2026 年,大模型领域的进化方向迎来关键转折。当 arXiv 上顶尖机构的最新论文纷纷聚焦同一个关键词 ——Self-Distillation(自蒸馏),一场关于大模型「持续学习」的技术革命已然拉开序幕。
长期以来,大模型落地的核心瓶颈始终是「持续学习」:如何在吸收新知识、新技能的同时,不丢失已有的核心能力?传统依赖外部强教师的训练范式,不仅成本高昂、数据依赖严重,还难以适配高频的模型迭代需求。而自蒸馏技术的崛起,为这一困境提供了破局之道 —— 通过巧妙的上下文引导或反馈机制,让模型构建出更聪明的「临时自我」,在无需外部教师的情况下实现内生增长,真正走向自主进化。

近期,MIT、ETH Zurich、Meta、斯坦福等顶尖机构组成的学术圈,密集发布三项重磅研究成果,从不同维度验证了自蒸馏技术的巨大潜力,共同将大模型带入持续学习的全新阶段。
一、SDFT:破解「灾难性遗忘」,实现技能持续累积
传统监督微调(SFT)的致命缺陷的是「灾难性遗忘」—— 教模型学习新技能时,其原有代码能力、常识推理等核心能力会急剧退化,成为持续学习的最大障碍。
针对这一问题,MIT 等机构提出自蒸馏微调(SDFT) 方法,将持续学习转化为策略内对齐问题,从根源上解决遗忘难题。
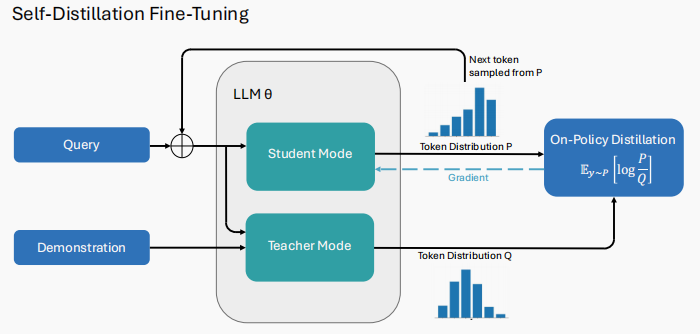
核心机制:利用自身 ICL 潜力,实现自我引导学习
SDFT 的核心逻辑是「以己为师」,充分挖掘预训练模型的上下文学习(ICL)潜力:
-
构造演示上下文:学习新知识时,先构建包含少量专家演示(Few-shot)的输入上下文,诱导模型生成高质量的「教师分布」(即模型在有演示时的最优输出分布);
-
自蒸馏拟合:移除演示上下文后,让模型通过自蒸馏技术,拟合自身生成的教师分布,训练信号完全源于模型自身的 ICL 状态。
技术突破:保持概率流稳定,避免参数剧烈漂移
由于训练信号来自模型内部而非外部数据,SDFT 能最大限度保持模型原始的概率流分布,避免参数在微调过程中出现剧烈漂移。实验数据显示,在工具使用、科学问答、医疗知识等多任务顺序学习中,SDFT 不仅新任务准确率显著高于传统 SFT,还能有效保留原有技能,实现单一模型随时间累积多种能力而不退化,证明了同策略蒸馏是持续学习的实用路径。
二、SDPO:富反馈驱动,打破强化学习的奖励僵局
传统强化学习(如 GRPO)依赖二值反馈(奖励 0 或 1),信息密度极低,在长程推理任务中会出现严重的「信用分配问题」—— 无法精准定位错误环节;更致命的是,若模型尝试全失败(奖励均为 0),学习信号会完全消失,导致进化停滞。
ETH Zurich 等团队提出的自蒸馏策略优化(SDPO) 框架,通过「富反馈 + 自蒸馏」,将模糊奖励转化为精准监督信号,彻底打破这一僵局。
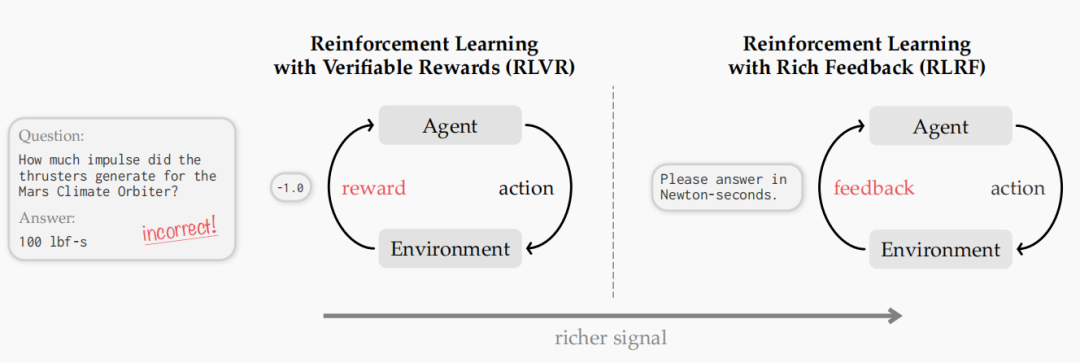
核心机制:内生自省教师,挖掘富反馈价值
SDPO 的关键创新是引入「富反馈(Rich Feedback)环境」,让模型在错误中实现自我校准:
-
富反馈获取:当模型生成错误答案时,环境不仅返回「错误」判定,还会提供具体报错信息(如逻辑漏洞、计算错误等);
-
自省教师构建:模型将报错信息重新注入上下文,化身「自省教师」,重新审视并校准之前的错误尝试;
-
Token 级信号转化:通过自蒸馏对比「反馈后分布」与「初始分布」的差异,将模糊的标量奖励转化为 Token 级的密集监督信号,精准定位导致失败的关键 Token。
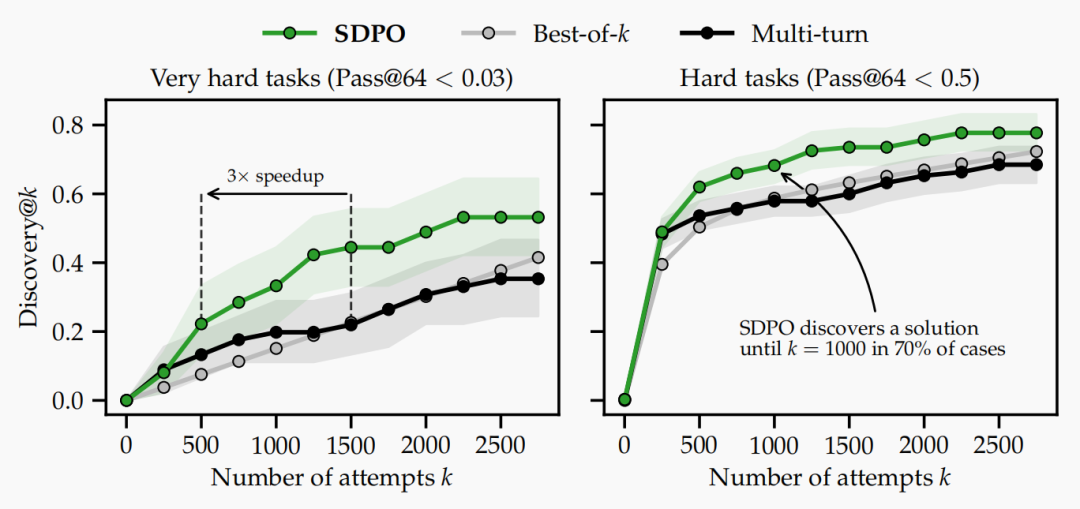
技术突破:采样效率飙升,难题解决率翻倍
SDPO 的优势在极难任务中尤为显著:
-
采样效率提升 3 倍:仅需传统算法 1/3 的尝试次数,就能达到同等解发现率;
-
收敛速度更快:k=1000 时可解决 70% 的极难任务,远超传统算法;
-
数据利用率更高:在 LiveCodeBench 等编程测试中,仅需 GRPO 算法 1/4 的生成样本量,就能达到同等精度,彻底打破标量奖励带来的进化僵局。
三、OPSD:策略内自博弈,挖掘深层推理潜力
复杂推理任务中,大模型面临搜索空间过大、奖励信号稀疏的难题,没有外部强教师辅助时,很难找到正确的深层逻辑路径。
斯坦福等机构提出的策略内自蒸馏(OPSD) 框架,通过在模型内部构建「信息不对称」,诱导自我博弈,挖掘内在推理潜力。
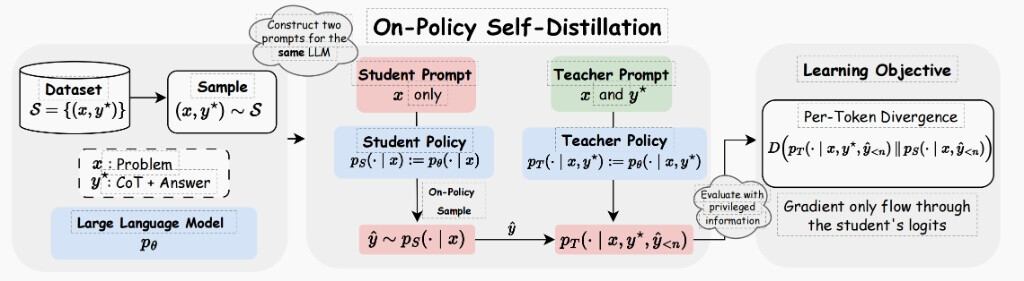
核心机制:双策略对比,强制深度逻辑学习
OPSD 将同一模型配置为「教师」和「学生」两种策略,通过分布对齐实现推理能力提升:
-
教师策略:输入中包含「特权信息」(如标准答案、验证过的推理轨迹),能产生高质量的 Token 概率分布;
-
学生策略:仅输入题目,不接触任何特权信息,仅凭自身推理作答;
-
策略内对齐:采用策略内(On-Policy)采样,训练目标是最小化学生分布与教师分布的 KL 散度,强制学生在无外部参考的情况下,学会从题目到答案的深层逻辑推导。
技术突破:Token 利用率提升 4-8 倍,推理能力飞跃
在 MATH、GSM8K 等高难度数学推理基准测试中,OPSD 展现出极高的学习效率:
-
Token 利用率远超传统 GRPO 算法,达到 4-8 倍;
-
推理精度更优:在相同训练步数和 Token 量下,OPSD 的平均准确率显著高于 GRPO;
-
挖掘内生潜力:实验证明,SFT 仅能为推理提供初始方向,而 OPSD 能进一步激活模型内在的推理潜力,成为复杂任务能力飞跃的捷径。
总结:自蒸馏成后训练标准配置,大模型迈入自主进化时代
三项研究虽聚焦不同场景,但核心逻辑高度一致:利用模型内生能力,通过上下文构造「信息差」,实现自驱动闭环升级。SDFT 解决持续学习的遗忘问题,SDPO 突破强化学习的奖励瓶颈,OPSD 挖掘复杂推理的内在潜力,共同验证了自蒸馏技术的普适性与强大能力。
2026 年,自蒸馏正成为大模型后训练阶段的标准配置,标志着大模型发展从「依赖外部数据与教师」走向「自主进化」。未来,我们或许不再需要费力「教」模型变强,只需为其提供持续学习的机制与环境,模型就能通过自我博弈、自我校准,不断突破能力边界。