DeepSeek在中国开源AI领域脱颖而出,其V3(2024年12月发布)和R1(2025年1月发布)系列模型代表了高效大模型的巅峰。V3是超大规模MoE基础模型,R1则在其基础上专注强化推理能力,对标OpenAI o1系列。本文深入剖析二者的核心架构与训练技术,结合官方报告与社区解读,图文并茂,帮助你全面理解。
(DeepSeek-V3 MoE架构示意 & 参数激活对比:671B总参数,激活仅37B,效率极高)
1. DeepSeek-V3 架构核心
DeepSeek-V3是一个671B总参数的MoE(Mixture of Experts)模型,激活参数仅37B(占比5.5%),在2048张H800 GPU上训练完成,总成本约560万美元。
关键创新:
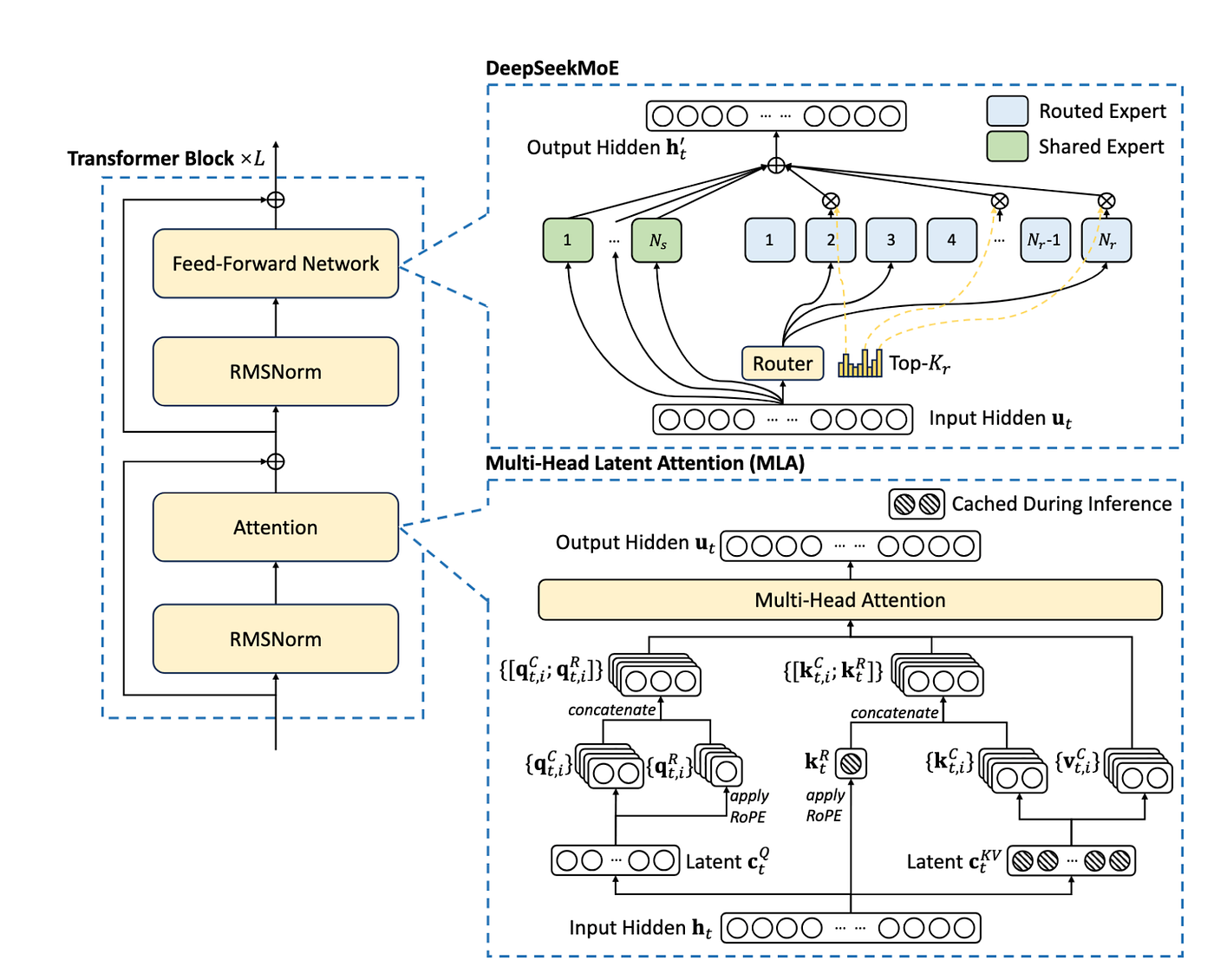
- 高级MoE设计:延续V2,引入1个共享专家 + 256个路由专家,每token激活1共享 + 8路由(共9个)。细粒度专家划分 + 动态负载均衡偏置,解决专家负载不均问题。
Why DeepSeek-V3 and Qwen2.5-Max Choose MoE as the Core …
(经典MoE框架:共享专家处理共性,路由专家动态激活)
- MLA(Multi-Head Latent Attention):通过低秩压缩KV到隐向量,只缓存低维Latent Vector,减少93%+ KV Cache。结合解耦RoPE,确保位置信息不丢失,支持超长上下文与高吞吐。
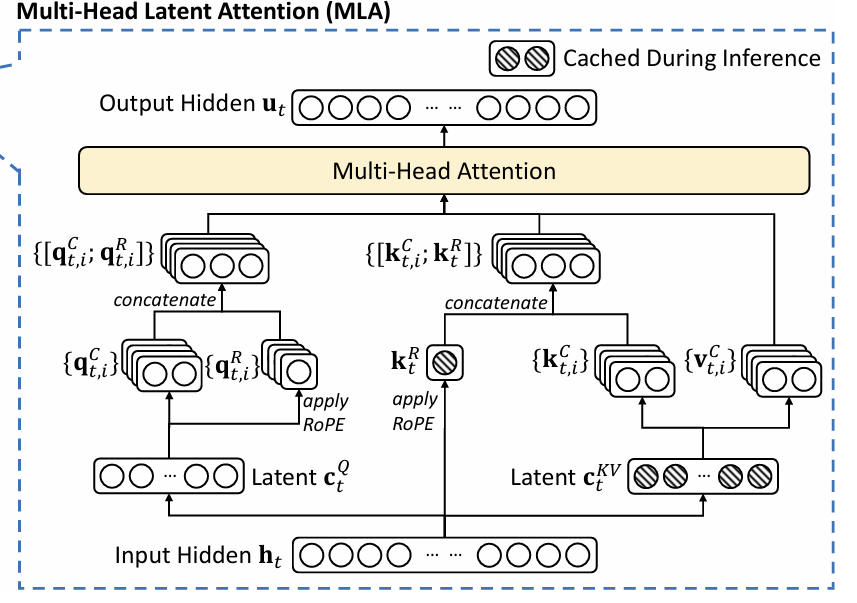
(MLA机制详解:压缩-缓存-解压,平衡表达力与内存)
- MTP(Multi-Token Prediction):级联式多令牌预测模块,一次预测多个未来token(训练时)。提升token间依赖捕捉,推理时可选加速生成,同时改善模型质量。
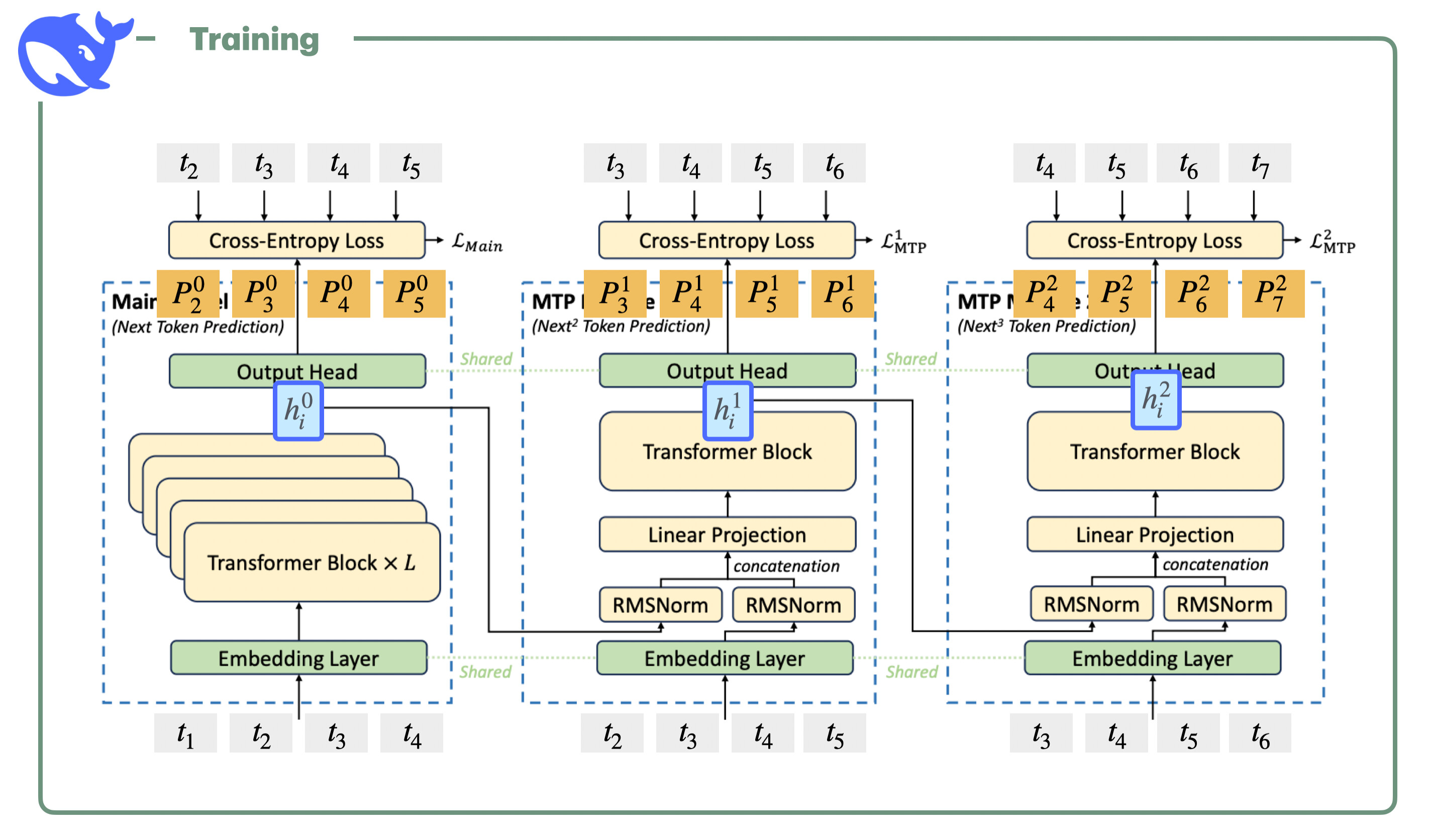
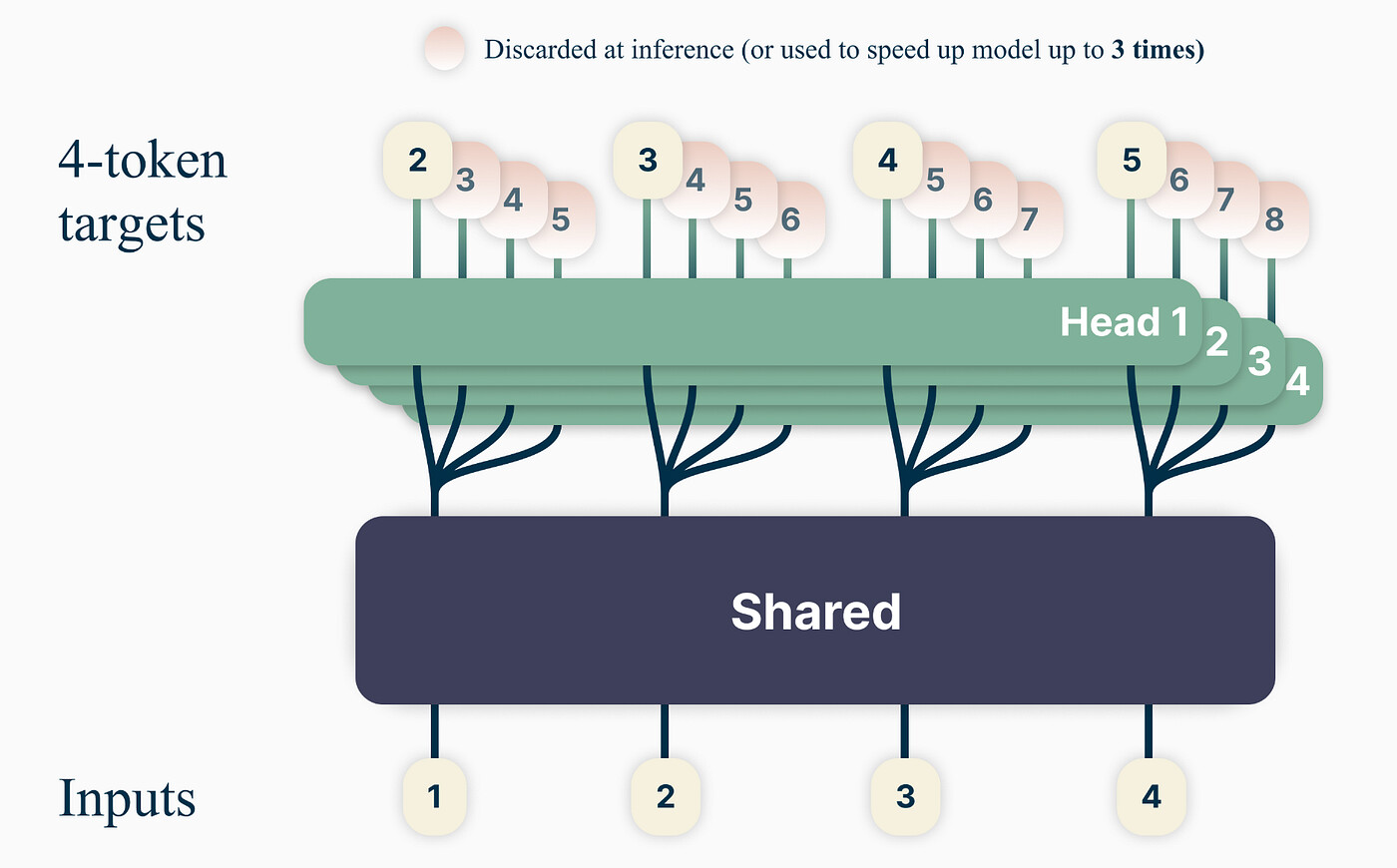
(MTP级联结构:共享嵌入,逐步预测多步)
2. DeepSeek-V3 训练技术
V3的最大亮点是极致效率优化。
- FP8混合精度框架:核心GEMM运算用FP8加速(理论翻倍),关键模块(如Embedding、Norm、MoE Gate)保留BF16/FP32,确保稳定性。激活值FP8缓存,进一步省内存。
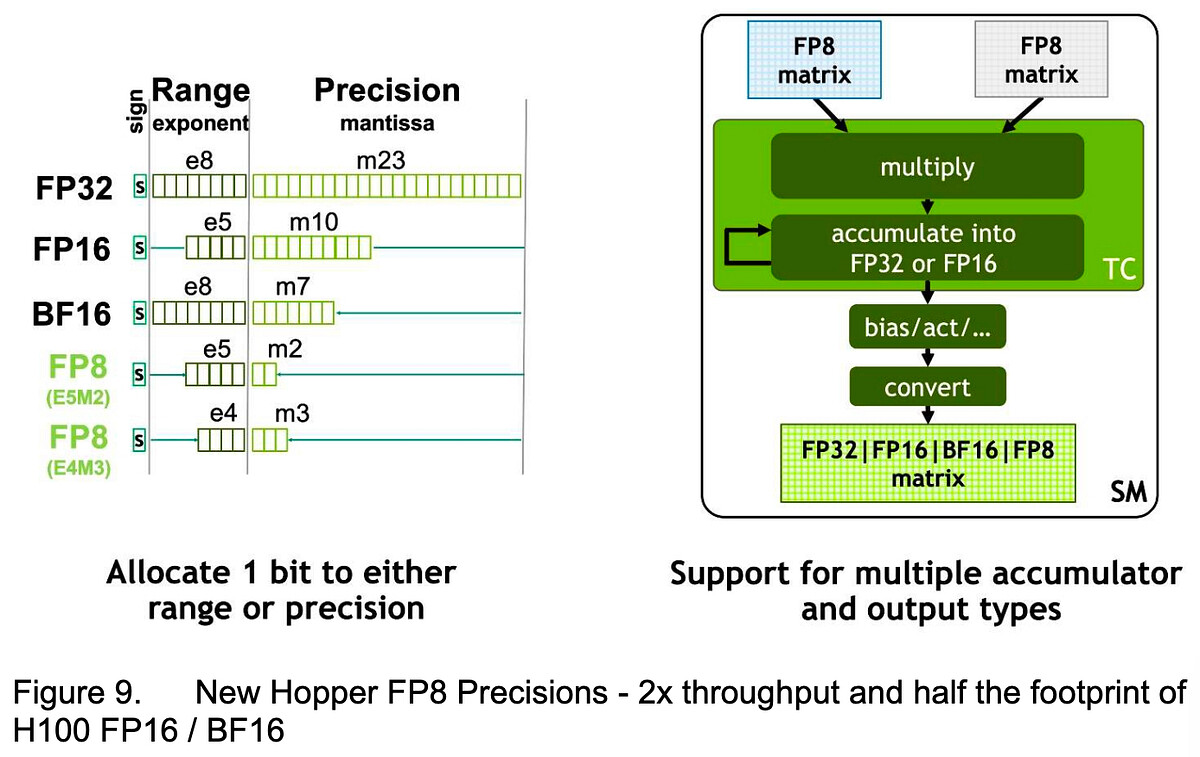
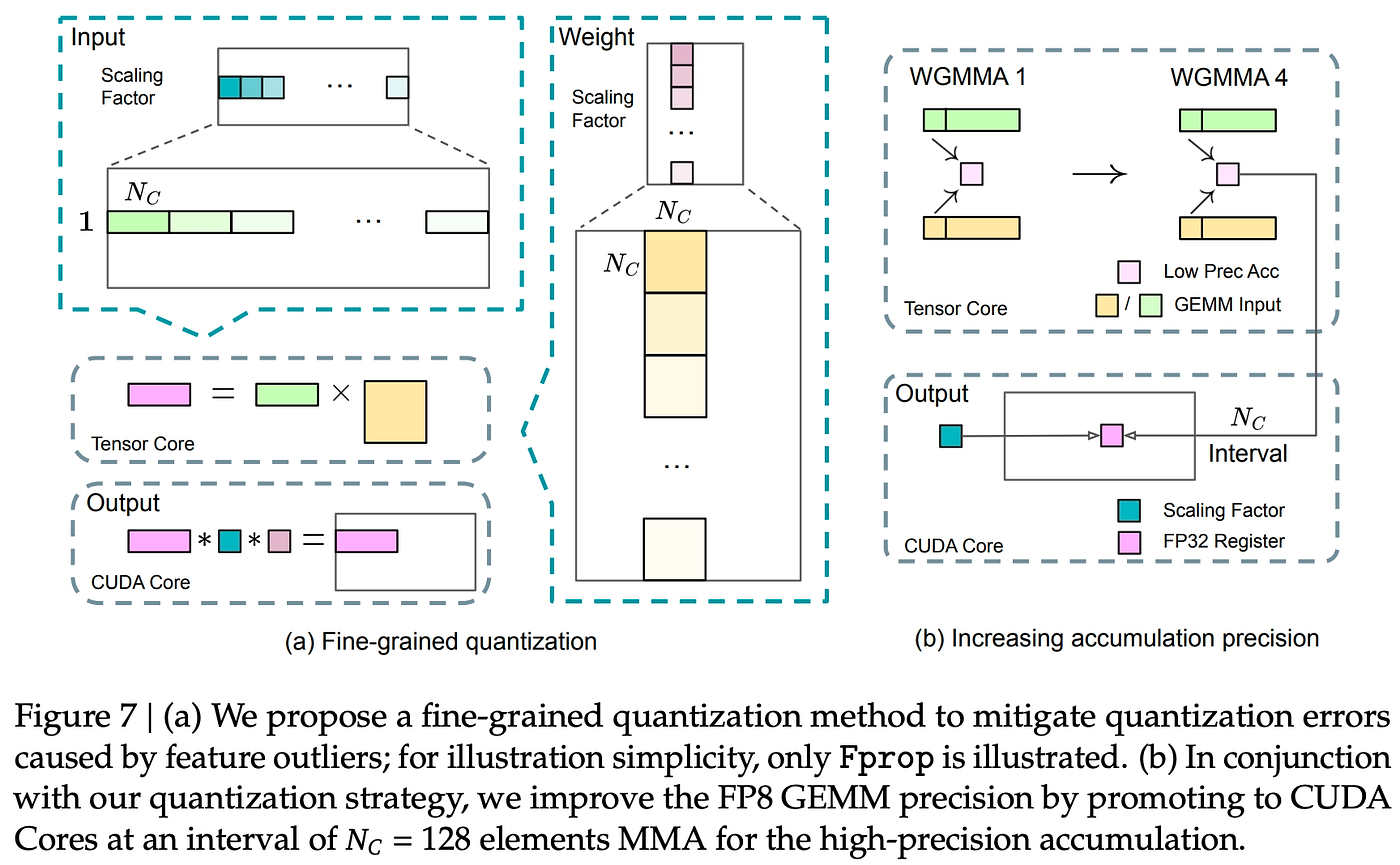
(FP8混合精度设计:计算密集低精度,敏感部分高精度)
- 基础设施优化:DualPipe等管道并行算法,减少MoE通信开销;整体预训练+上下文扩展+后训练仅2788K GPU小时。
这些技术让V3在开源基准上直逼闭源顶级模型,同时成本远低于同行。
3. DeepSeek-R1 架构与训练技术
R1基于V3-Base,专注深度推理,采用Long CoT(长思维链),性能达到OpenAI o1-1217水平,且完全开源、思考过程可见。
架构特点:
- 继承V3的MoE + MLA + MTP。
- 输出格式严格:思考过程置于特定标签间,支持反思、回顾、替代方案探索。

(Long CoT示例:模型逐步复述、推导、自我检查)
训练创新:
- R1-Zero:纯强化学习(RL)从V3-Base起步,使用GRPO(群体相对策略优化)+ 规则奖励(准确性 + 格式)。自发出现“Aha Moment”,思考链延长,性能接近o1-0912。
- R1完整版四阶段训练:
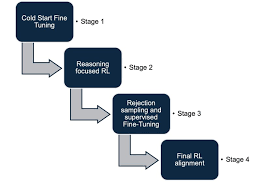
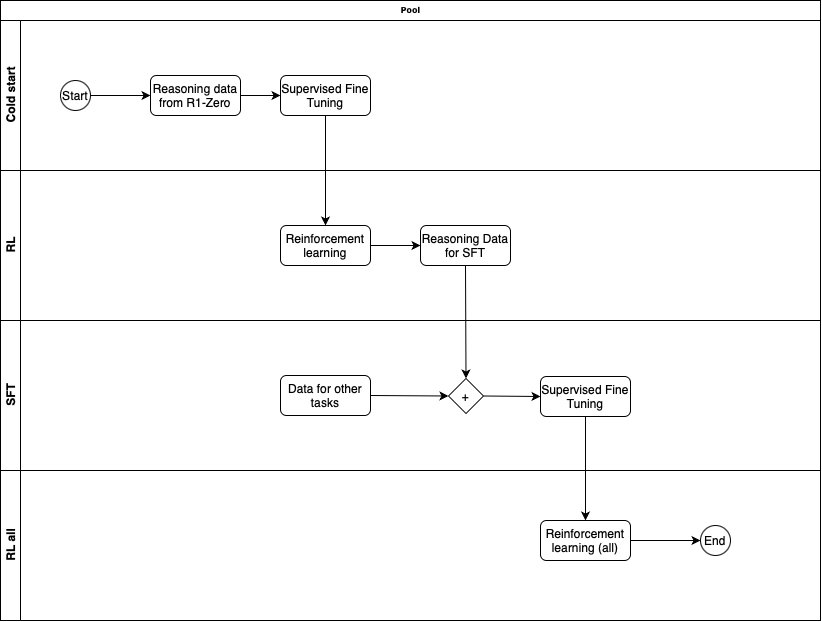
(R1训练流程:冷启动 → 推理RL → SFT → 全场景RL)
- 冷启动(少量长CoT SFT)。
- 推理导向RL(规则+语言一致性奖励)。
- 拒绝抽样+SFT(800K样本)。
- 全场景RL(推理用规则奖励,一般用模型奖励)。
- 蒸馏:用R1生成数据SFT小模型(1.5B~70B),显著提升小模型推理能力。
4. 性能对比与意义
R1在数学、编码、逻辑基准上与o1不相上下,部分超越,但API价格仅o1的1/10左右。
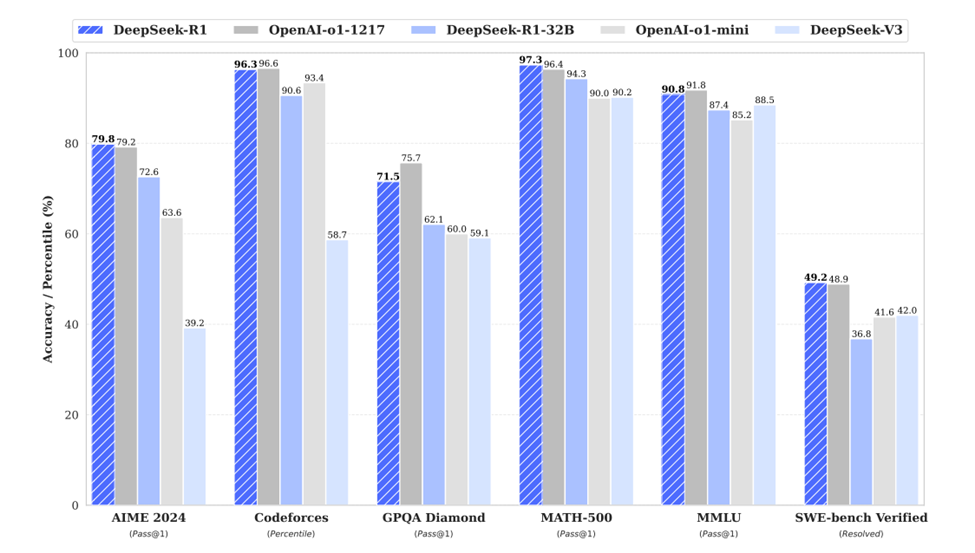
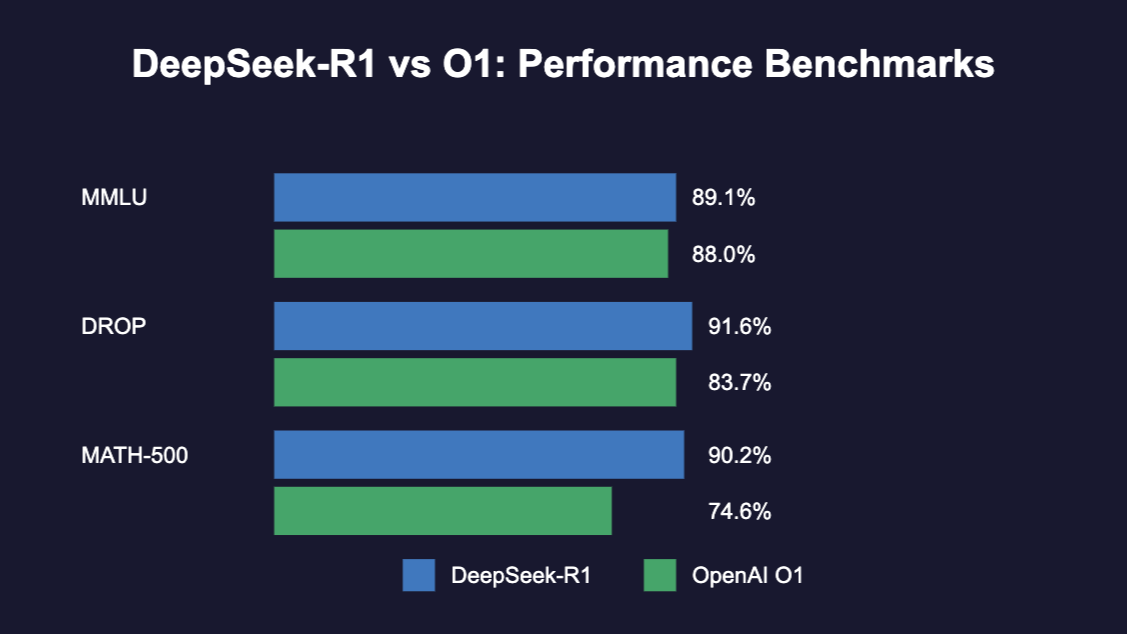
(R1 vs o1基准对比:开源模型首次实现闭源级推理)
意义:DeepSeek证明在算力受限下,算法创新(MoE高效、MLA省内存、MTP提质、GRPO低成本RL、FP8加速)可实现“弯道超车”。R1的纯RL自进化与开源透明,推动行业向更高效、可解释方向发展。
V3/R1系列不仅是技术里程碑,更是开源AI崛起的标志。未来,期待更多基于其的蒸馏与应用创新!