开源大模型领域近日掀起一场激烈论战!欧洲 AI 公司 Mistral 联合创始人兼 CEO Arthur Mensch 在近期访谈中,针对中国开源 AI 的崛起发表了一番极具争议的言论:“DeepSeek-V3 及后续版本均基于 Mistral 提出的架构构建,双方采用相同架构,而我们已公开重建该架构所需的全部内容”。这番表态瞬间引爆全球开发者社区,网友纷纷拿出论文时间线、架构细节等 “实锤” 反驳,直言 “这是在改写事实”。作为深耕开源生态的社区,DeepSeek Club 带大家梳理事件来龙去脉,拆解这场争议背后的技术真相与行业思考。
事件缘起:一句 “架构同源” 引发轩然大波
在被问及如何看待中国开源 AI 的强势发展时,Arthur Mensch 先是肯定了中国在 AI 领域的实力,认为开源并非零和竞争,而是 “彼此借鉴、共同进步” 的过程。但随后话锋一转,他明确表示:Mistral 是最早发布开源稀疏混合专家模型(MoE)的公司之一,2024 年初推出相关架构后,DeepSeek-V3 及后续版本便在此基础上构建,双方核心架构完全一致。
这番自信满满的表态,在开发者社区引发强烈反弹。网友们的反应从 “难以置信” 到直接吐槽:“Mistral 这是在胡说八道”“难道是我记错了论文发布时间?”。随着更多技术细节被扒出,这场争议迅速从 “口头争论” 升级为 “硬核技术对线”,而核心焦点集中在两个关键维度:论文发布时间线,以及架构设计的本质差异。
关键实锤 1:论文发布仅差 3 天,不存在 “借鉴基础”
要判断 “谁借鉴谁”,论文的提交时间线是最直接的证据。网友们迅速扒出两篇核心论文的 arXiv 提交记录:
-
Mistral 的 Mixtral of Experts 论文提交于 2024 年 1 月 8 日,核心是提出稀疏混合专家(SMoE)模型 Mixtral 8x7B,通过每一层设置 8 个前馈网络块(专家),路由网络为每个 token 选择 2 个专家进行处理,实现 “47B 参数规模,13B 活跃参数推理” 的平衡;
-
DeepSeek 的 DeepSeekMoE 论文提交于 2024 年 1 月 11 日,仅比 Mixtral 晚 3 天。该论文聚焦 “极致专家专业化”,提出了全新的 MoE 架构设计,旨在解决传统 MoE 中专家知识重叠、专业化不足的痛点。
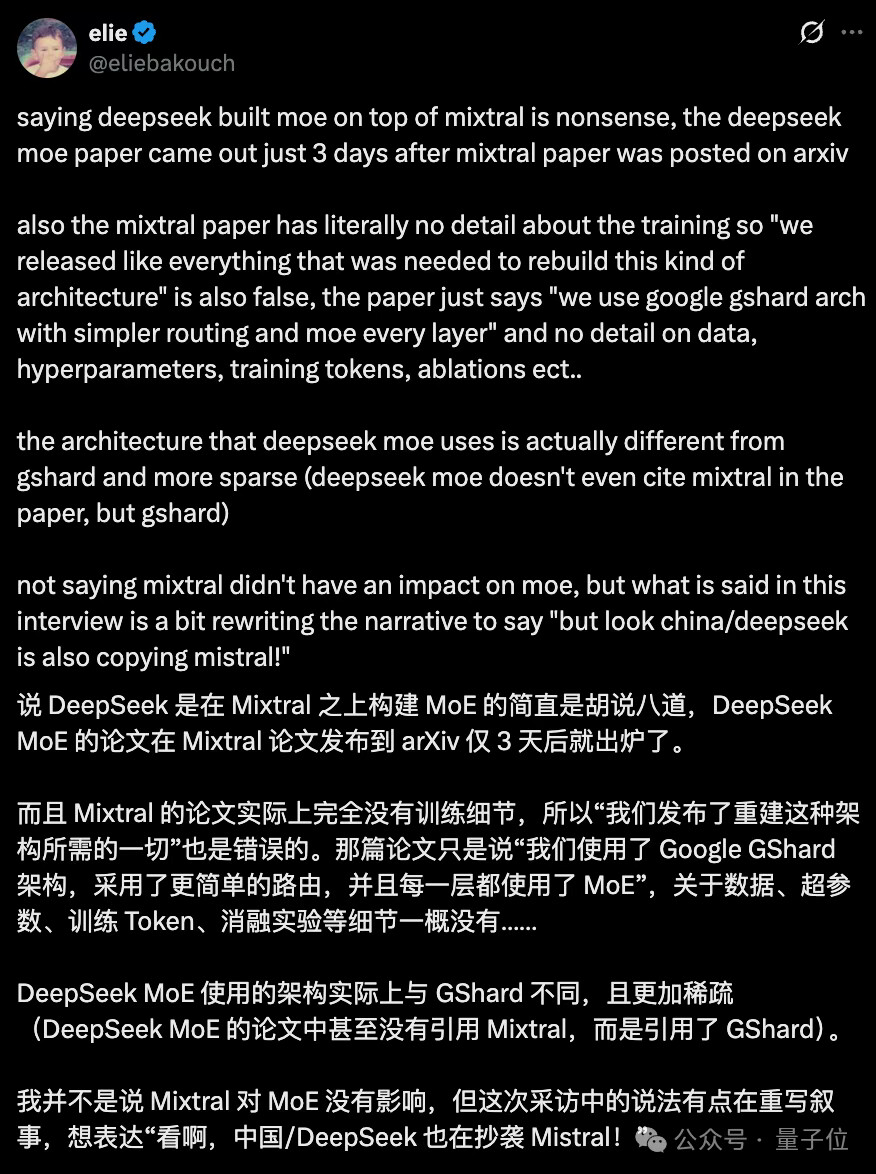
3 天的时间差,意味着两支团队的研发工作几乎是并行推进的,根本不存在 “DeepSeek 在 Mixtral 架构基础上构建” 的前提。正如网友 @eliebakouch 所言:“说 DeepSeek 基于 Mixtral 构建 MoE 纯属无稽之谈,DeepSeek 的 MoE 论文仅在 Mixtral 论文发布 3 天后就出炉了”。更值得注意的是,DeepSeekMoE 论文的参考文献中仅引用了 Google GShard 等经典 MoE 相关研究,并未提及 Mixtral,从学术规范上也佐证了其架构的独立性。

关键实锤 2:架构设计思路迥异,核心创新点完全不同
除了时间线,架构本身的技术细节更能说明问题。表面上看,两者都属于稀疏混合专家模型,核心目标都是通过稀疏激活降低计算成本,但深入拆解后会发现,两者的设计思路、核心创新完全不同,甚至可以说是两条截然不同的技术路径。
1. 设计初衷:工程落地 vs 算法创新
-
Mixtral 的核心思路是 “工程化验证”:将成熟的 MoE 技术与强大的基础模型结合,证明 “通过合理的专家选择机制,可在控制推理成本的同时,实现超越更大稠密模型的性能”。其本质是对现有 MoE 技术的产品化应用,论文中并未深入探讨 MoE 架构的底层优化,甚至未披露训练数据、超参数、消融实验等关键细节,仅提到 “采用 Google GShard 架构,路由更简单,每一层都使用 MoE”;
-
DeepSeekMoE 的核心思路是 “算法级创新”:针对传统 MoE(如 GShard、CShard)中 “专家知识重叠、专业化不足” 的行业痛点,提出了两大核心优化策略 —— 细粒度专家分割与共享专家机制,从根本上重构了 MoE 的专家组织与路由逻辑,属于对 MoE 架构的重新定义。
网友 @gm8xx8 的评价一针见血:“Mixtral 是 GShard 的产品化版本,这符合 Mistral 聚焦产品、缺乏架构野心的定位;而 DeepSeek 是研究驱动的,在开源底层基础设施的同时,正在重新定义 MoE 的设计空间”。

2. 技术细节:四大核心差异,绝非 “相同架构”
通过对比两者的架构设计与数学公式,能更直观地看到差异所在:
| 对比维度 | Mixtral | DeepSeekMoE |
|---|---|---|
| 专家结构 | 沿用标准 MoE 设计,每个专家是完整的 FFN 块,无细分 | 细粒度专家分割:将大专家切分为多个小专家,总参数量不变,组合更灵活 |
| 路由机制 | 所有专家地位平等,路由网络动态选择 Top-2 专家 | 引入 “共享专家 + 路由专家” 双轨制:共享专家始终激活,负责通用知识;路由专家参与 Top-K 竞争,负责特定知识 |
| 知识分布 | 扁平分布,通用知识与特定知识混杂在同一专家中 | 解耦分布,共享专家与路由专家各司其职,专业化程度更高 |
| 数学表达 | y=∑(i∈Top2) Expert_i (x),仅依赖选中的 2 个专家输出 | g (x)=∑(i∈TopK) Expert_i (x) + ∑(j∈Shared) Expert_j (x),融合共享专家与路由专家的输出 |
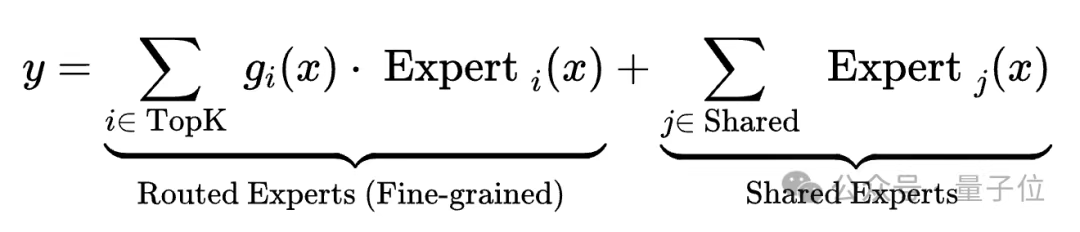
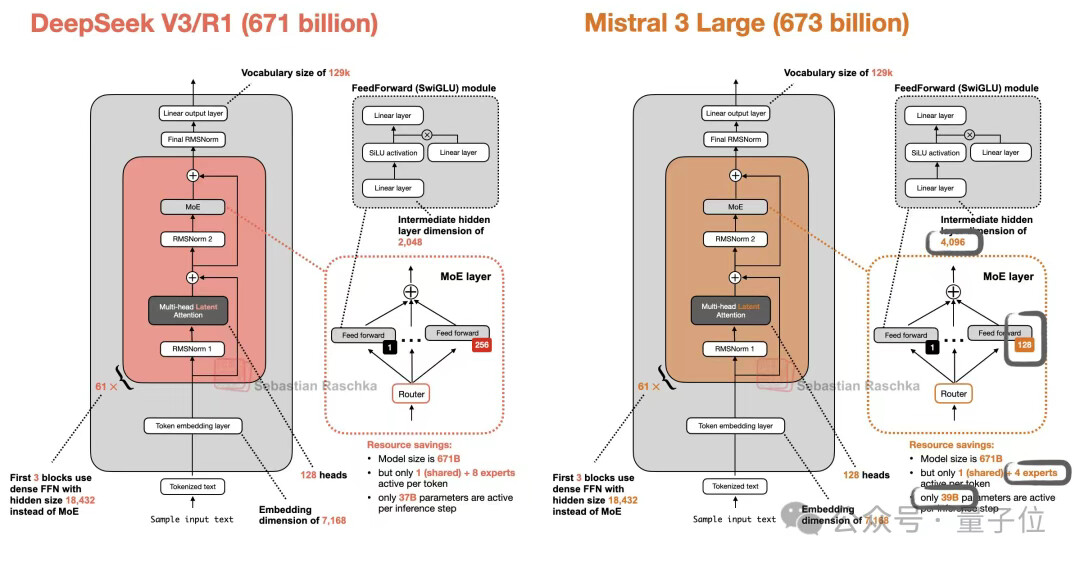
更具戏剧性的是,2025 年 12 月 Mistral 发布的 Mistral 3 Large 模型,被网友扒出 “几乎照搬了 DeepSeek-V3 的架构”。开发者 @Sebastian Raschka 在查阅配置文件后发现:“Mistral 3 Large 使用了 DeepSeek V3 的架构,包括 MLA 模块,唯一的区别是它的专家数量减少了 2 倍,但每个专家的规模扩大了 2 倍”。这一发现让 Mistral CEO 的言论更显矛盾,网友调侃:“到底是谁借鉴谁的架构?这简直是岁月史书式发言”。
3. 性能验证:创新架构带来显著优势
DeepSeekMoE 的架构创新也得到了性能数据的佐证:
-
基础规模(2B 参数):DeepSeekMoE 2B 与参数 1.5 倍于它的 CShard 2.9B 性能相当,且接近同参数量稠密模型的性能上限;
-
中等规模(16B 参数):仅需约 40% 的计算量,就能达到 LLaMA2 7B 的性能水平;
-
大规模(145B 参数):相比 GShard 架构优势显著,性能与 DeepSeek 67B 相当,但仅需 28.5%(最低可至 18.2%)的计算量。
而 DeepSeek-V3(671B 参数)的实际表现更能说明问题:其采用 “1 个共享专家 + 8 个路由专家” 的激活模式,每 token 仅激活 37B 参数,却能实现高效推理;而 Mistral 3 Large(673B 参数)虽架构高度相似,但采用 “1 个共享专家 + 4 个路由专家” 模式,激活参数达 398B,在计算效率上明显处于劣势。这也从侧面证明,DeepSeek 的架构设计在 “性能 - 效率” 平衡上更具优势。
网友热议:开源精神是 “互相成就”,而非 “歪曲事实”
这场争议引发了开源社区对 “开源精神” 的广泛讨论。多数网友认为,开源的核心是 “开放、协作、共同进步”,不同团队之间相互借鉴技术思路是正常现象,但前提是尊重事实,不能歪曲研发历程、抢占创新功劳。
-
网友 @Vexxter4sure 评论:“广义上讲,Mistral 是 MoE 应用的先驱,但他们的执行力与 DeepSeek 在稀疏 MoE、MLA 等技术上取得的成就相比相去甚远。他们的优势就像浸在牛奶咖啡里的巧克力面包一样,瞬间消散了”;
-
网友 @OmarBessa 吐槽:“Mistral 被发现用了 DeepSeek 的架构,现在却试图通过诋毁超越他们的对手来挽回面子”;
-
还有网友感慨:“最初发布 Mistral-7B 时的 Mistral 和今天的 Mistral 判若两人,曾经惊艳开源圈的创新者,现在却陷入了‘歪曲事实’的争议中”。
事实上,开源社区的健康发展,依赖于对创新的尊重、对事实的敬畏。DeepSeek 作为国产开源大模型的代表,始终坚持 “开源共享、研究驱动” 的理念,从 DeepSeekMoE 到 Engram 架构,再到即将发布的 DeepSeek-V4,每一步都以解决行业痛点、推动技术进步为目标,并用论文、代码、性能数据等实实在在的成果说话。而 Mistral CEO 的这番言论,显然违背了开源精神的核心,也难怪会遭到网友的一致反驳。
行业启示:技术竞争的核心是创新,而非口水战
这场争议的背后,反映的是全球开源大模型赛道的激烈竞争。随着 AI 技术的飞速发展,开源已成为推动技术普及、加速创新迭代的核心力量,而真正的竞争,从来不是 “谁借鉴了谁” 的口水战,而是 “谁能真正解决行业痛点、谁能做出突破性创新” 的实力比拼。
DeepSeek 用实际行动证明:中国开源 AI 的崛起,靠的不是 “借鉴”,而是持续的研发投入、对技术本质的深刻洞察,以及对开源精神的坚守。从 DeepSeek-R1 在推理领域的突破,到 Engram 架构解决大模型幻觉问题,再到 DeepSeek-V4 即将带来的低门槛部署、专业知识库插件等创新,每一项成果都凝聚着团队的技术积累与创新思考。
正如网友所言:“嘴炮无用,技术实力才是硬道理”。据悉,DeepSeek 已瞄准春节前后发布全新版本,届时将带来更多架构与功能创新。我们相信,随着更多中国开源力量的崛起,全球 AI 领域将形成更健康、更具活力的竞争格局,而创新终将成为行业发展的唯一通行证。