作,使系统能同时调动所有引擎的存储网卡资源,从根本上缓解预填充侧的 I/O 压力。
2. 带宽资源池化
通过动态负载分配,DualPath 将集群中所有引擎的存储网卡聚合为「全局带宽池」,彻底打破单节点的 I/O 限制。例如,原架构中 8×400Gbps 的预填充侧带宽与闲置的解码侧带宽,在 DualPath 中被整合为统一资源,实现带宽利用效率的最大化。
3. 关键辅助技术
为确保大规模数据传输不干扰延迟敏感型推理任务,DualPath 配套两项核心技术:
-
以计算网卡(CNIC)为中心的流量管理:统一管理所有 GPU 相关流量(含内存拷贝),通过 QoS 机制将推理通信设为高优先级,确保 KV-Cache 加载仅占用闲置带宽,不影响延迟 SLO;
-
自适应请求调度:调度器实时监控各引擎的磁盘队列长度与计算负载,动态选择最优加载路径,并通过计算配额机制减少 GPU 执行中的闲置时间(气泡)。
系统架构:三层组件协同,实现无瓶颈推理
DualPath 建立在 PD 解耦与 Layerwise Prefill 两项成熟技术之上,由三大核心组件构成闭环系统:
1. 推理引擎(Inference Engines)
每个引擎管理一张 GPU,分为两类角色:
-
预填充引擎(PE):负责 prompt 处理与 KV-Cache 计算;
-
解码引擎(DE):负责 token 生成与 KV-Cache 合并;
两类引擎均配置专用 DRAM 缓冲区(PE buffer/DE buffer),用于 KV-Cache 的临时存储与流转。
2. 流量管理器(Traffic Manager)
嵌入每个引擎内部,承担三大核心职责:
-
主机与设备间的内存拷贝(H2D/D2H);
-
PE 与 DE 之间的 KV-Cache 高速传输;
-
通过存储网卡进行 KV-Cache 读写;
其核心作用是隔离推理流量与数据加载流量,避免相互干扰。
3. 请求调度器(Request Scheduler)
中心化调度核心,负责接收客户端请求并分配至不同引擎,同时动态平衡两条加载路径的流量分配,确保负载均衡。
此外,DualPath 采用「完整块 + 层级块」的混合数据布局:与存储交互时使用完整块(含所有层信息),引擎间传输时使用层级块(单一层信息),兼顾传输效率与计算兼容性。
关键挑战与解决方案
双路径架构的落地面临三大核心挑战,论文给出了针对性解决方案:
-
细粒度数据传输:层级执行范式导致 KV-Cache 碎片化,DualPath 通过优化数据传输协议,实现细粒度块的低开销传输,并与计算任务无缝重叠;
-
流量隔离:通过 CNIC 集中管理与 QoS 优先级设置,确保 KV-Cache 传输流量不干扰专家并行的 AllToAll、张量并行的 ReduceScatter 等延迟敏感型通信操作;
-
动态负载均衡:调度器实时监控存储网卡队列、GPU 负载与请求特性,动态调整路径分配,避免单路径过载。
实测性能:吞吐量翻倍,延迟稳定
研究团队在包含 1152 个 GPU 的大规模生产集群上,基于 DS 660B(MoE + 稀疏注意力)、DS 27B、Qwen 32B 三款模型进行实测,验证了 DualPath 的显著优势:
1. 离线批量推理(模拟 RL rollout 场景)
-
随着 Agent 批量规模增大和上下文长度延长,DualPath 优势愈发明显;
-
在 DS 660B 模型上,相比传统架构最高实现 1.87 倍加速,性能接近理论最优的 Oracle 方案,KV-Cache I/O 开销基本消除;
-
DS 27B 模型上实现 1.78 倍提升,Qwen 32B 趋势一致,证明方案对稠密模型与稀疏模型均有效。
2. 在线推理服务(模拟真实生产环境)
-
设定 TTFT(首 token 延迟)≤4 秒、TPOT(token 间延迟)≤50 毫秒的 SLO 目标,DualPath 将系统可承载的请求到达率上限大幅提升:DS 27B 提升 1.67 倍,DS 660B 提升 2.25 倍;
-
高负载下,DualPath 能保持 TTFT 稳定,而传统架构因存储带宽不足,排队时间迅速上升导致延迟恶化;
-
TPOT 与传统架构基本持平,证明优化仅作用于 KV-Cache 读取与排队阶段,不影响解码效率。
行业意义:智能体推理的效率革命
DualPath 的推出,不仅为智能体场景的大模型推理提供了高效解决方案,更重构了推理系统的设计逻辑 —— 从「计算为中心」转向「计算 - 存储协同为中心」。其核心价值在于:
-
首次系统性解决智能体场景的存储带宽瓶颈,为大规模智能体部署扫清障碍;
-
双路径架构与流量管理方案,为复杂推理系统的性能优化提供了可复用范式;
-
兼容稠密模型与 MoE 稀疏模型,具备广泛的产业落地价值。