深度学习与语言模型:从电路比喻到ChatGPT的通俗解读
这篇文章用简单直白的比喻(电路、老式打字机)解释了深度学习、大型语言模型(LLM)和Transformer的工作原理。我会重新整理并改写内容,让它更清晰易懂,同时配上插图帮助你直观理解。
4. 什么是深度学习?
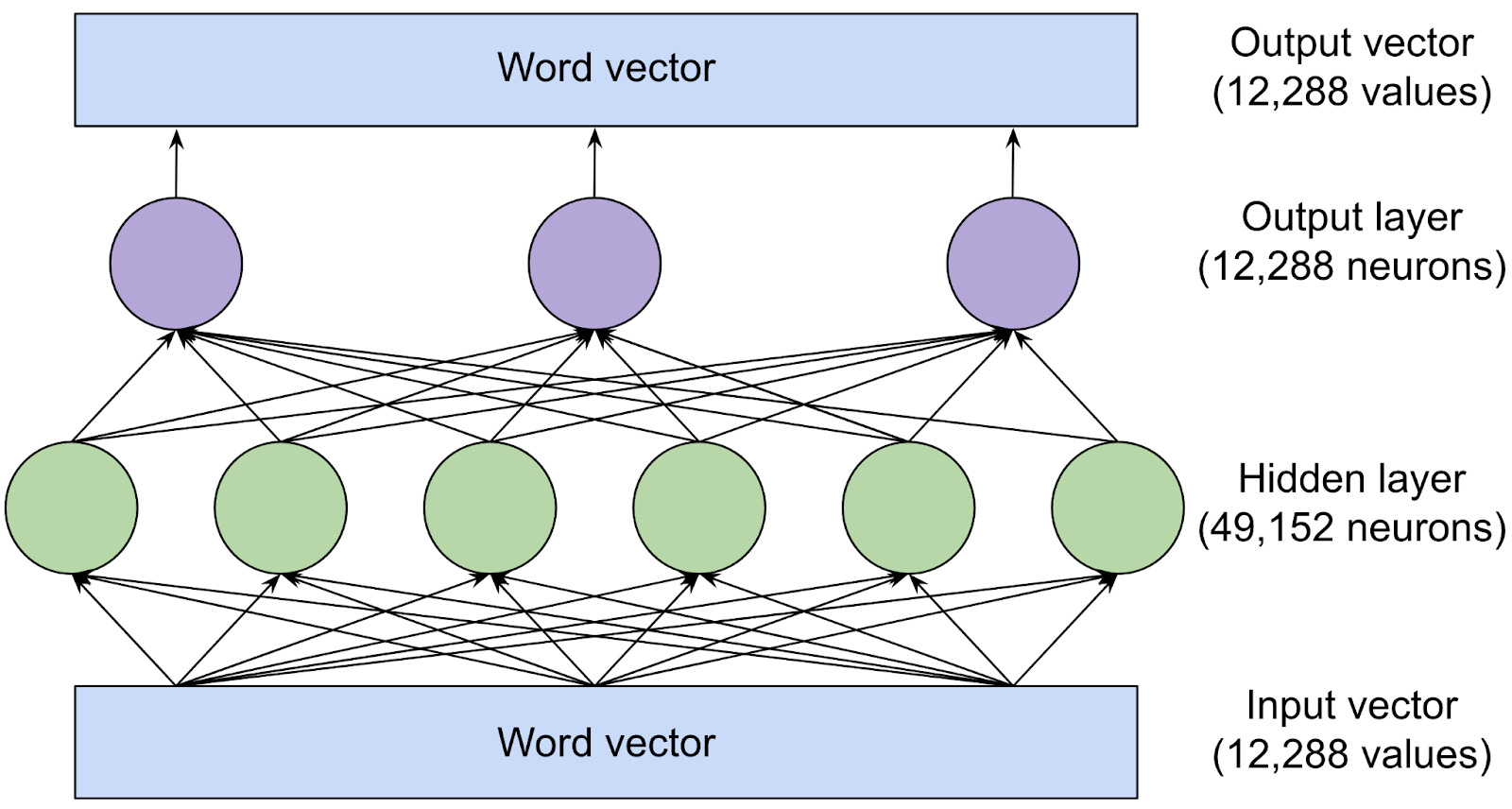
深度学习本质上就是构建一个巨大的“电子电路”,用电阻和门电路来模拟复杂行为。
在自动驾驶的例子中,我们不直接编程“看到红灯就刹车”,而是让神经网络通过大量数据自己调整参数(电阻值),最终让输出(踩刹车、转方向盘)与真实驾驶员一致。
深度学习的核心还是“猜参数 + 逐步调整”(反向传播),但层数更深、规模更大,能处理更复杂的任务。
5. 什么是语言模型?
语言模型的目标是:给定前面几个词,预测下一个最可能的词。
比如:“从前有一个____” → 很可能填“时间”,而不是“犰狳”。
用概率表示:P(time | 从前有一个) > P(犰狳 | 从前有一个)
想象一台超级大的老式打字机:不是26个字母键,而是5万个常用词的“击针臂”。每个输入词触发一个传感器,电路处理后,激活最可能的下一个词的击针臂。
直接连接太夸张(50,000 × 50,000 = 25亿条线),所以需要聪明的方法压缩。
5.1 编码器:把单词压缩成“概念”
我们把网络分成两部分:编码器和解码器。
编码器把一个单词(用50,000维的独热向量表示)压缩成一个短得多的向量(比如256维),类似文件压缩。
意义相近的词(如“国王”和“女王”)会被压缩成几乎相同的向量,而“犰狳”会很不同。
这256个数字可以是小数,组合起来能表示海量概念(2^256种可能)。
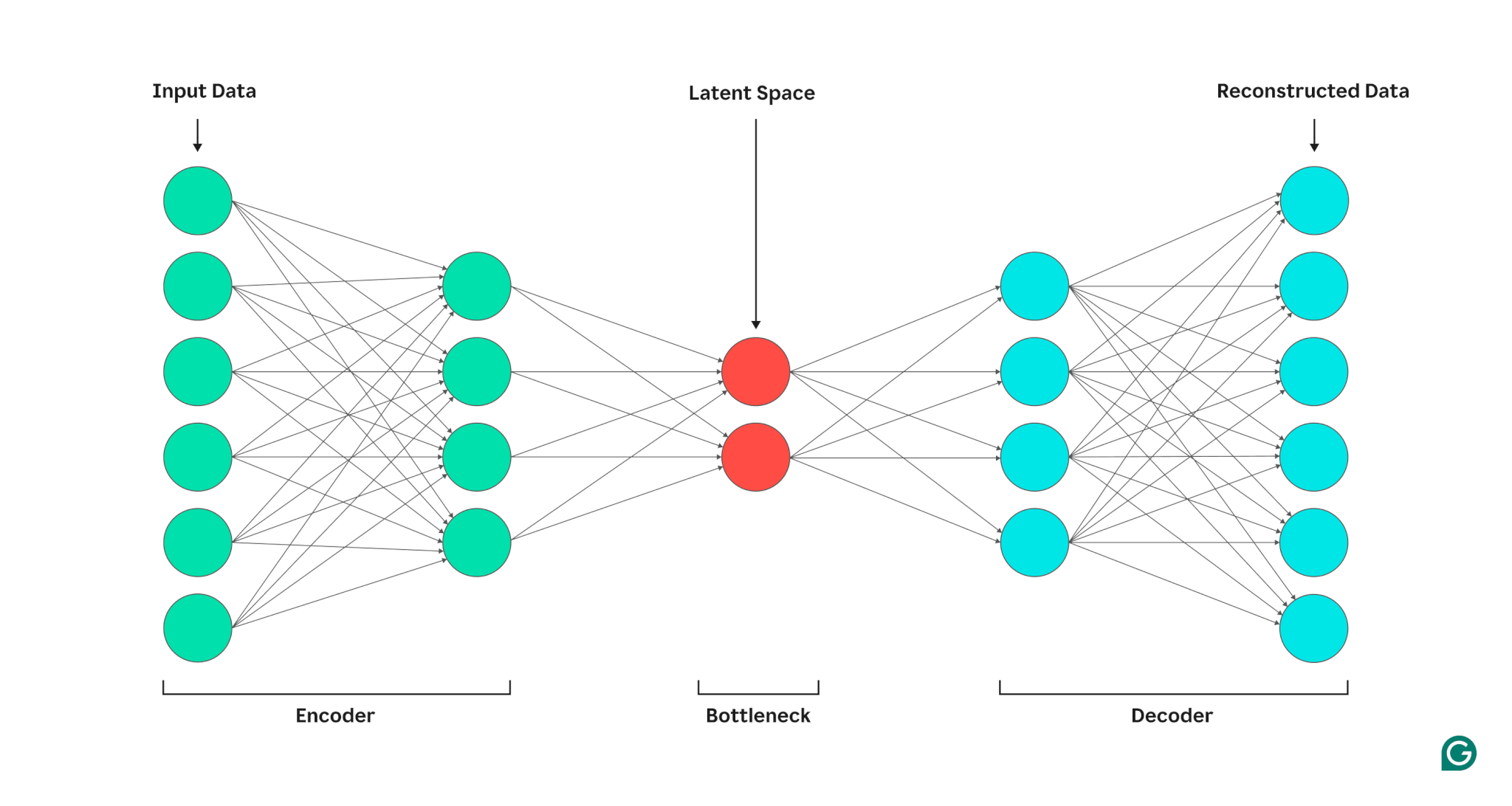
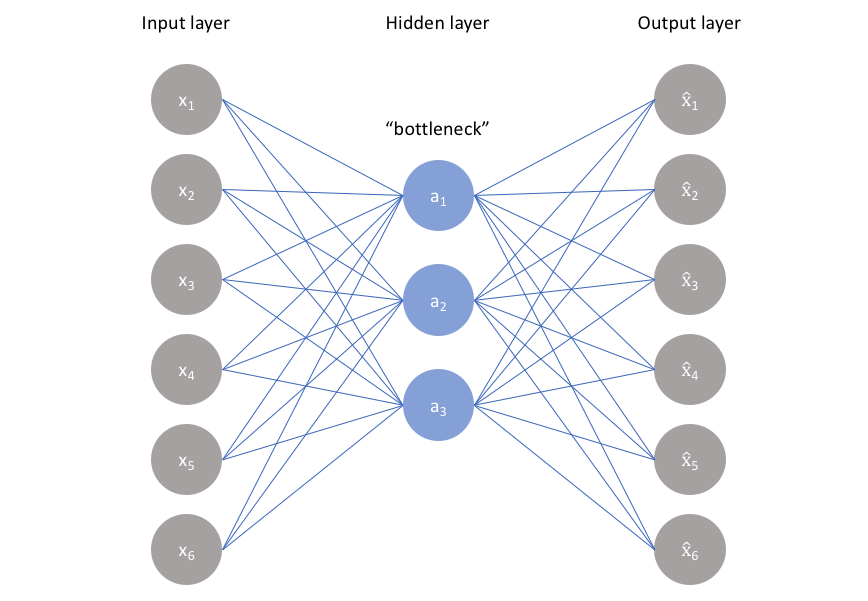
5.2 解码器:把“概念”展开成单词
解码器接收256维向量,扩展回50,000维,激活最可能的下一个词的击针臂。
5.3 编码器+解码器:完整流程
两者组合形成一个大网络,参数量大幅减少(约2560万),还能捕捉词义相似性。
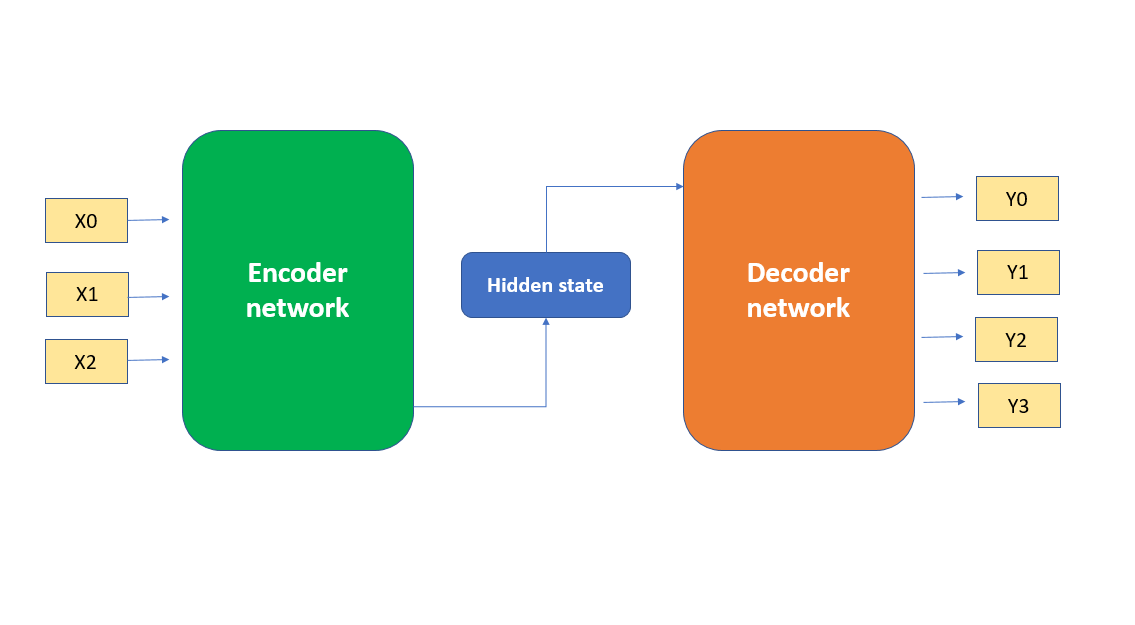
5.4 自我监督:自己教自己
训练时可以让网络输入一个词,试图重建同一个词(自编码器)。网络被迫把相似的词编码得接近。
5.5 掩蔽语言模型(Masked LM)
更常见的方式:随机遮住句子中的词,让网络预测被遮住的词(比如BERT用的方法)。
还有一种是自回归模型(GPT用的):总是预测下一个词,逐步生成文本。
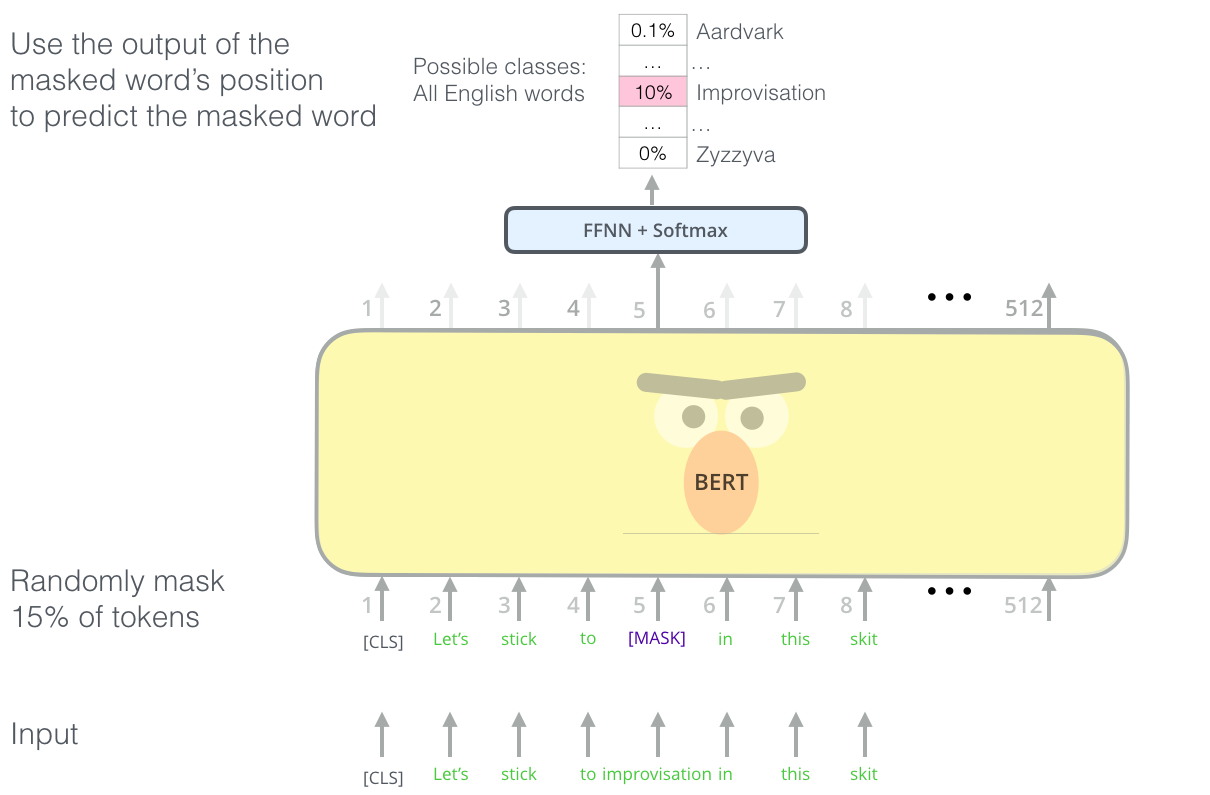
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer …
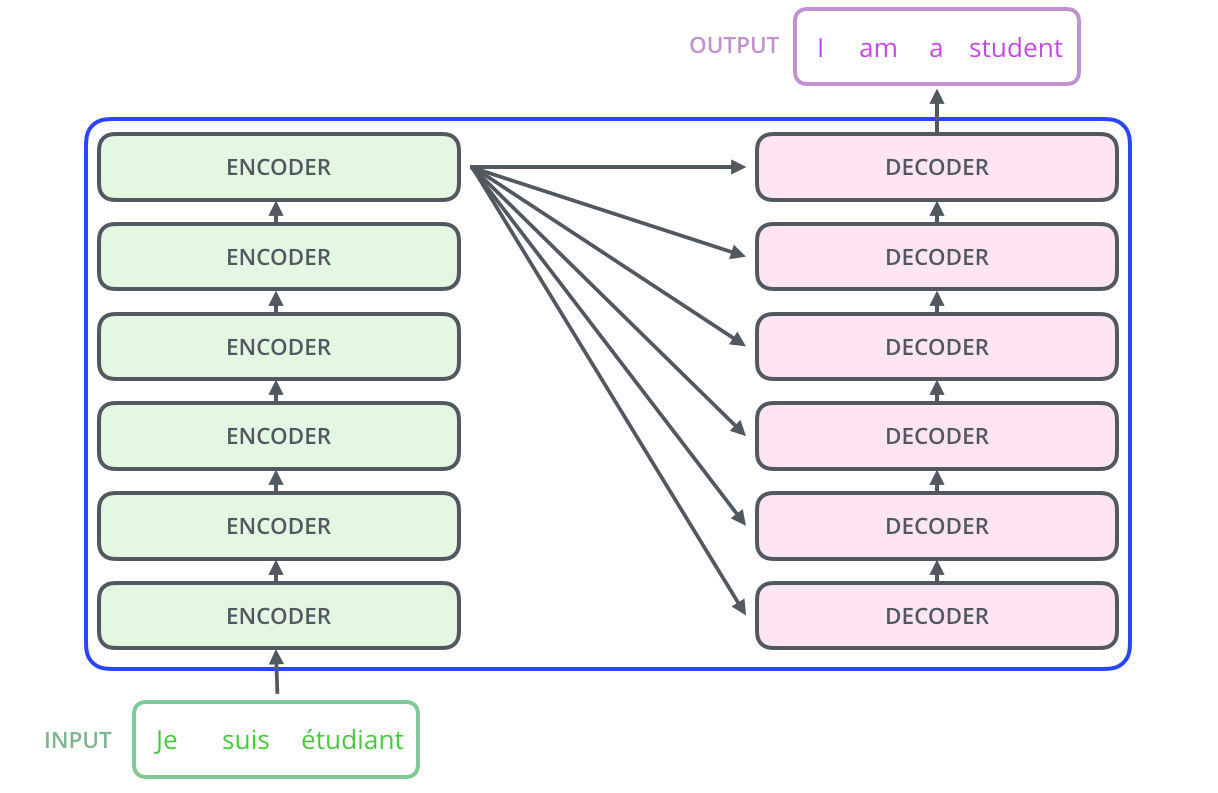
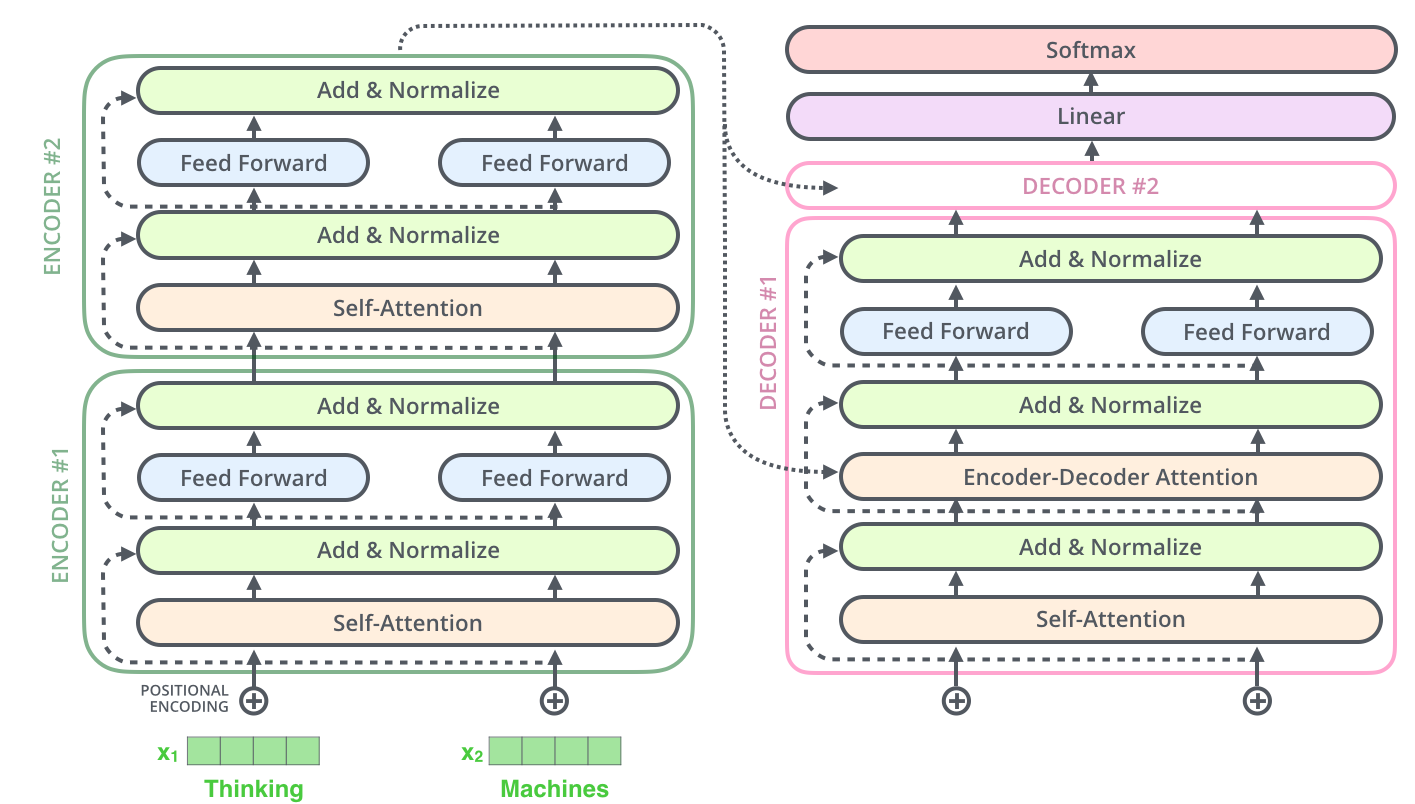
6. 什么是Transformer?
Transformer是目前主流的大型语言模型架构(GPT系列都基于它),2017年论文《Attention is All You Need》提出。
核心改进:自注意力机制(Self-Attention),让模型知道哪些词对预测当前词最重要。
比如句子“外星人降落在地球上,因为它需要……” → “它”指代“外星人”,自注意力能捕捉这种关系。
自注意力把相关词的编码混合,形成新的、更丰富的表示。
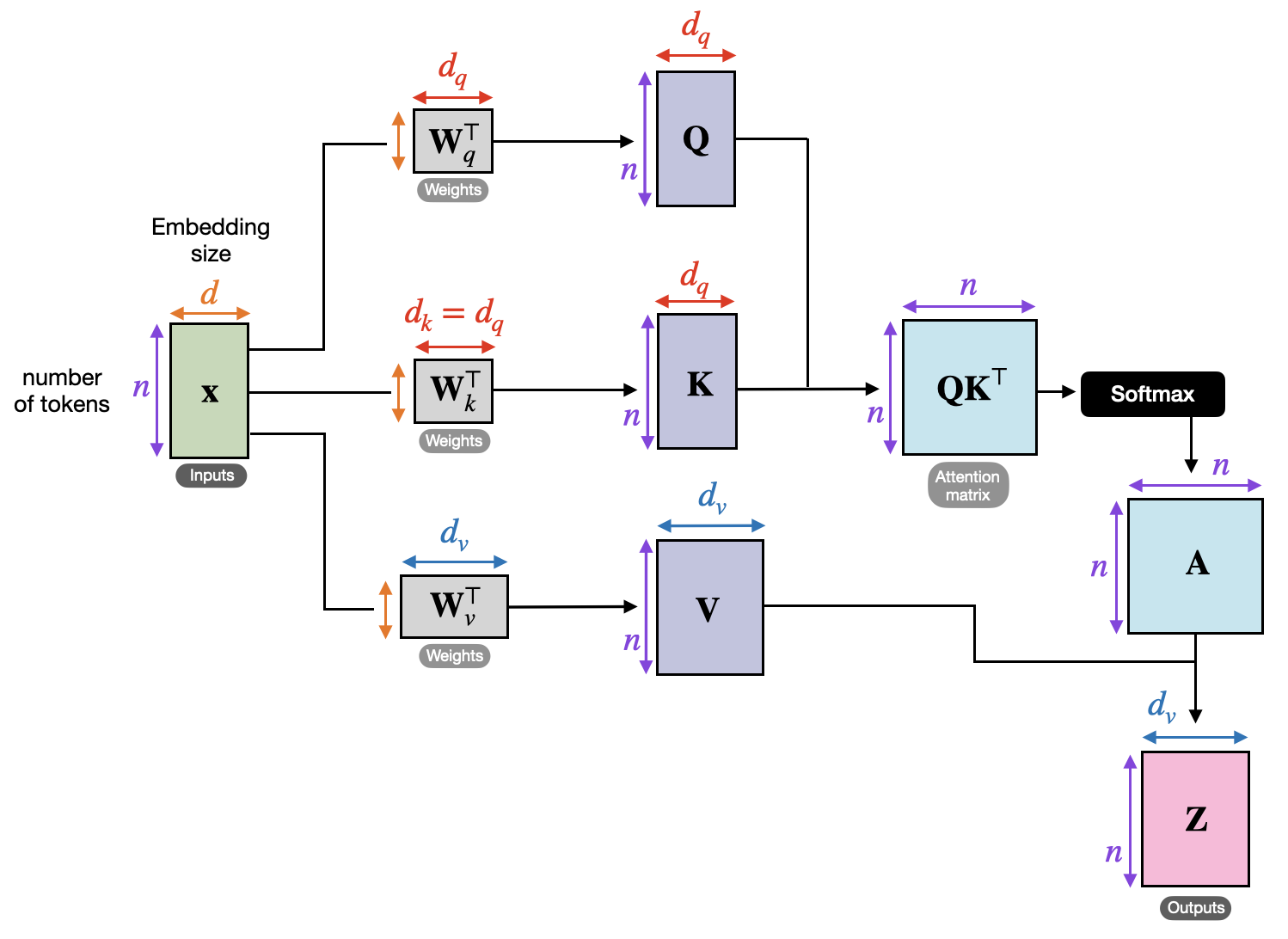
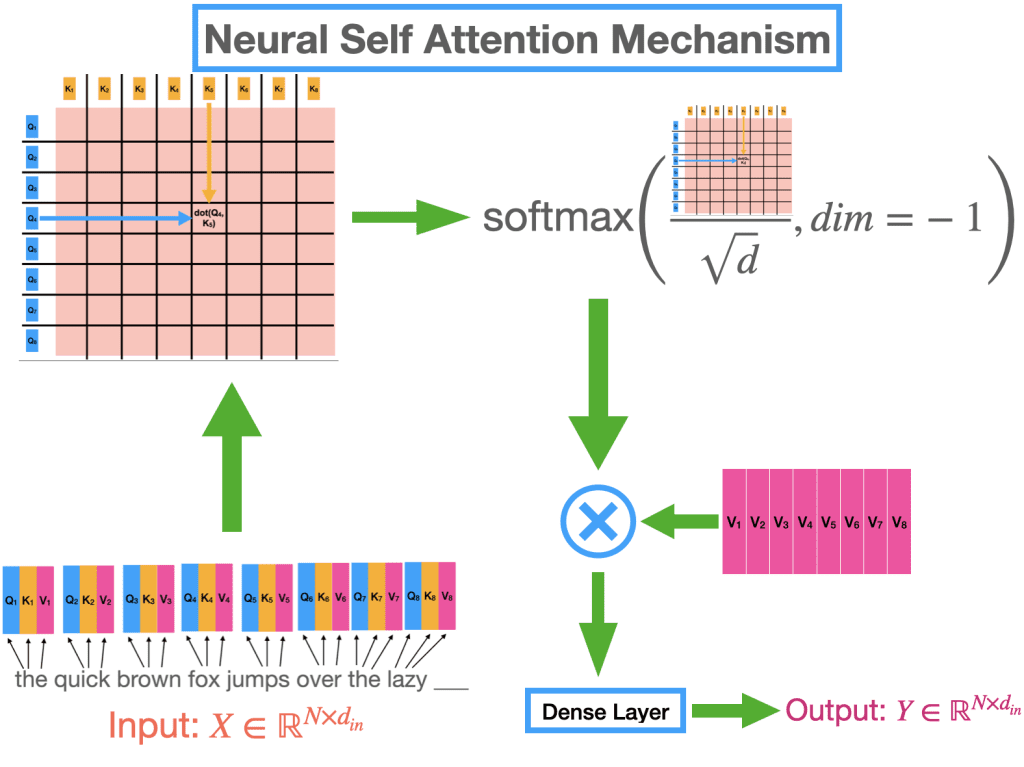
6.2 自注意力怎么工作?(简要版)
- 把每个词编码成向量,复制成查询(Query)、键(Key)、值(Value)三份。
- 计算查询和键的点积,得到注意力分数(哪些词相关)。
- 用分数加权混合值向量,得到新的编码(包含上下文信息)。
多层堆叠后,模型能理解复杂关系。
7. 为什么大型语言模型(LLM)这么强大?
LLM只做一件事:预测下一个词。
但因为训练数据是整个互联网(书籍、网页、论坛、代码……),它们见过几乎所有常见模式:
- 写诗 → 见过亿万首诗
- 写代码 → 见过无数代码片段
- 回答问题 → 见过无数问答
- 总结文本 → 见过无数总结
自注意力让它们能灵活组合这些模式,产生看似“聪明”的输出。
本质是超级强大的模式匹配 + 统计平均,而不是真正理解或推理。
Large language models, explained with a minimum of math and jargon
8. 使用LLM时需要注意什么?
- 训练数据包含偏见、错误、负面内容 → 输出可能重复这些。
- 没有真实信念 → 可以轻易生成相反观点。
- 没有真理概念 → 可能“幻觉”(编造事实)。
- 自回归特性 → 一个错误可能导致后面全错。
- 必须验证输出 → 尤其高风险场景。
- 提示质量决定输出质量 → 多尝试不同提示。
- 不是真正对话 → “记忆”是把历史文本重新输入。
- 不真正规划或解决问题 → 只是生成“看起来像计划”的文本。
9. ChatGPT为什么特别?
ChatGPT基于同样的Transformer(GPT系列),但多了两步关键训练:
9.1 指令调优(Instruction Tuning) 让人与基础模型交互,收集“正确回答”的样本,再微调模型,让它更善于遵循指令,而不是继续完成文本。
9.2 基于人类反馈的强化学习(RLHF) 让人对多个候选回答排序(点赞/踩),用强化学习调整模型,使其更倾向生成人类偏好的回答(更有帮助、更安全、不乱编)。
这让ChatGPT显得更“聪明”、更安全,但本质仍是词预测器,只是预测的词更符合人类喜好。
总结:大型语言模型强大但有限,它们是人类互联网文本的“压缩镜像”。理解它们的原理,能帮助我们更理性地使用,避免过度拟人化。