尽管规模不断扩大、智能程度持续提升的模型正稳步推出,但最先进的生成式大型语言模型(LLMs)仍存在一个显著问题:它们在需要专业知识的任务上表现吃力。这种专业知识的缺失可能引发 “幻觉” 等问题,即模型生成不准确或虚构的信息。而检索增强生成(RAG)技术则通过允许模型从外部来源获取实时、特定领域的数据,有效缓解了这一问题,进而提升模型提供准确、详细回答的能力。 尽管存在这些局限,生成式模型仍是极具影响力的工具 —— 它们能自动化处理重复性流程、辅助我们的日常工作,还能让我们以全新方式与数据交互。那么,我们该如何充分利用其广博的知识,同时让它们适配我们特定的使用场景呢?答案就在于为生成式模型提供任务专属数据。 在本文中,我们将深入探讨检索增强生成(RAG)这一框架。该框架通过允许生成式模型参考外部数据,显著增强了其能力。我们将分析催生 RAG 技术的生成式模型局限、阐释 RAG 的工作原理、拆解 RAG 流水线背后的架构;同时也会结合实际,概述 RAG 在现实世界中的一些应用场景、提出具体的 RAG 实施方法、介绍几种先进的 RAG 技术,并探讨 RAG 的评估方式。
生成模型的局限性
生成式模型通过在大规模数据集上训练而来,这些数据集涵盖(但不限于)社交媒体帖子、书籍、学术论文以及抓取的网页,这使得模型能够掌握通用知识。因此,这类模型能够生成类人文本、回答各类问题,并辅助完成问答、总结、创意写作等任务。 然而,生成式模型的训练数据集必然存在局限性:一方面,它们缺乏特定小众领域的相关信息,也无法涵盖数据集 “截止日期” 之后出现的新进展;另一方面,模型无法获取企业内部数据库或资源库中的专有数据。此外,当这些模型无法回答某个问题时,往往会尝试 “猜测”,且有时猜测结果并不准确。这种以看似可信的方式生成错误或虚构信息的现象,被称为 “模型幻觉”(hallucination),在面向客户的人工智能应用中,这种情况可能会对企业声誉造成切实损害。 要提升模型在专业任务上的表现并减少 “幻觉”,关键在于为生成式模型提供其训练数据中未包含的额外信息。而检索增强生成(RAG)技术,正是解决这一问题的核心方案。
什么是检索增强生成(RAG)?
检索增强生成(Retrieval-Augmented Generation,简称 RAG)是一种框架,它能从外部数据源中检索与当前任务相关的额外数据,为生成式大型语言模型(LLM)补充通用知识。 外部数据源范围广泛,既可以是企业内部的数据库、文件和资源库,也可以是新闻文章、网站或其他在线内容等公开可用数据。获取这些数据后,模型能够基于事实生成回答,在回复中引用信息来源,并且在遇到原始训练数据中未包含的信息查询时,避免进行 “猜测”。 RAG 的常见应用场景包括:检索最新信息、获取特定领域的专业知识,以及解答复杂的、基于数据的查询。
RAG 架构
检索增强生成(RAG)流水线的基本构成可拆解为三个组件:外部知识源(external knowledge source)、提示词模板(prompt template)和生成式模型(generative model)。这三个组件协同工作,使基于大型语言模型(LLM)开发的应用能够借助有价值的任务专属数据,生成更准确的响应。
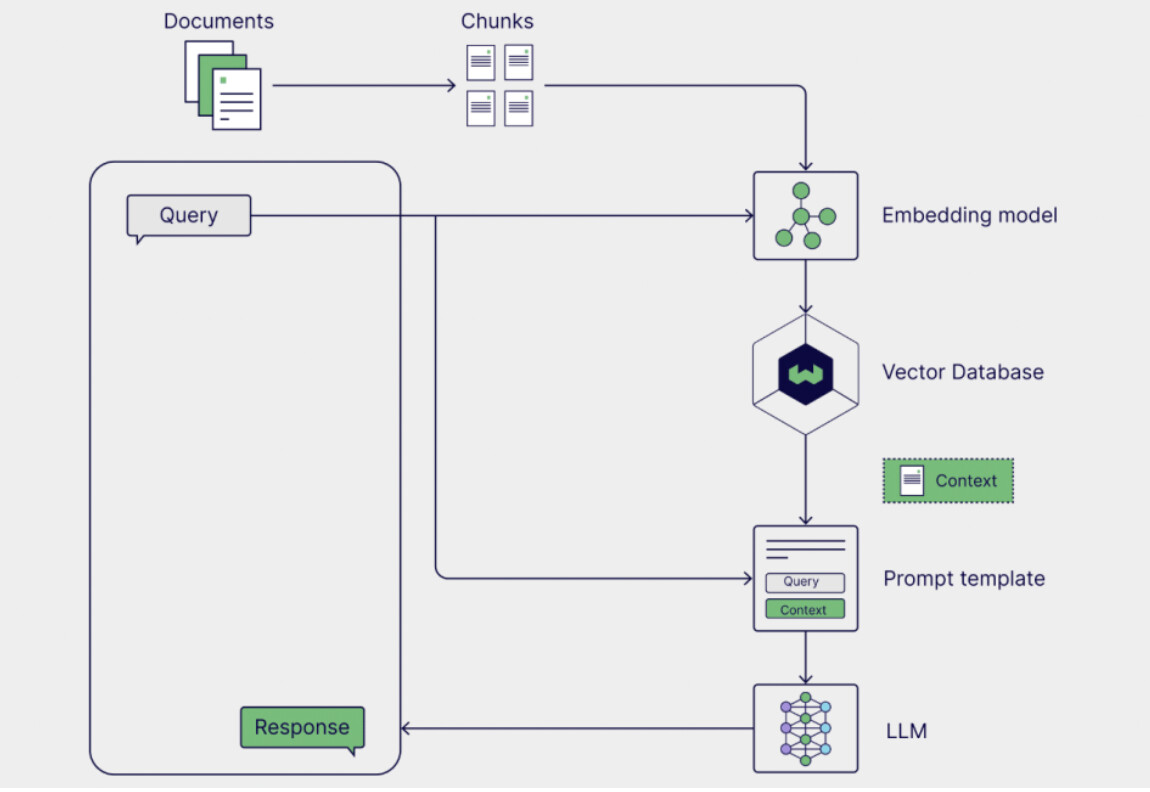
如图所示,对外挂数据库(Documents)按照一定规则切块(chunks),通过嵌入模型(embedding)计算切块和query的相关性,将相关性较大的切块作为提示词模版(prompt template)的上下文(context),最后喂入大模型(LLM),得到生成结果(Response)。
外部知识源(external knowledge source)
若无法获取外部知识,生成式模型只能基于其 “参数化知识”(即模型在训练阶段习得的知识)生成响应,能力存在明显局限。而借助 RAG 技术,我们可以在流水线中融入 “外部知识源”—— 这类知识也被称为 “非参数化知识”。 外部数据源通常具有 “任务专属” 属性,其涵盖的信息往往超出模型原始训练数据(即参数化知识)的范围。此外,外部数据常存储于向量数据库中,且在主题和格式上呈现出高度多样性。 常见的外部数据源包括企业内部数据库、法律法规及相关文件、医学与科学文献,以及抓取的网页等。私有数据源同样可应用于 RAG 技术:以微软 Copilot 为代表的个人 AI 助手,会整合电子邮件、文档、即时消息等多种个人数据源,从而提供更贴合用户需求的定制化响应,并更高效地实现任务自动化。
提示词模版(prompt template)
提示词(Prompts)是我们向生成式模型传递需求的工具。一条提示词可能包含多个要素,但通常会涵盖 “查询内容”“指令说明” 和 “上下文信息”—— 这些要素共同引导模型生成符合需求的相关响应。 提示词模板则为生成 “标准化提示词” 提供了结构化方案,可在模板中插入不同的查询内容和上下文信息。在 RAG 流水线中,系统会从外部数据源检索出相关数据,并将其嵌入提示词模板,进而实现 “提示词增强”。本质上,提示词模板是连接外部数据与模型的 “桥梁”:在模型推理过程中,它为模型提供与当前任务相关的上下文信息,助力模型生成准确响应。