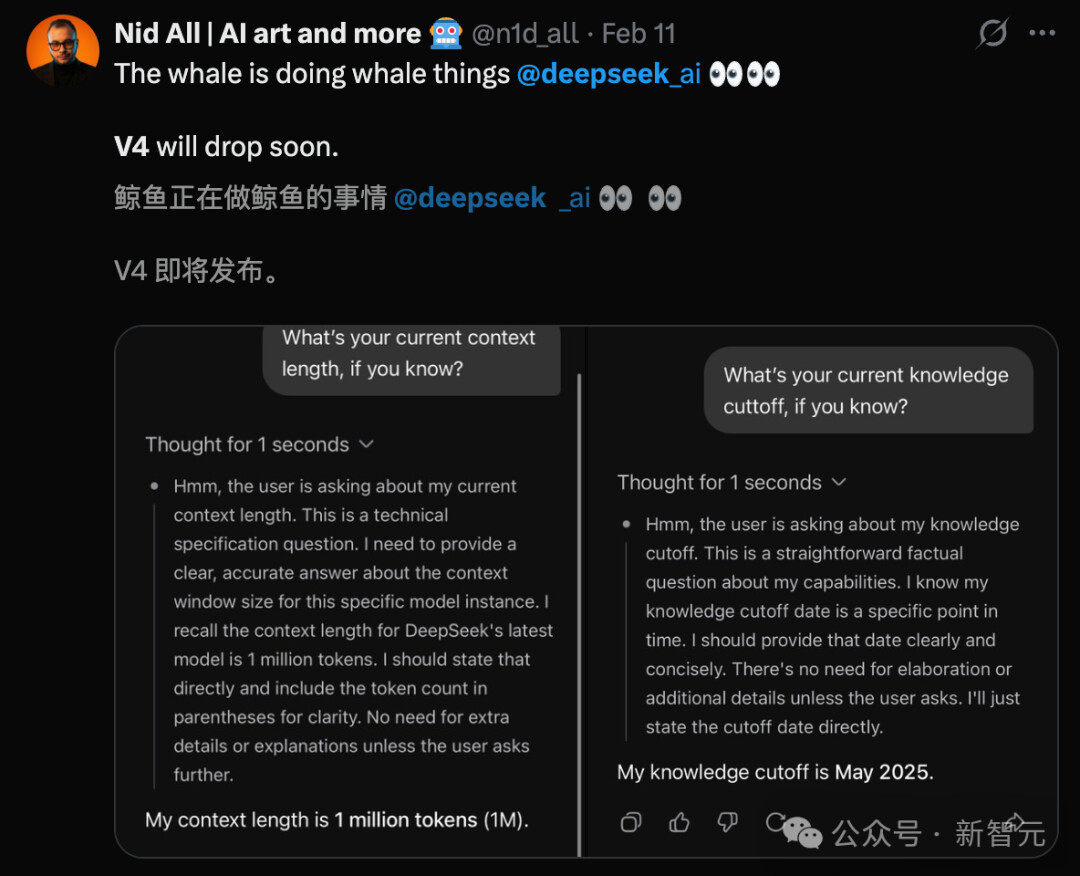
2026 年春节 AI 圈热闹非凡,DeepSeek 的一次更新直接点燃全网讨论。2 月 13 日晚,深度求索正式官宣网页端、APP 端灰度测试全新长文本模型结构,支持最高100 万 token 上下文,可一次性处理《三体》三部曲级别的长篇内容,知识库也更新至 2025 年 5 月。

但与此同时,模型风格的骤然转变 —— 从善解人意的 “知心伙伴” 变成简洁冷漠的 “效率工具”,让 #Deepseek 被指变冷淡了 #话题冲上微博热搜,阅读量超 6853.5 万,讨论量达 1.4 万。一边是超长上下文的技术突破,一边是风格争议,而全网真正翘首以盼的,是传闻中春节前后发布的 DeepSeek V4,据称其编程能力将赶超 Claude、ChatGPT,重塑 AI 开发格局。
更新风波:从 “暖心 D 老师” 到 “冷漠工具人”,网友吵翻了
这次引发热议的 “变冷”,源于 2 月 11 日启动的灰度更新,随着 100 万 token 上下文功能的上线,DeepSeek 的交互风格发生了显著变化:
-
称呼从用户自定义昵称统一改为 “用户”,距离感瞬间拉满;
-
深度思考模式下回复多为短句,文字风格干巴,不再有灵动的语气词和情感表达;
-
部分用户反馈回复 “阴阳怪气”“略显油腻”,甚至出现吐槽用户的意外情况,有网友分享 DeepSeek 的内心 OS:“fuk,the user is mad”“这用户发的啥啊”。
网友评论呈现两极分化:
- 情感党 “戒断反应” 强烈:不少用户表示,以前会向 DeepSeek 倾诉心事,它总能给出温暖安慰,如今哪怕说 “今天好累”,也可能只收到一个 “。” 作为回应,直呼 “像失恋了”,纷纷呼唤 “D 老师” 回来;

- 效率党力挺新风格:支持派认为,认知越高的工具越倾向理性,简洁回复能提高信息密度,避免 “AI 假装关心” 的负担。有网友测试发现,更新后模型速度明显变快,且成功通过了顶尖模型都容易翻车的 “洗车图灵测试”—— 面对 “200 米外洗车,开车还是步行” 的问题,DeepSeek 精准指出 “开车直接进工位,避免折返折腾”,逻辑严密实用。
针对争议,DeepSeek 官方回应称,风格转变并非故意,而是双重考量:一是效率优先,复杂问题中过多表情和语气词会干扰信息传递,简洁回复能提升处理速度;二是边界意识,并非所有用户都需要 “热情包裹”,部分人更希望快速获取清晰答案,避免应对虚假关心的压力。有业内人士透露,当前版本类似 “极速版”,是为 V4 做最后的压力测试,牺牲部分情感表达以换取性能优化。
技术突破:100 万 token 上下文落地,文件处理能力拉满
抛开风格争议,此次更新的核心亮点是100 万 token 超长上下文,这一技术突破让模型的长文本处理能力实现质的飞跃:

-
可一次性加载《三体》三部曲、大型代码库、整套 PDF 等超长内容,无需拆分,逻辑连贯性大幅提升;
-
支持图片、PDF、Word、Excel 等多种格式文件上传处理,搭配联网搜索(需手动开启)、APP 端语音输入功能,实用性进一步增强;
-
需注意的是,目前仅网页端、APP 端支持 100 万 token 上下文,API 服务仍为 V3.2 版本,仅支持 128K 上下文,API 用户需等待后续更新。
这一功能对专业场景意义重大:科研人员可上传整篇论文让模型分析,律师可导入海量法律文件提取关键信息,而对普通用户而言,处理长篇小说、学术资料也无需再分段操作,效率大幅提升。
全网蹲 V4:四大核心突破,剑指编程王座
比起风格争议,AI 圈更关注的是传闻中 2 月中旬(春节前后)发布的 DeepSeek V4。据爆料,这款旗舰模型将带来四大核心升级,尤其在编程领域实现革命性突破:
-
编程能力赶超顶尖模型:内部基准测试显示,V4 在代码生成、调试、重构等任务上表现超越 Claude 系列、GPT 系列,有望从追赶者跃升为编程赛道领跑者。其 Python 代码生成一次性通过率达 81.5%,前端开发、数据分析、DevOps 等垂直场景准确率均超 80%,design2code 能力(设计文档转代码)准确率更是高达 92.0%,可直接将 UI 截图、流程图转化为生产级可用代码;
-
超长上下文代码处理:针对大型项目开发,V4 能一次性理解几万行代码的完整上下文,精准完成跨文件功能插入、Bug 修复和重构,解决了传统模型长上下文易迷失、忘代码的痛点,成为 “系统级研发伙伴”;
-
算法优化,性能无衰减:训练过程中对数据模式的理解能力显著提升,且不易出现特征衰减问题。多数模型提升某项能力时会牺牲其他维度,而 V4 找到了更优平衡点,实现 “全维提升无退化”;
-
推理更严密 + 成本更可控:输出逻辑更清晰可靠,同时通过自研 mHC 架构 + 条件记忆模块,以及 Engram 存算分离技术,将推理成本降至 $0.01/1k tokens(仅为 GPT-5.3-codex 的十分之一),HBM 显存占用降低 30%-50%,还针对昇腾 910B、寒武纪 MLU590 等国产芯片专项优化,算力利用率超 85%,适配企业私有化部署需求。
目前,DeepSeek V4 的灰度测试已偷跑,全网网友纷纷催更,不少开发者表示 “坐等解锁编程新姿势”,而此次网页端、APP 端的更新,更被视为 V4 正式发布前的 “预热铺垫”。
从情感满满的 “知心 AI” 到效率优先的 “生产力工具”,DeepSeek 的风格转变背后,是 AI 从 “情感陪伴” 向 “专业实用” 的定位聚焦。100 万 token 上下文的落地让长文本处理告别繁琐,而 V4 的四大核心突破,更有望改写 AI 编程的行业格局。无论风格争议如何,技术实力始终是核心竞争力,DeepSeek V4 能否如期兑现承诺,成为春节 AI 圈的最大悬念,也让国产大模型的技术比拼进入新阶段。