过去一年,AI行业关键词是“热闹”。
融资狂潮、发布会频仍、应用爆款迭出、参数竞赛如火如荼。薪酬翻倍、期权加码、团队打包流动,天价挖角戏码层出不穷。
却在这一片喧嚣中,DeepSeek异常安静:几乎不接受采访、不频繁发声,也鲜少参与舆论争夺。
直到最近,一个信号日益清晰:
DeepSeek开始系统性招人。
与招聘信息同期浮现的,还有一系列底层架构论文、开源代码,以及R1模型在多项推理基准超越OpenAI o1的成绩。
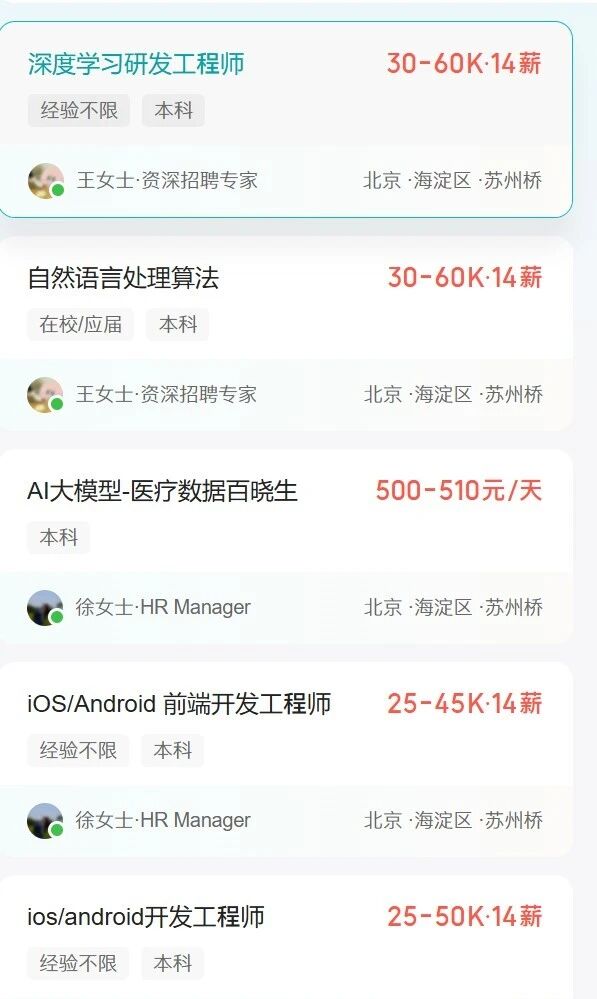
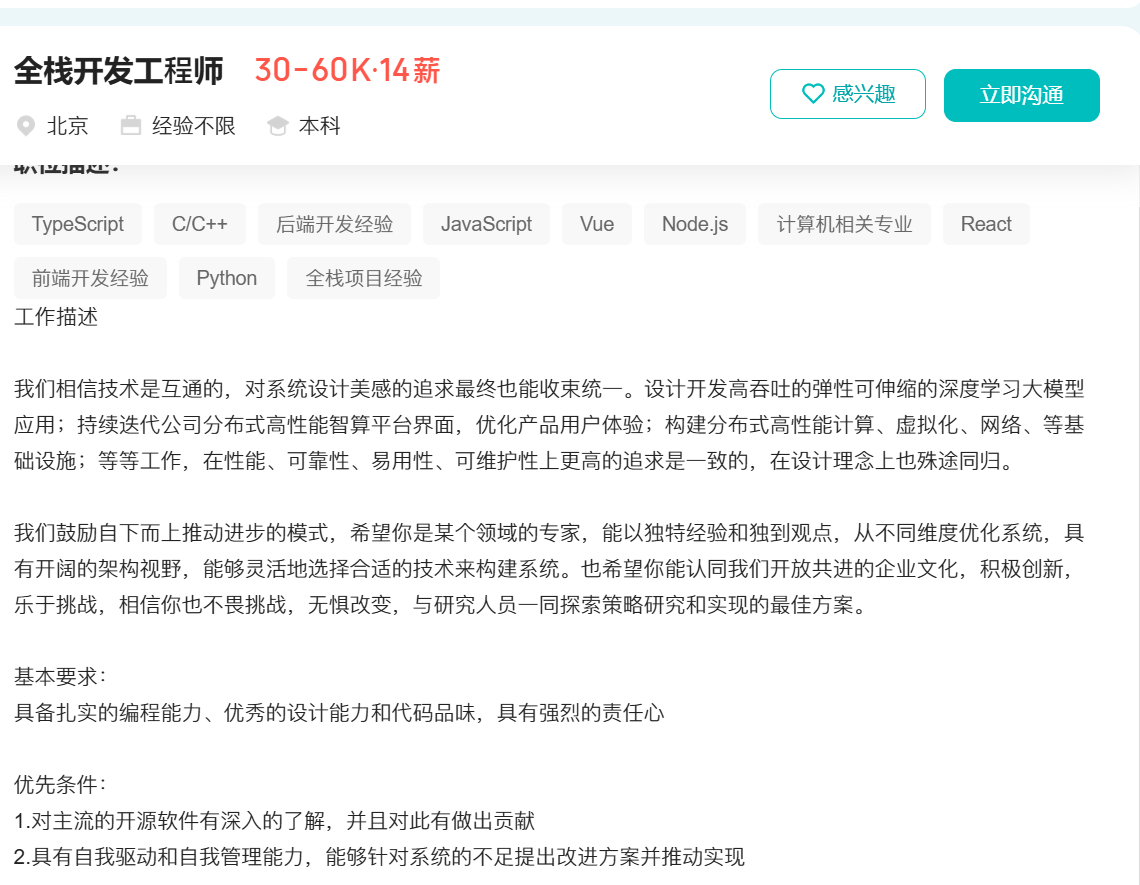
显然,它已跑通组织路径,并准备将“人”继续视为最重要的战略资产。
01 DeepSeek这一年在做什么?
表面看,DeepSeek“存在感”不强。但拉长视角,它在做一件极不讨巧、却至关重要的事——回归模型架构本身。
从Multi-head Latent Attention(MLA)、DeepSeekMoE,到R1背后的推理突破,DeepSeek将主要精力投入0→1的底层创新,而非快速追应用热点。
这种选择,决定了它需要什么样的人才。
02 用人标准:好奇心优先
大厂招聘常偏好顶级学历、大厂背景、明确技术标签。
DeepSeek却不同。从公开发言与研究者背景看,其标准清晰:好奇心 > 经验 > 标签化履历。
他们不迷信“做过什么项目”“在哪家大厂待过”,更在意:
- 对复杂问题是否保持长期兴趣
- 是否愿意反复推翻自己
- 是否具备从0构建方法的能力
因此,团队中有大量年轻研究者,甚至非传统CS背景人才。他们被鼓励将个人兴趣转化为研究方向,而非迅速“塞进岗位定义”。
DeepSeek招的,不是“已成功的人”,而是拥有“热情与好奇心”的人。

03 研究管理:允许不可预测
从HR视角,DeepSeek最独特之处在于:几乎不以传统KPI管理研究人员。
许多公司将研究拆解为阶段目标、可交付成果、时间节点、量化指标。
但前沿研究本质不可预测,这往往导致“安全产出”而非大胆探索。
DeepSeek接受这一现实:真正创新往往源于意外。R1关键架构,正是年轻研究员个人兴趣探索的结果——非自上而下规划,而是“潜力显现时,自上而下配置资源”。
研究员被鼓励将时间投入“难但重要”的问题,而非“易证明有效”的方向。管理层更像资源配置者,而非任务分配者。
在DeepSeek,研究不是KPI,而是一种允许失败的长期投入。
04 为什么DeepSeek能留住人?
系统分析DeepSeek团队,会发现:
- 整体经验并不青涩
- 核心作者论文产出、引用量高
- 背景高度本土化,却具国际一线训练
更关键的是,低流动率。与“年轻天才一骑绝尘”不同,DeepSeek不靠少数明星支撑。Math核心算法由3位实习博士完成,V3论文200位作者参与软硬件优化,证明其成熟、均衡的团队结构,利于长期协作与知识沉淀。
R1论文18位核心贡献者全员留任,百余作者仅5人离职,甚至有核心成员回流——这是团队健康度的最佳体现。
此外,DeepSeek是全球唯一未外部融资、不隶属大厂的AI Lab。母公司幻方量化主业与AI无冲突,无股权约束、无损益压力,让研究者无需为商业化妥协,专注长期主义。
2025年幻方量化营收约50亿元,提供顶级算力、数据集、高校合作与丰厚薪酬。
坚持开源与学术分享,又让研究者获行业认可。这种“做有价值的事、被看见、被尊重”的氛围,对顶尖人才吸引力不亚于物质。
DeepSeek留人,不是“绑住”,而是用健康生态,让人觉得“留下来更有价值”。
在这个时间点,DeepSeek 招的并不是执行者,而是未来几年创新能力的一部分。
热闹是一时的,而构建未来需要安静的力量。