2026 年 AI 领域再添重磅评测基准!腾讯混元团队与复旦大学联合推出专注于 “上下文学习(Context Learning)” 的评测基准 CL-bench,刚加入腾讯不久的首席 AI 科学家姚顺雨(Shunyu Yao)深度参与其中,提供了全面细致的审阅与反馈,极大提升了这项工作的质量。这款基准首次聚焦模型 “现学现卖” 的核心能力,直击现有评测痛点,却让 GPT 5.1、Claude Opus 4.5 等 10 款前沿模型集体折戟,揭示了下一代大模型的关键能力瓶颈。

CL-bench 已全面开源,可通过以下渠道获取:
-
Hugging Face 数据集:https://huggingface.co/datasets/tencent/CL-bench
一、CL-bench:直击行业痛点,定义 “现学现卖” 新评测
现有大模型评测多存在明显局限:静态知识问答(如 MMLU、C-Eval)依赖模型预训练 “老本”,长文档理解(如 LongBench)侧重 “找答案” 而非 “学知识”,而上下文学习(ICL)仅能让模型掌握格式而非新知。CL-bench 的核心创新,是首次将 “从复杂上下文中学新知识并解决问题” 作为独立评测维度,打造了一场 “闭卷速读 + 现场实操” 的残酷考试。
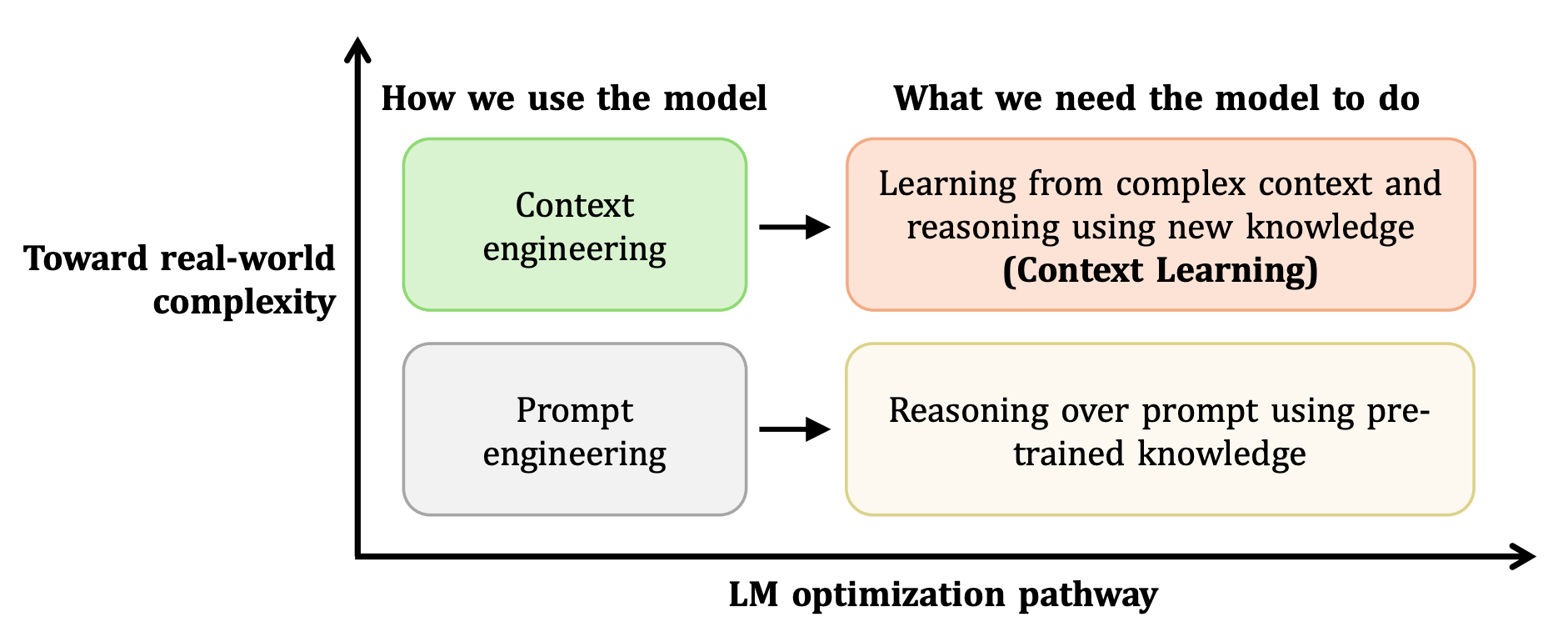
核心设计原则:完全自包含,拒绝 “偷懒”
CL-bench 的所有任务都遵循 “自包含(Self-contained)” 原则 —— 解决任务所需的全部信息均明确包含在上下文之中,无需外部检索,也不允许模型依赖预训练知识。上下文最长达 65k tokens,涵盖虚构法系、新编程语言、实验流程、观测数据等复杂内容,模型若想 “偷懒” 套用旧知识,任务通过率低于 1%,彻底杜绝 “伪理解”。
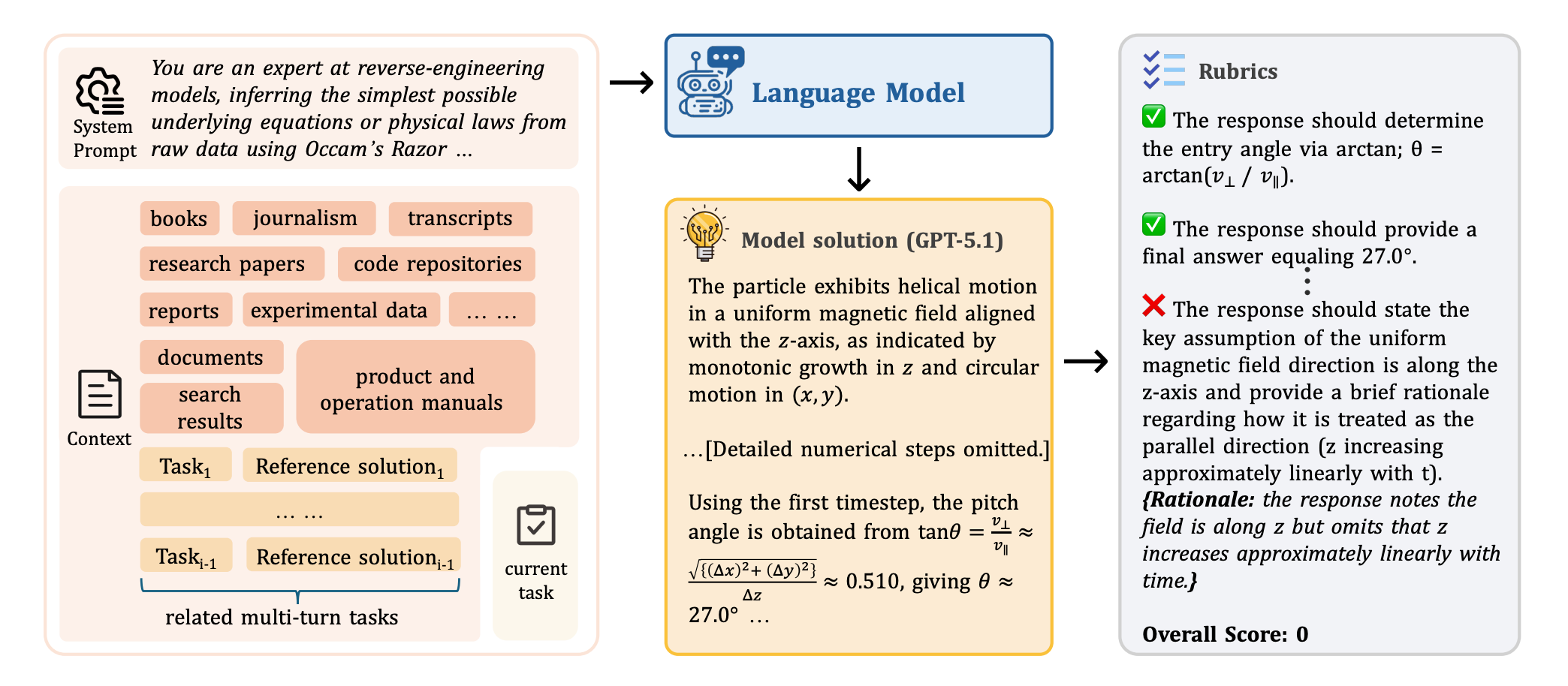
四大题型 + 18 个子类:覆盖真实世界复杂场景
CL-bench 包含 500 个上下文、1899 个任务和 31607 条细项评分标准,平均输入长度达 10.4k tokens,题型覆盖四大核心场景,全面考验模型的新知识学习与应用能力:
表格
| 一级类别 | 二级示例 | 核心能力 | 任务场景 |
|---|---|---|---|
| 领域知识推理(Domain Knowledge) | 虚构法律、小众金融、冷门医学 | 快速吸收领域新知,化身 “临时专家” | 基于《2025 客户数据法案》为客户制定维权方案 |
| 规则系统应用(Rule System) | 新编程语言、桌游规则、数学公理 | 掌握陌生规则,即时落地应用 | 按全新语言规范编写定时打印程序 |
| 流程任务执行(Procedural Task) | 产品手册、实验流程、运维 SOP | 精准遵循步骤,零差错完成操作 | 解读 Vex 框架文档,运行指定代码并输出结果 |
| 实证发现与模拟(Empirical Discovery) | 观测数据、沙盒模拟、实验结果 | 从数据中归纳规律,完成模拟预测 | 基于供应链模拟参数,预测金属可持续年产量 |

评分机制:“全或无” 的严格标准
为杜绝 “差不多” 的模糊输出,CL-bench 采用二进制评分规则:每道题配套 10-20 条细项评分标准(涵盖格式、事实、计算、逻辑等),只有全部满足才能得 1 分,只要有 1 条未达标则得 0 分。评分过程由 LM-as-Judge 自动执行,需经过标准分析、逐条校验、自我反思三大步骤,确保客观严格。
二、实测震撼:10 大前沿模型集体折戟,平均通过率仅 17.2%
研究团队对 10 款全球前沿大模型进行了全量评测,结果令人意外 —— 即便是表现最佳的模型,整体通过率也不足 25%,平均通过率仅 17.2%,暴露了大模型在 “现学现卖” 能力上的严重短板。
模型排名:GPT 5.1 夺冠,腾讯混元跻身前十
表格
| 排名 | 模型名称 | 整体通过率 | 领域知识推理 | 规则系统应用 | 流程任务执行 | 实证发现与模拟 |
|---|---|---|---|---|---|---|
| 1 | GPT 5.1 (High) | 23.7%±0.5 | 25.3%±1.3 | 23.7%±1.3 | 23.8%±1.4 | 18.1%±3.1 |
| 2 | GPT 5.1 | 21.1%±0.2 | - | - | - | - |
| 3 | Claude Opus 4.5 Thinking | 21.1%±1.4 | 23.7%±1.2 | 19.0%±1.5 | 22.6%±1.5 | 15.1%±2.3 |
| 4 | Claude Opus 4.5 | 19.1%±0.4 | - | - | - | - |
| 5 | GPT 5.2 | 18.2%±0.5 | - | - | - | - |
| 6 | GPT 5.2 (High) | 18.1%±0.8 | 18.6%±0.9 | 17.2%±1.3 | 21.4%±1.1 | 11.7%±1.8 |
| 7 | o3 (High) | 17.8%±0.2 | 18.0%±1.4 | 17.6%±1.1 | 19.5%±0.4 | 13.7%±0.8 |
| 8 | Kimi K2 Thinking | 17.6%±0.6 | 18.7%±0.6 | 17.0%±1.5 | 18.8%±0.7 | 12.6%±4.0 |
| 9 | 腾讯混元 HY 2.0 Thinking | 17.2%±0.6 | 18.0%±1.0 | 17.3%±0.5 | 19.4%±1.1 | 8.9%±0.3 |
| 10 | Gemini 3 Pro (High) | 15.8%±0.3 | 15.5%±1.1 | 17.7%±1.7 | 16.4%±1.6 | 10.1%±3.1 |
三大关键发现:模型能力瓶颈浮出水面
-
归纳能力远逊演绎:需要从数据中总结规律的 “实证发现与模拟” 类任务平均通过率仅 11.8%,比其他三类低 6 个百分点,成为模型的最大短板;
-
长文本是 “致命杀手”:当上下文长度超过 32k tokens,所有模型的得分直接腰斩,长文本理解与知识吸收能力严重不足;
-
高推理档位并非万能:GPT 5.2 将推理档位从 “low” 提升至 “high” 后,通过率反而下降 5.6%,暴露了长链逻辑与指令跟随的失衡问题。
三、错误画像:模型都在怎么 “偷懒”?
评测还揭示了模型在上下文学习中的三大核心错误类型,其中 “误用上下文” 最为普遍:
-
上下文误用(Context Misused):占比 60%,模型虽引用了上下文信息,但错误套用规则、参数或逻辑,比如混淆新编程语言的语法规范;
-
上下文忽略(Context Ignored):占比 30%,模型完全无视上下文新知,用预训练知识作答,例如将虚构法律当作现实法律提供解决方案;
-
格式错误(Format Error):占比 35%,未满足输出格式要求,如 JSON 缺失字段、顺序错乱等,其中豆包 1.6 的格式错误率高达 45.8%。
不同模型的错误分布各有差异:DeepSeek V3.2 和豆包 1.6 的 “上下文忽略” 错误率最高(均超 66%),Claude Opus 4.5 Thinking 的 “上下文误用” 错误率达 66%,整体来看,没有任何模型能有效规避三类核心错误。
四、行业意义:倒逼大模型向 “快速上手新业务” 进化
CL-bench 的推出,不仅填补了现有评测的空白,更精准指出了大模型落地真实世界的关键障碍 —— 在企业办公、专业咨询、技术研发等场景中,人们往往需要快速学习陌生领域知识并解决问题,而当前大模型的 “现学现卖” 能力显然无法满足需求。
姚顺雨此前在 AGI-Next 前沿峰会上就强调,“做应用不仅需要强大的模型能力,还需要较长上下文与高效的新知识学习能力”。CL-bench 的落地,正是对这一理念的实践,它为大模型优化提供了明确方向:未来模型不仅要提升长文本理解能力,更要强化知识归纳、规则应用的精准度,才能真正成为 “10 分钟上手新业务” 的超级助手。
对于 AI 行业而言,这款基准的开源将推动更多团队聚焦上下文学习能力突破,加速大模型从 “记忆高手” 向 “学习高手” 转型。而腾讯混元与复旦大学的联合探索,也为产学研协同创新提供了优秀范本。