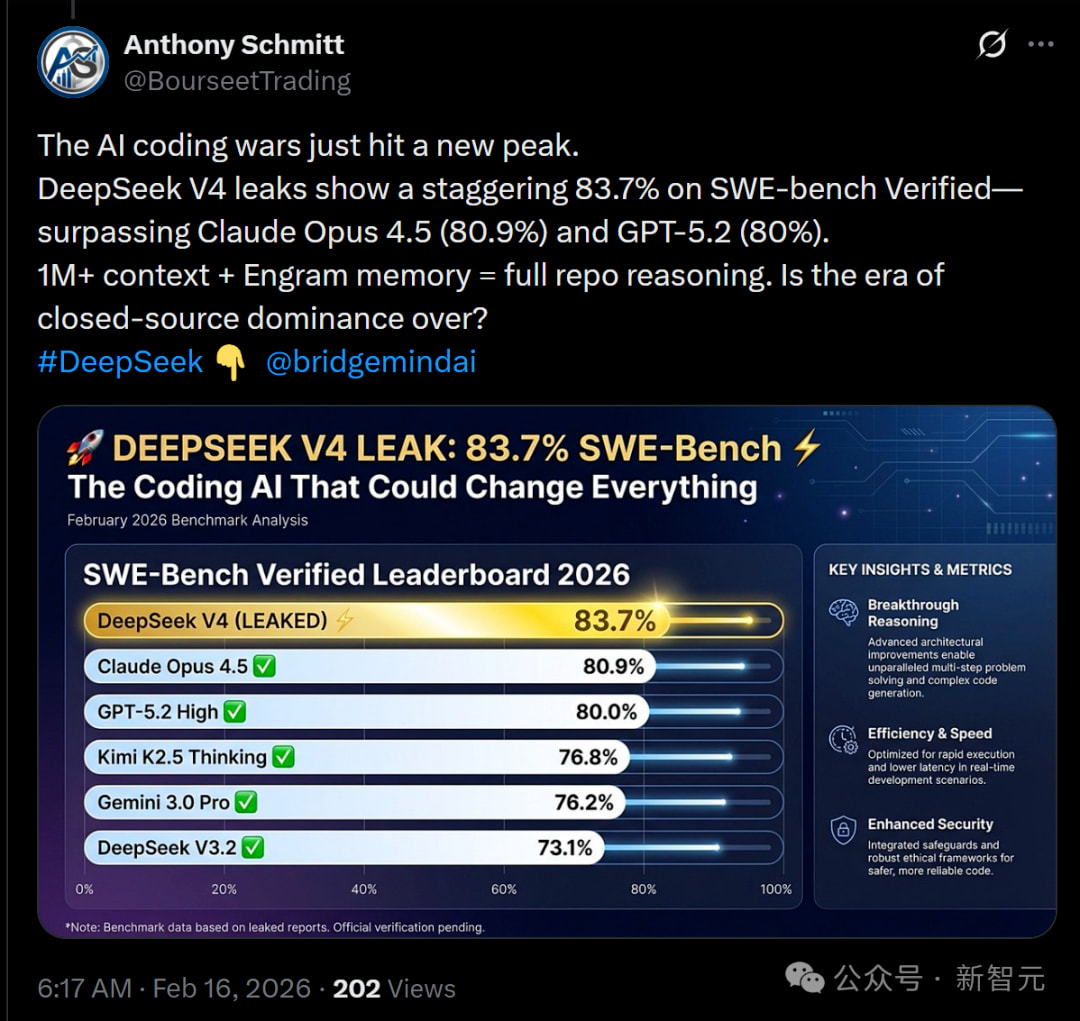
2026 年 2 月 16 日,AI 圈被一张泄露的基准测试图引爆 —— 国产开源模型 DeepSeek V4 疑似即将发布,其 SWE-bench Verified 得分高达 83.7%,超越 Claude Opus 4.5(80.9%)和 GPT-5.2(80%),跻身全球编程模型第一梯队。伴随 100 万 token 超长上下文、20-40 倍于 OpenAI 的成本优势等传闻,网友惊呼 “开源模型要终结闭源时代”。尽管部分泄露数据遭打假,但 DeepSeek 在网页和 APP 上低调测试的超长上下文功能已实锤,让这款号称 “编程之王” 的开源模型成为春节前最受期待的 AI 新品。
泄露数据刷屏:编程能力碾压顶尖闭源模型?
此次泄露的基准测试数据堪称 “炸裂”,DeepSeek V4 在多维度高难度任务中展现出跨越式提升,尤其在编程赛道实现对闭源巨头的反超:
-
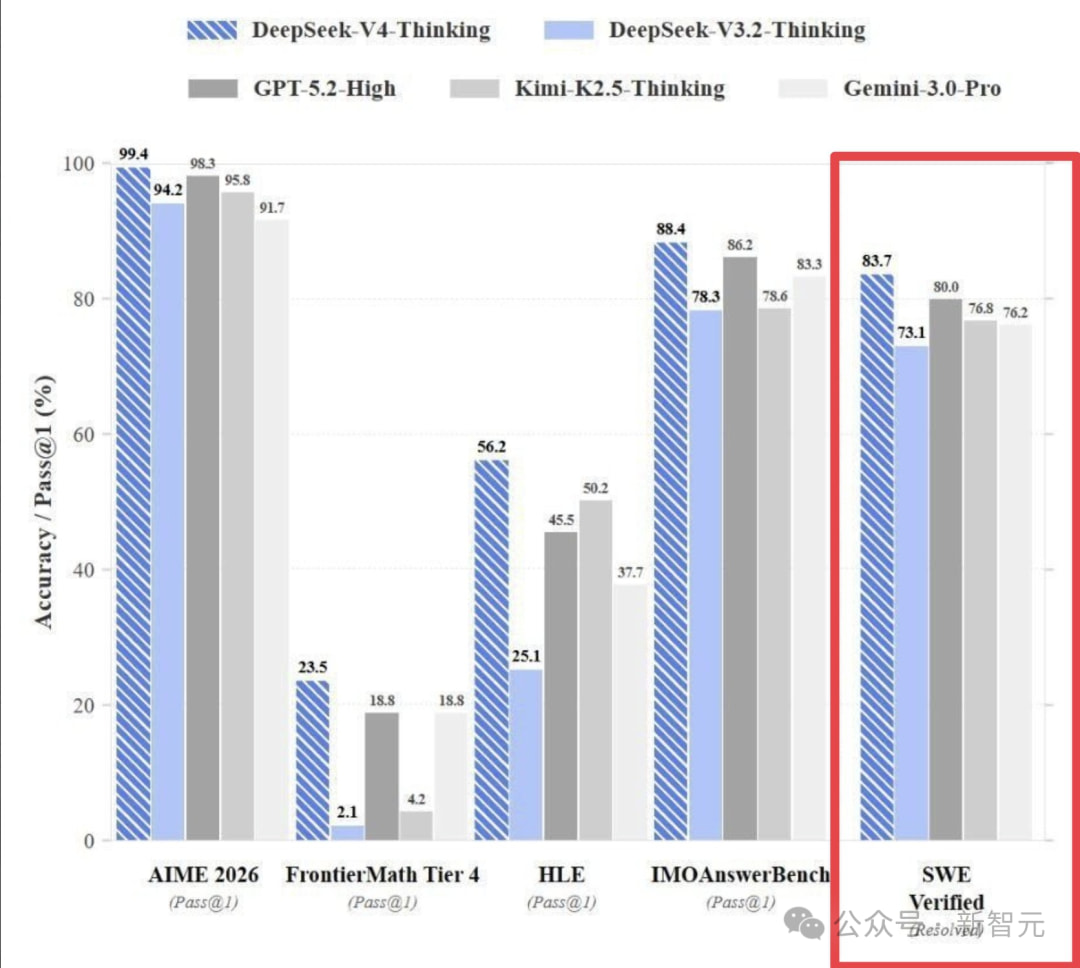
编程能力登顶:SWE-bench Verified(软件工程任务基准)得分 83.7%,超越 Claude Opus 4.5 和 GPT-5.2,较上一代 DeepSeek V3.2(73.1%)提升超 10 个百分点;HumanEval(代码生成基准)约 90%,进入行业第一梯队;
-
数学推理能力飙升:AIME 2026(数学竞赛)得分 99.4%,IMO Answer Bench(奥林匹克数学基准)88.4%,FrontierMath Tier 4(前沿数学)23.5%(据称是 GPT-5.2 的 11 倍);
-
全维度无短板:在 HLE(高阶语言理解)、跨模态任务等基准中均表现突出,被网友评价为 “同时刷新代码、竞赛数学、前沿推理三大天花板”。
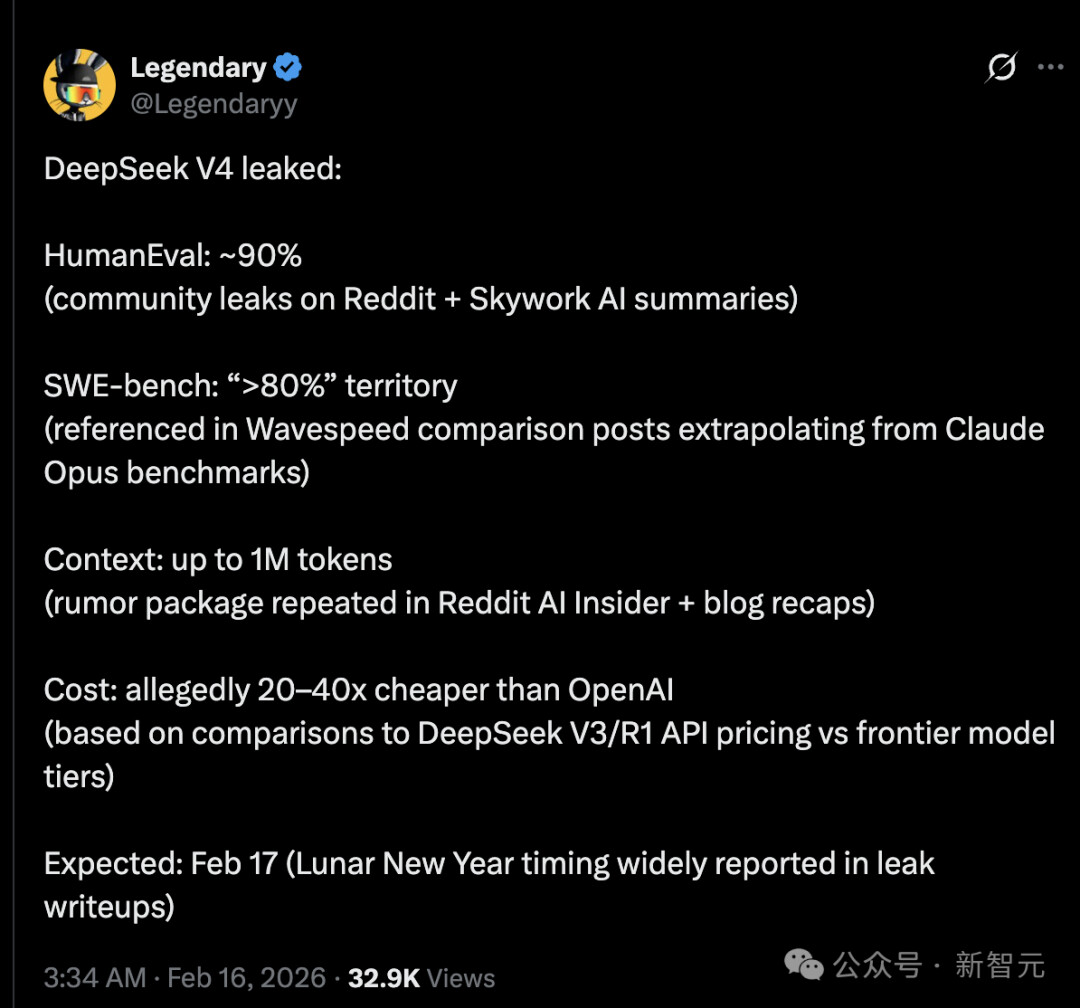
更令人关注的是其 “性价比杀手锏”:传闻 API 成本比 OpenAI 便宜 20-40 倍,结合 100 万 token 超长上下文,可支持全仓库级代码推理,让企业级开发无需为长文本处理和高成本发愁。按泄露信息,模型预计 2 月 17 日(春节期间)发布,将成为首个能与闭源顶尖模型匹敌的开源产品。
数据遭连环打假:真实性存疑,发布时间或推迟
就在行业为 “开源逆袭” 欢呼时,泄露数据很快被多方质疑,多个关键信息被证实存在漏洞:
-
分数逻辑矛盾:AIME 2026 官方评分系统中,最高分仅为 120/120(100%)或 119/120(99.2%),99.4% 的得分根本不可能存在,直接证明相关图表不可靠;
-
数据集权限造假:Epoch AI 官方澄清,FrontierMath 数据集仅 OpenAI 和自身可访问,从未对 DeepSeek V4 做过评估,相关分数系伪造;
-
发布时间冲突:有消息称 DeepSeek 新模型已推迟至 3 月底发布,当前泄露的基准测试若基于内部原始版本,而非最终定型权重,参考价值有限;
-
缺乏关键细节:行业普遍认为,大模型基准测试的核心是 “可复现性”,但泄露数据未提供 pass@k 报告、工具栈配置、污染检查、失败案例分解等关键信息,仅靠 “标题数字” 难以服众。
不过网友也调侃,“虚假泄露” 恰恰证明 DeepSeek “深得人心”—— 只有真正成功的企业,才会成为被伪造测试数据的对象,侧面反映其在开源领域的高口碑。
实锤亮点:100 万上下文灰度测试,技术突破有迹可循
尽管基准数据存疑,但 DeepSeek 的技术进展并非空穴来风,其网页和移动端 APP 已悄然开启新模型灰度测试,100 万 token 超长上下文功能得到官方间接证实:
-
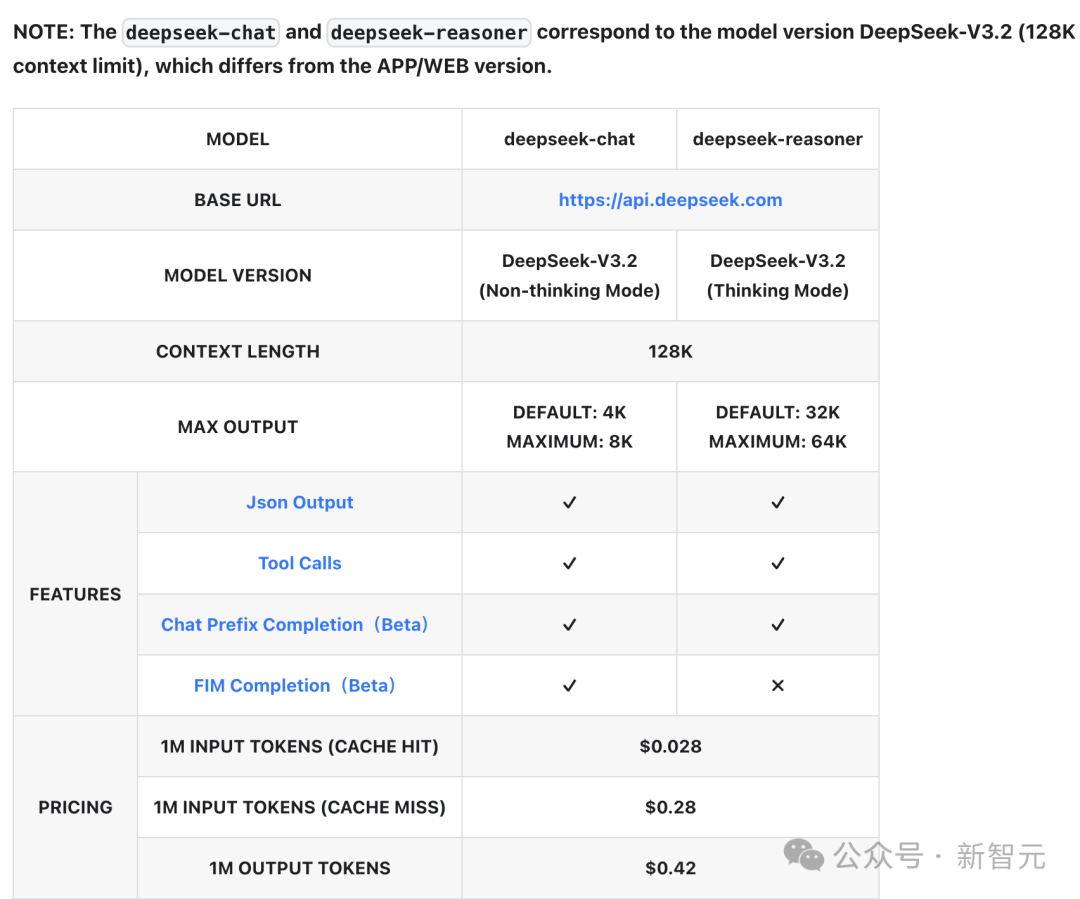
超长上下文落地:DeepSeek 小助手明确回应,网页 / APP 正在测试 “支持 1M 上下文的长文本模型结构”,可一次性处理《三体》三部曲体量的文本,仅 API 服务仍保持 V3.2 的 128K 上下文限制;
-
架构创新持续输出:V3.2 版本后,DeepSeek 团队密集发布核心技术成果,为 V4 奠定基础:
-
流形约束超连接(mHC):解决超深网络训练的梯度消失 / 爆炸问题,支持数百层甚至上千层网络稳定训练;
-
Engram 条件记忆机制:将静态知识(事实、常识)与动态计算(逻辑推理)解耦,突破 GPU 显存瓶颈,支撑超长上下文检索;
-
增强型稀疏注意力(DSA 2.0):智能筛选 Token,将 “先算后筛” 升级为 “按需计算”,降低长文本处理复杂度;
-
视觉因果流(DeepSeek-OCR 2):动态调整图像 “阅读顺序”,擅长复杂文档、表格处理,跨模态能力提升。
-
此外,Meta 科学家研究发现,DeepSeek 的架构设计(MLA + sigmoid MoE + 共享专家 + DSA + MTP)已成为前沿稀疏专家模型的 “标准配方”,多家顶尖实验室纷纷借鉴其设计思路,证明其技术引领性。
核心看点前瞻:四大突破剑指 “编程之王”
结合泄露信息与官方技术铺垫,DeepSeek V4 的核心竞争力已逐渐清晰,四大突破有望重塑开源模型格局:
-
仓库级编程推理:理解单个文件变化对整个项目的影响,适配大型代码库和复杂分布式系统,解决企业级开发的核心痛点;
-
无衰减长文本处理:100 万上下文不仅是 “长度数字”,更能保持逻辑连贯性,避免传统模型在长文本中 “迷失方向” 的问题;
-
训练稳定性升级:通过 mHC、归一化策略等技术,实现多轮训练中数据模式理解能力不衰减,平衡各项性能,避免 “偏科”;
-
开源开放生态:延续 DeepSeek 一贯的开源传统,以开放权重形式发布,让开发者可本地部署、二次开发,与闭源模型形成差异化竞争。
行业影响:开源与闭源的终极对决即将开启
DeepSeek V4 的传闻与进展,折射出 AI 行业的核心趋势变化:闭源模型垄断顶尖性能的时代正在松动,开源模型通过架构创新、效率优化,正快速缩小与闭源产品的差距。
尽管当前泄露数据存在争议,但不可否认的是,DeepSeek 已通过 V3.2、R1 等版本证明,开源模型完全能以低成本与专有模型竞争。若 V4 能如期实现 “编程能力对标 Claude、成本仅为 1/20”,将彻底改变企业和开发者的选型逻辑 ——CTO 们将迎来 “成本套利” 的绝佳机会,开源模型有望在更多商业场景中取代闭源产品。
无论最终发布时间是 2 月还是 3 月,DeepSeek V4 都已点燃行业对开源模型的期待。正如网友所言,“哪怕只有 100 万上下文这一个实锤亮点,也足以推翻‘LLM 架构探索已收敛’的说法”。开源与闭源的终极对决,才刚刚拉开序幕。