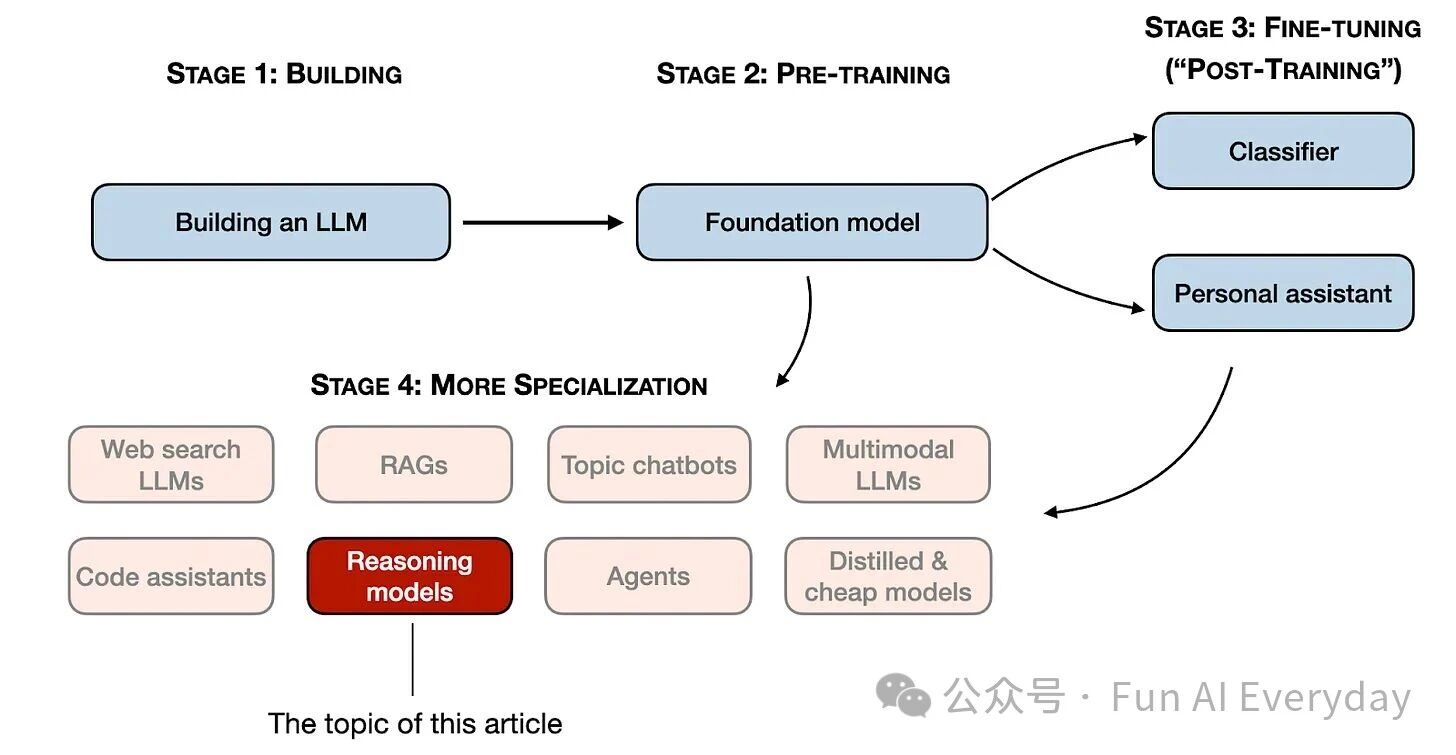
2024 年后,大模型赛道彻底告别 “通吃所有任务” 的粗放时代,进入精准分工的精细化竞争阶段。有的专攻多模态,有的聚焦 RAG 与智能体落地,而推理模型作为其中最具技术门槛的分支,正成为复杂任务场景的核心竞争力。它能搞定数学证明、高难代码、复杂决策等多步推导任务,但 “更强” 的背后,也伴随着 “更贵、更慢” 的现实困境 —— 用对场景如虎添翼,用错则可能 “过度思考” 翻车。今天就以 DeepSeek R1 为样本,拆解推理模型的核心逻辑与应用门道。
一、先搞懂:推理模型到底 “特别” 在哪?
推理模型的核心优势,不是 “更聪明”,而是 “更会拆解复杂问题”。
-
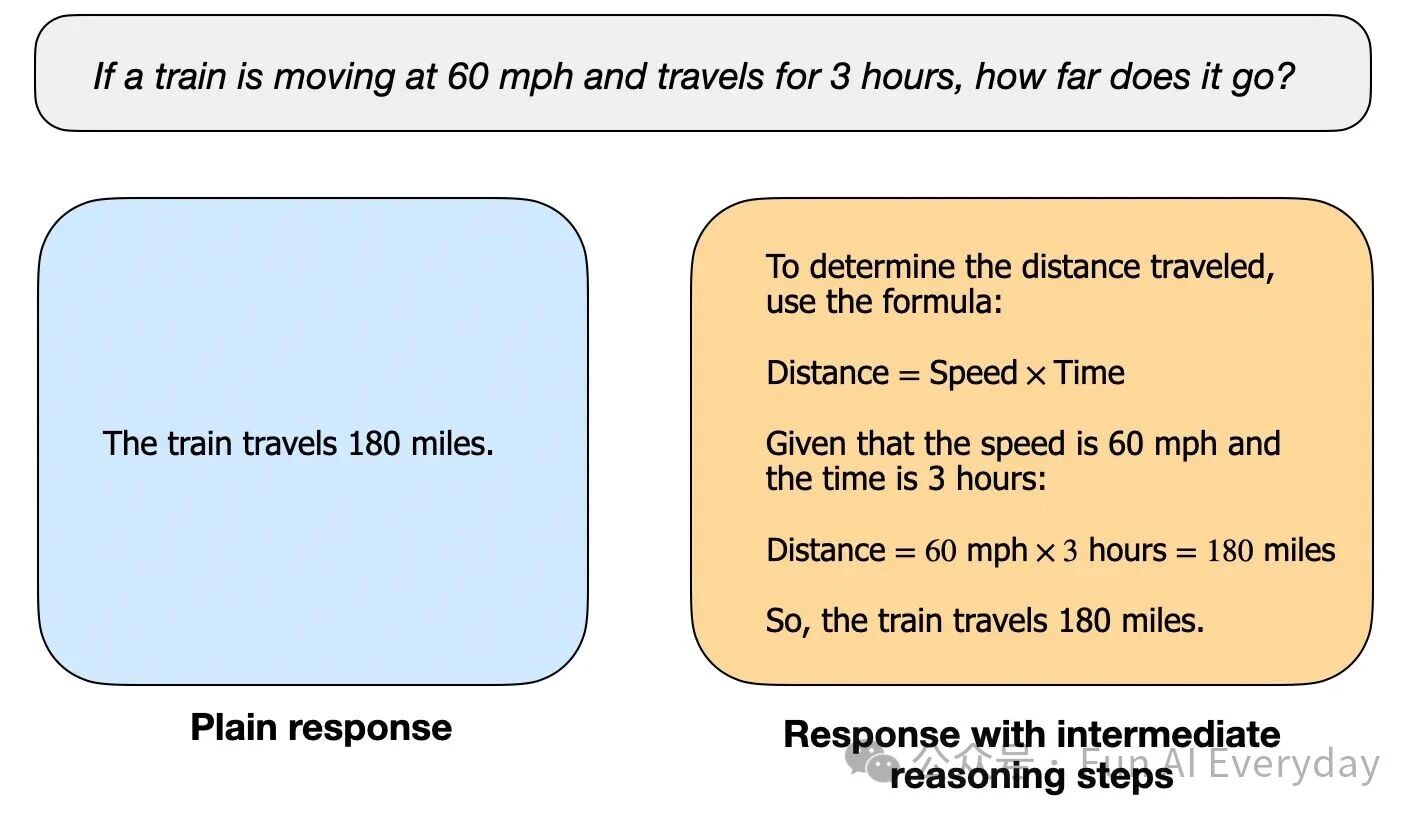
普通模型面对问题更像 “直接作答”:比如问 “法国首都是哪”,直接调用记忆给出答案,本质是检索行为;
-
推理模型则像 “分步解题”:遇到 “火车每小时 60 英里,开 3 小时走多远” 这类问题,会先识别 “路程 = 速度 × 时间” 的逻辑关系,再代入计算得出结果,全程包含 “拆解 - 验证 - 推导” 的完整链路。
这类模型的核心能力集中在:
-
复杂逻辑任务:谜题、数学证明、高难代码开发等需要多步推导的场景;
-
复杂决策任务:需综合多个条件权衡利弊的选择类问题;
-
泛化创新任务:面对未见过的新问题时,能举一反三迁移能力。
而推理步骤的呈现方式分两种:一是显式推导,把中间思考过程完整展示;二是隐式推导,内部多轮尝试后只输出最终答案。
二、避坑指南:推理模型的 “优与劣” 清单
优势明确:复杂场景的 “稳压器”
-
多步推导不跑偏:能把复杂任务拆分成小步骤,逐步验证推进,减少中途出错概率;
-
泛化能力更强:面对陌生问题时,比普通模型更能找到解题思路;
-
结果可解释:部分模型会输出推理链,便于验证逻辑正确性,适合对可靠性要求高的场景。
劣势突出:这些场景千万别用
-
速度慢:多步推导或内部尝试会消耗更多时间,响应效率远低于普通模型;
-
成本高:推理过程生成更多 Token,算力消耗翻倍,使用成本更高;
-
知识问答不占优:纯记忆类问题(如 “地球半径多少”)表现未必比普通模型好,甚至可能 “编得更逼真”;
-
简单问题过度思考:明明一句话能回答的问题,可能绕圈推导,反而出错。
结论很明确:仅当问题需要多步推理、逻辑验证时,才值得用推理模型;纯知识问答、简单指令类任务,优先选普通模型更省更快。
三、DeepSeek R1 拆解:推理模型的 “三级进化” 之路
要搞懂推理模型怎么练出来,DeepSeek R1 的 “三版本迭代路线” 堪称教科书级样本 —— 从实验性验证到产品级落地,再到低成本普及,每一步都踩准了行业痛点。
1. R1-Zero:纯强化学习,逼出推理行为
这是一次极具研究价值的实验:在 DeepSeek-V3(671B 参数)底座上,跳过传统 “先 SFT 再强化学习” 的路径,直接用强化学习训练。
核心关键是 “精准奖励机制”:
-
准确性奖励:代码题用编译器验证、数学题用规则系统判断,确保结果正确;
-
格式奖励:用 “评委模型” 检查输出是否符合指定格式(如推理步骤标签化)。
这个版本的意义在于证明:即使不提前教模型 “怎么推理”,纯强化学习也能让推理行为 “自然涌现”。但它更偏向实验验证,离稳定可用的产品级能力还有距离。
2. R1 主力版:SFT+RL 组合拳,打造强推理标杆
真正支撑起产品竞争力的,是 “监督微调(SFT)+ 强化学习(RL)” 的组合策略,可理解为 “先铺路,再跑顺”:
-
冷启动:用 R1-Zero 生成首批推理样本,解决初始训练数据不足的问题;
-
首轮 SFT:用冷启动数据校准模型的 “回答格式” 和 “基本推理逻辑”,打好基础;
-
首轮 RL:加入准确性、格式、一致性(避免中英夹杂)三重奖励,重点提升难题破解能力;
-
二次 SFT:扩充 80 万条高质量样本(60 万条推理链 + 20 万条知识型),平衡推理能力与知识问答表现;
-
二次 RL:聚焦数学、代码等可验证任务,进一步拉稳正确率。
这套流程本质是 “强化版 RLHF”—— 更侧重推理链数据的积累,且依赖客观可验证的奖励反馈,避免主观评分的偏差。
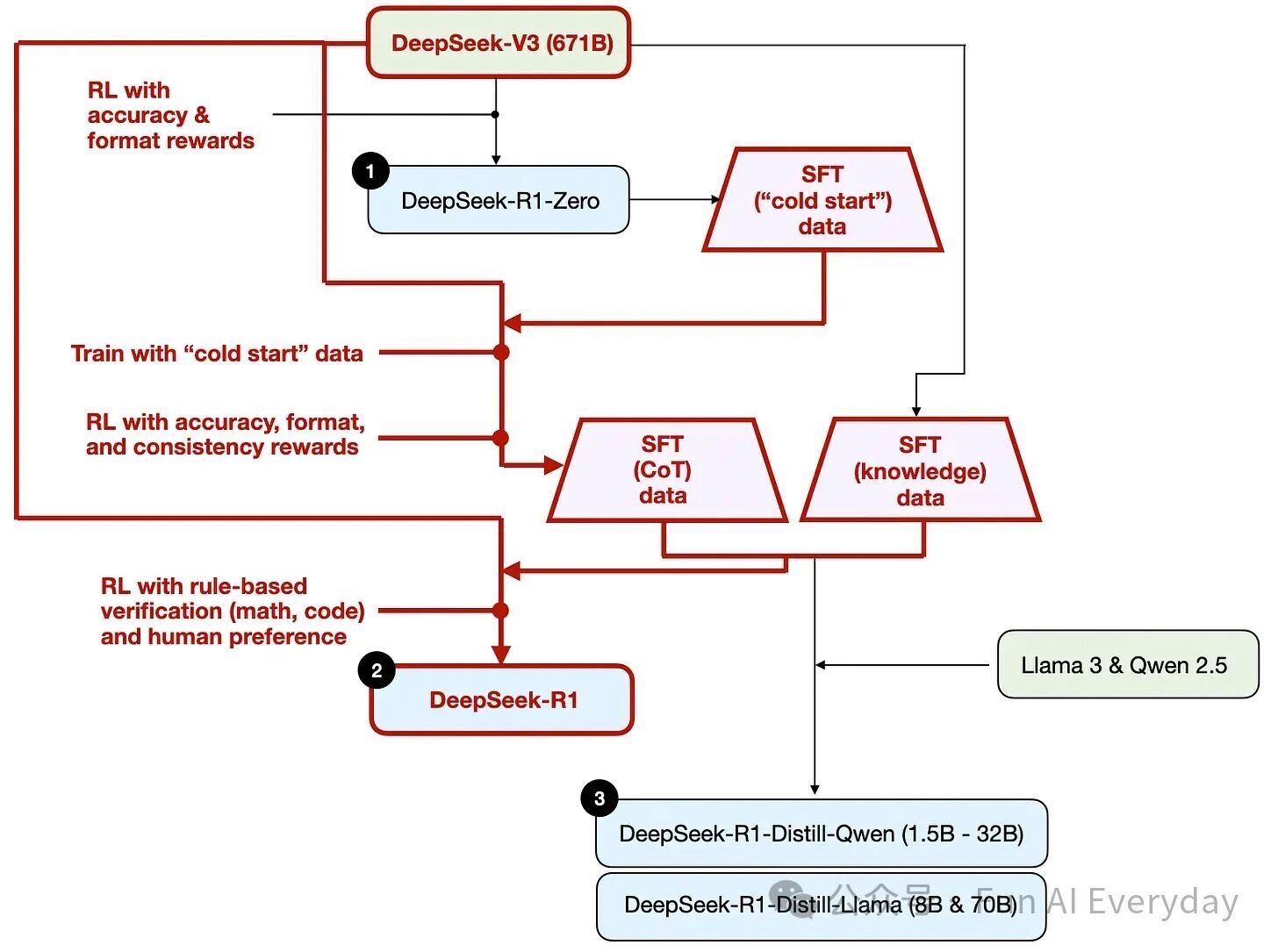
3. R1-Distill:蒸馏小模型,让推理能力 “低成本落地”
主力版虽强,但部署门槛高、成本贵。蒸馏版的核心思路的是 “能力迁移”:
让 DeepSeek R1 主力版生成海量高质量推理样本,再用这些样本微调 Llama、Qwen 等开源小模型,让小模型也具备接近主力版的推理能力。
优势很现实:小模型硬件门槛低、部署成本省,虽整体性能略逊于主力版,但足以覆盖多数应用场景,完美解决推理模型 “好用但用不起” 的痛点。
四、行业通用:推理能力的四条落地路径
从 DeepSeek R1 的实践中,可提炼出行业通用的推理模型构建路径,按需选择即可:
| 路径类型 | 核心逻辑 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 路径 A:推理时多花算力 | 不改模型,通过提示词引导多步推导、多答案投票等方式提升效果 | 零训练成本,快速见效 | 更慢更贵,效果上限有限 | 快速验证场景,无需长期落地 |
| 路径 B:纯强化学习 | 跳过 SFT,直接用强化学习逼出推理行为 | 路线简洁,研究价值高 | 稳定性差,覆盖场景有限 | 学术研究或特定窄场景 |
| 路径 C:SFT+RL | 先通过 SFT 校准基础能力,再用 RL 提升难题性能 | 效果稳、能力强,产品级首选 | 成本高、周期长 | 核心业务场景,追求极致性能 |
| 路径 D:纯 SFT / 蒸馏 | 用强模型生成样本,微调小模型 | 成本低、部署易,性价比高 | 依赖优质样本,难突破上限 | 中小团队落地,低成本需求场景 |
五、实用技巧:3 个提问技巧,让推理模型更听话
-
少给示例:过多示例可能限制模型思路,反而降低泛化能力;
-
明确格式:需要步骤、表格、结论等特定输出时,提前写清格式要求,减少无效输出;
-
单一语言:同一条提示避免中英混用,否则易导致推理逻辑混乱。
推理模型的核心价值,在于攻克普通模型搞不定的复杂场景。而 DeepSeek R1 的成功,不仅在于技术路线的精准,更在于它提供了 “从实验到产品再到普及” 的完整解决方案 —— 既解决了 “怎么变强”,也回应了 “怎么用得起”。未来,推理模型的竞争,终将是 “性能、成本、场景适配” 的综合较量。