RAG模型通过利用外部知识来增强生成过程,从而生成更准确且符合上下文的回答。基础RAG方法包括以下几个关键步骤:
• 用户意图理解
• 知识源与解析
• 知识嵌入
• 知识索引
• 知识检索
• 知识整合
• 回答生成
• 知识引用
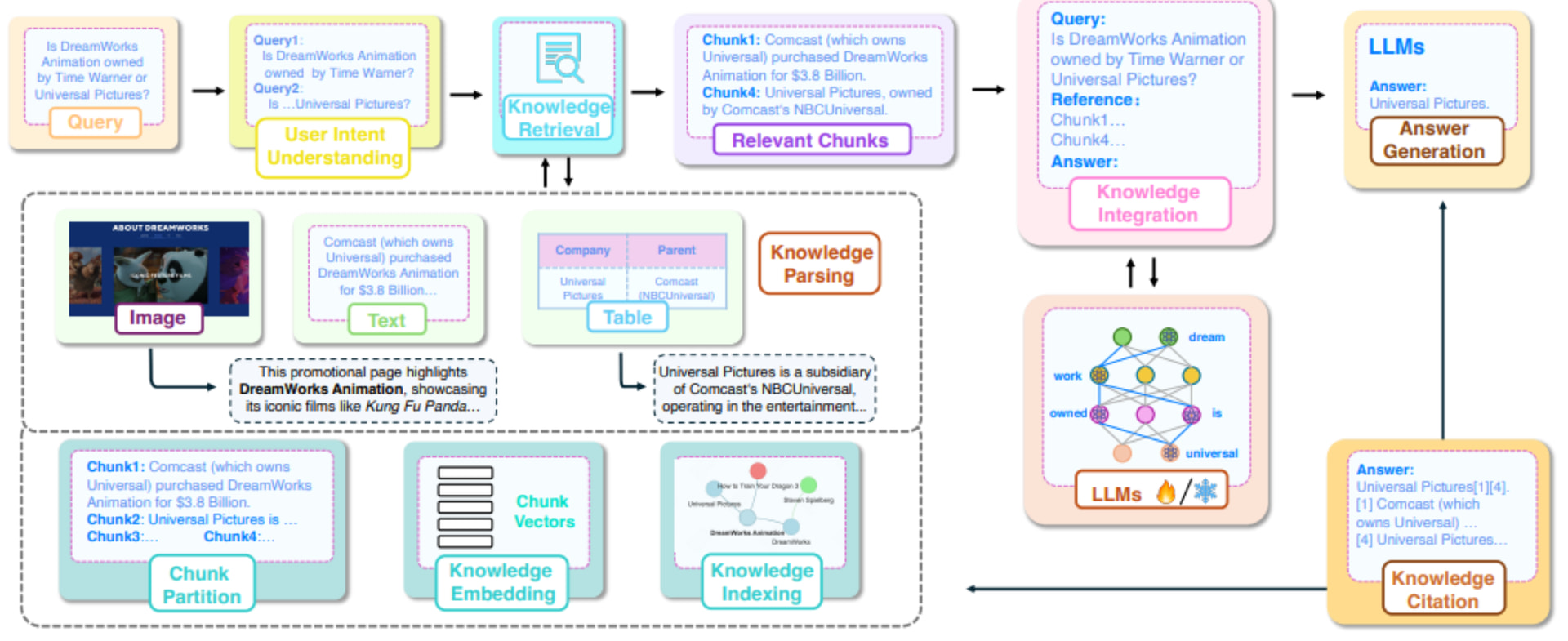
本篇主要介绍用户意图理解与知识源解析:
1 用户意图理解
高质量的查询对于检索有价值的知识至关重要。由于用户的意图往往不明确,准确理解用户查询是实现更有效和精确检索的关键。目前,许多研究专注于提升对用户查询的理解。本两种提升查询质量的关键方法:查询分解和查询重写。
1.1 查询分解(Query Decomposition)
查询分解方法已成为增强语言模型推理能力的有效策略,尤其适用于需要多步或组合推理的复杂任务,例如:
-
最少到最多提示(least-to-most prompting) :将复杂问题逐步分解为更简单的子问题,从而提升模型在更困难任务上的泛化能力。这种方法在SCAN任务中表现出色,GPT-3模型仅用14个示例就达到了99%以上的准确率。
-
自问(Self-ask):采用了类似的方法,但进一步优化了过程,通过让模型提出并回答后续问题,减少了组合性差距,从而实现了更好的多跳推理。
-
验证链(Chain-of-Verification, CoVe) :通过让模型独立验证其回答,提高了答案的可靠性,显著减少了在列表问题和长文本生成任务中的幻觉现象。
-
链中搜索(Search-in-the-Chain, SearChain):将信息检索(IR)整合到推理过程中。在该框架中,模型构建一个查询链(Chain-of-Query, CoQ),每个查询都通过IR进行验证,从而提高了推理路径的准确性和可追溯性。SearChain允许模型根据检索到的信息动态调整其推理,从而在多跳问答和事实核查等知识密集型任务中表现出色。
1.2 查询重写
查询重写已成为提升RAG性能的关键技术,特别是在解决语义差距和改善任务结果方面。
-
重写-检索-阅读(Rewrite-Retrieve-Read, RRR) :通过使用LLM在检索前生成和优化查询,提升了查询与目标知识的对齐,从而在开放域问答和多选任务中显著提高了性能。
-
BEQUE :专注于电子商务搜索中的长尾查询,通过监督微调、离线反馈和对比学习来弥合语义差距,从而在GMV和交易量等业务指标上取得了显著提升。
-
HyDE:引入了一种零样本的密集检索方法,通过让LLM生成假设文档并将其编码用于检索相关文档,超越了传统的无监督检索器。
-
Step-Back Prompting :鼓励LLM从具体示例中抽象出高级概念,从而在STEM、多跳问答和基于知识的推理任务中提升了推理能力。这些方法共同增强了RAG在跨领域知识密集型任务中的有效性和可扩展性。
2 知识源与解析(Knowledge Source and Parsing)
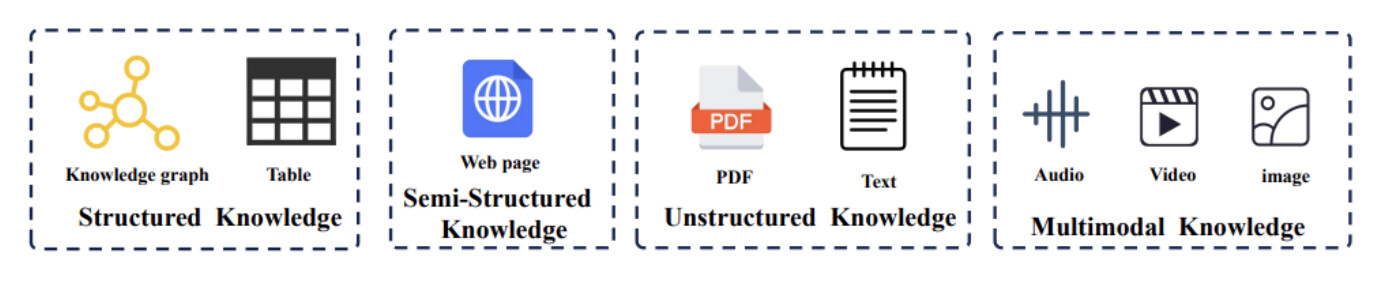
RAG可以利用的知识类型多种多样,为LLM提供了丰富的上下文信息。所使用的知识类别,包括结构化、半结构化、非结构化和多模态知识,以及它们各自的解析和整合方法。
2.1 结构化知识的利用
知识图谱(Knowledge Graphs, KGs)是一种结构化表示,以图的形式封装实体及其相互关系。
其结构化特性便于高效查询和检索,而语义关系则支持更细致的理解和推理。KGs整合了来自不同来源的信息,提供了统一的知识库。然而,将KGs整合到RAG系统中也面临挑战,包括从大规模KGs中导航和提取相关子图的复杂性、KGs扩展时的可扩展性问题,以及将结构化数据与语言模型的无序数据处理对齐的困难。例如:
-
GRAG:通过跨多个文档检索文本子图,提升了RAG系统中的信息检索效率。
-
KG-RAG:引入了探索链(Chain of Explorations, CoE)算法,通过高效导航KGs来提升知识图谱问答(KGQA)任务的表现。
-
GNN-RAG:利用图神经网络(GNNs)从KGs中检索和处理信息,在与LLM对接之前增强了推理能力。从历史数据构建KGs作为RAG的外部知识源,有效提升了信息检索和生成能力[255]。
-
SURGE框架:利用KG信息生成上下文相关且基于知识的对话,提升了交互质量。
-
SMART-SLIC、KARE、ToG 2.0 和KAG,展示了KGs在特定领域作为外部知识源的有效性,提升了RAG系统的准确性和效率。
2.2 半结构化知识的提取
半结构化数据介于结构化和非结构化格式之间,具有组织元素但没有严格的模式。例如,JSON和XML文件、电子邮件以及HTML文档。HTML作为网页的基础,结合了标签和属性等结构化组件与自由文本等非结构化内容。
这种混合特性允许HTML表示复杂信息,包括文本、图像和链接。然而,HTML的灵活性也可能导致不一致和异常,给数据提取和整合到RAG系统带来挑战。
-
HtmlRAG:在大多数场景中,开源HTML解析技术仍然是高效数据提取和无缝整合的关键。这些工具提供了强大的解析能力和对多样化HTML结构的适应性,确保了在各种应用场景中的高效性和准确性。
-
Beautiful Soup:一个用于解析HTML和XML文档的Python库,创建解析树以便轻松提取数据;
-
html5ever:由Servo项目开发的开源HTML解析器,遵循WHATWG的“HTML5”规范;
-
htmlparser2:一个用于Node.js环境的强大HTML解析器,提供快速灵活的方式处理HTML文档;
-
MyHTML“”一个基于Crystal语言的高性能HTML5解析器,绑定到lexborisov的myhtml和Modest库;
-
Fast HTML Parser[39],一个极快的HTML解析器,生成最小的DOM树并支持基本元素查询。
2.3 非结构化知识的解析
非结构化知识涵盖了缺乏一致结构的数据类型,如自由文本和PDF文档。与遵循预定义模式的结构化数据不同,非结构化数据的格式多样,通常包含复杂内容,使得直接检索和解释具有挑战性。在非结构化格式中,PDF文档在知识密集型领域中尤为常见,包括学术研究、法律文件和公司报告。PDF通常包含大量信息,如文本、表格和嵌入图像,但其固有的结构可变性使得提取和整合到RAG系统变得复杂。
解析PDF仍然具有挑战性,因为需要准确解释不同的布局、字体和嵌入结构。将PDF转换为RAG系统可读的格式需要光学字符识别(OCR)来捕获文本,布局分析来理解空间关系,以及先进的方法来解释表格和公式等复杂元素。
-
ABINet:通过双向处理增强了OCR的准确性。
-
GPTPDF:使用视觉模型将表格和公式等复杂元素解析为结构化的Markdown,在大规模处理中具有高成本效益。
-
Marker:专注于清理噪声元素,同时保留文档的核心格式,非常适合学术和科学文档。
-
PDF-Extract-Kit:支持高质量内容提取,包括公式识别和布局检测
-
Zerox OCR:将PDF页面转换为图像,并使用GPT模型生成Markdown,有效管理标题和表格等结构。
-
MarkItDown:是一个多功能工具,能够将PDF、媒体、网页数据和存档等多种文件类型转换为Markdown。
2.4 多模态知识的整合
多模态知识(包括图像、音频和视频)提供了丰富的互补信息,可以显著增强RAG系统,特别是在需要深度上下文理解的任务中。图像提供空间和视觉细节,音频贡献时间和语音层,而视频结合了空间和时间维度,捕捉运动和复杂场景。传统的RAG系统主要设计用于文本数据,在处理和检索这些模态的信息时往往表现不佳,导致在非文本内容至关重要时生成不完整或不够细致的回答。
为了应对这些限制,现代多模态RAG系统开发了基本方法来整合和检索跨模态的数据。其核心理念是将不同模态对齐到一个共享的嵌入空间中进行统一处理和检索。
-
CLIP:将视觉和语言对齐到一个共享空间
-
Wav2Vec 2.0 和CLAP:音频模型则专注于音频与文本的对齐。
-
ViViT:处理空间和时间特征。
下篇继续介绍 RAG 中其他的关键步骤