“想用水 AI 处理敏感文档,又怕云端泄露隐私?”“没网的时候,就只能和 AI 断联?” 别担心!今天就给大家带来终极解决方案 —— 用 Ollama 工具在本地部署 DeepSeek 大模型,让你的电脑变身专属算力中心,数据全程不出本机,断网也能自由对话,还完全免费!
不管你是 Windows、Mac 还是 Linux 用户,跟着这份保姆级教程操作,零基础也能轻松上手,从此拥有安全又好用的私人 AI 助手~
一、先搞懂:Ollama 为啥是本地部署神器?
如果把 DeepSeek 这类大模型比作 “智能软件”,那 Ollama 就是简化一切操作的 “万能启动器”,像 Steam 一样好用。
以前本地部署大模型,要手动配置 Python 环境、安装一堆依赖、修改复杂代码,光步骤就劝退 99% 的人。而 Ollama 把所有复杂流程打包,一键就能完成部署,核心优势更是戳中痛点:
-
 绝对隐私:数据全程在本地运行,不上传任何云端服务器,日记、公司机密文档随便扔,完全不用担心泄露;
绝对隐私:数据全程在本地运行,不上传任何云端服务器,日记、公司机密文档随便扔,完全不用担心泄露; -
 完全免费:不用买 Token、不用充会员,只消耗少量电费,长期使用成本几乎为零;
完全免费:不用买 Token、不用充会员,只消耗少量电费,长期使用成本几乎为零; -
 低延迟响应:无需等待网络传输,AI 生成速度全看电脑配置,日常对话几乎无卡顿;
低延迟响应:无需等待网络传输,AI 生成速度全看电脑配置,日常对话几乎无卡顿; -
 多端适配:Windows、Mac、Linux 系统全支持,普通电脑也能跑,门槛极低。
多端适配:Windows、Mac、Linux 系统全支持,普通电脑也能跑,门槛极低。
二、部署前准备:你的电脑能跑哪个版本?
本地部署的核心限制是内存和显存,大家可根据自己的电脑配置选择对应参数的 DeepSeek-R1 模型(模型参数越小,对配置要求越低):
表格
| 电脑配置级别 | 推荐模型参数 | 核心特点 | 适用场景 |
|---|---|---|---|
| 入门级(8G 内存) | 1.5B/3B | 体积小(1.1GB 起)、速度快,无独立显卡也能跑 | 日常聊天、简单文本总结 |
| 主流级(16G 内存 + 独立显卡) | 7B/8B | 性能均衡,聪明程度媲美 GPT-3.5,是最受欢迎的 “黄金尺寸” | 代码生成、数学推理、长文本理解(16K 上下文窗口) |
| 发烧级(32G 内存 + RTX 5080/5090 显卡) | 14B/32B/70B | 专业级性能,支持复杂任务和高精度推理 | 企业知识库接入、专业领域深度问答 |
Tips:如果运行时电脑卡顿、风扇狂转,说明模型参数选大了,换成更小版本即可~
三、实操步骤:3 步搞定部署,小白也能会
第一步:安装 Ollama,全程一键操作
-
下载安装包:打开 Ollama 官网(ollama.com),点击中间的 “Download” 按钮,根据自己的系统选择对应版本(Windows 需 Windows 10 及以上,Mac 需 Ventura 13.4+);
-
快速安装:下载完成后,双击安装包,一路点击 “Next”(下一步),无需额外配置,安装程序会自动完成所有操作;
-
验证安装:安装成功后,Ollama 会在后台静默运行,Windows 用户可在右下角任务栏看到羊驼图标,Mac 用户可在菜单栏找到,这就说明安装成功啦;
-
可选优化:修改模型下载路径(避免占满系统盘)
-
Windows 用户:桌面找到 “此电脑”→右键 “属性”→“高级系统设置”→“环境变量”→系统变量栏 “新建”;
-
变量名输入 “OLLAMA_MODELS”,变量值输入自定义路径(如 “E:\LLM_Model”);
-
重启 Ollama(右键任务栏羊驼图标选择重启),配置才会生效。
-
第二步:下载 DeepSeek 模型,一行命令搞定
Ollama 本身只是 “启动器”,现在要给它装上 “灵魂”——DeepSeek 模型:
-
打开终端:
-
Windows 用户:按 Win+R,输入 “cmd” 回车,打开命令提示符;
-
Mac/Linux 用户:直接打开 “终端” App;
-
-
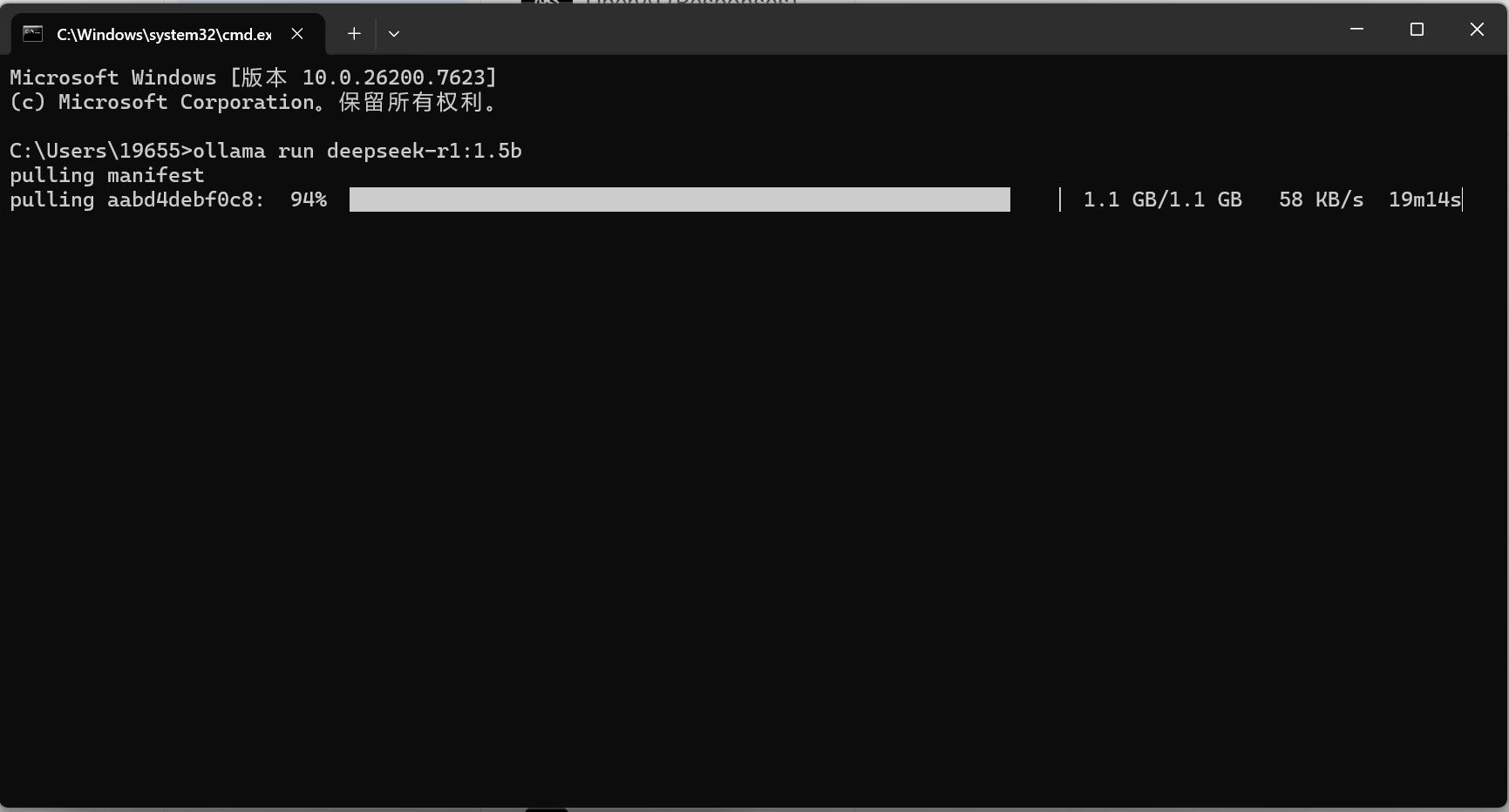
输入下载命令:复制对应模型的命令,粘贴到终端后回车(以 7B 版本为例):
plaintext
ollama run deepseek-r1:7b -
国内用户若下载速度慢,可添加镜像源加速(命令如下):
plaintext
ollama run deepseek-r1:7b --registry-mirror https://mirror.xyz.com/ollama -
等待下载:终端会显示进度条,下载完成后会自动验证并加载模型,最终出现 “>>>” 符号,就说明模型已经成功运行,现在可以直接在终端输入问题对话啦(比如输入 “你好,介绍一下自己”)。
第三步:配置可视化界面,告别黑框框
命令行窗口不够直观?给模型配个美观的可视化界面,操作更方便,推荐用 Cherry Studio 或 Chatbox,这里以 Cherry Studio 为例:
-
下载安装:打开 Cherry Studio 官网,下载对应系统版本,一键安装;
-
连接 Ollama:
-
打开 Cherry Studio,点击左下角 “设置”→找到 “模型服务”→选择 “Ollama”;
-
API 域名默认即可,若连接失败,手动输入 “http://127.0.0.1:11434/v1”;
-
确保 Ollama 在后台运行(任务栏有羊驼图标),点击 “管理” 或 “检查更新”,软件会自动识别已下载的 DeepSeek 模型;
-
-
开始使用:回到聊天界面,切换模型为 “deepseek-r1:7b”(或你下载的版本),就能像用普通聊天软件一样和本地 AI 对话啦!
四、进阶技巧:让本地 AI 更好用
-
外接知识库:把 PDF、Excel、Markdown 等格式的文档导入,让 AI 基于你的专属数据回答问题(需配合 Open WebUI 等工具,后续会单独出教程);
-
性能优化:有独立显卡的用户,可在启动命令中添加参数加速:
plaintext
ollama run deepseek-r1:14b --num_gpu 2 --flash_attention on -
安全加固:仅本地使用时,限制网络访问避免风险,Windows 用户可通过防火墙屏蔽 11434 端口外部访问。
五、常见问题排查:遇到问题不用慌
表格
| 问题现象 | 解决方法 |
|---|---|
| 模型下载卡在 99% | Ctrl+C 取消下载,重新运行下载命令,进度会保留并继续 |
| 终端提示 CUDA 错误 | 检查显卡驱动是否更新,重装 CUDA 12.3 工具包 |
| 可视化界面无法识别模型 | 重启 Ollama 和可视化软件,确保 API 地址填写正确 |
| 生成内容卡顿 / 不连贯 | 换成更小参数模型,关闭后台无关程序释放内存 |
| 想删除无用模型 | 终端输入命令:ollama rm 模型名(如 “ollama rm deepseek-r1:1.5b”) |
写在最后
通过 Ollama 部署本地 DeepSeek,不仅解决了隐私泄露的顾虑,还能免费享受 AI 的强大能力 —— 处理敏感文档、日常对话、代码辅助,断网也不耽误。这就是开源技术的魅力,让每个人都能轻松拥有属于自己的智能助手。
按照教程操作,你也能快速 get 私人 AI!如果想进一步学习如何给本地 AI 接入专属知识库,或者搭建本地智能体,欢迎点赞收藏,后续会带来更多进阶教程~