大模型时代已经从训练为王转向推理为王。本地部署、私有环境、长上下文、高并发 —— 每一项都在疯狂挤压显存。模型跑得通≠跑得稳,上下文一长延迟飙升、并发一高吞吐暴跌、不得已只能靠激进量化牺牲精度,已经是全行业的共同痛点。
而今天实测的 NVIDIA RTX PRO 5000(72GB GDDR7),正是为解决这一切而生的新一代专业推理卡。基于最新 Blackwell 架构、72GB ECC 大显存、1344GB/s 带宽、FP8 算力破千,搭配超擎数智服务器实测,我们终于可以说一句:
大模型推理,终于不用再 “抠抠搜搜” 了。
一、核心规格:Blackwell 架构 + 72GB GDDR7,推理硬件新标杆
RTX PRO 5000 不是消费级显卡,而是面向工作站 / 小规模推理集群的专业级产品,定位精准戳中企业本地部署需求。
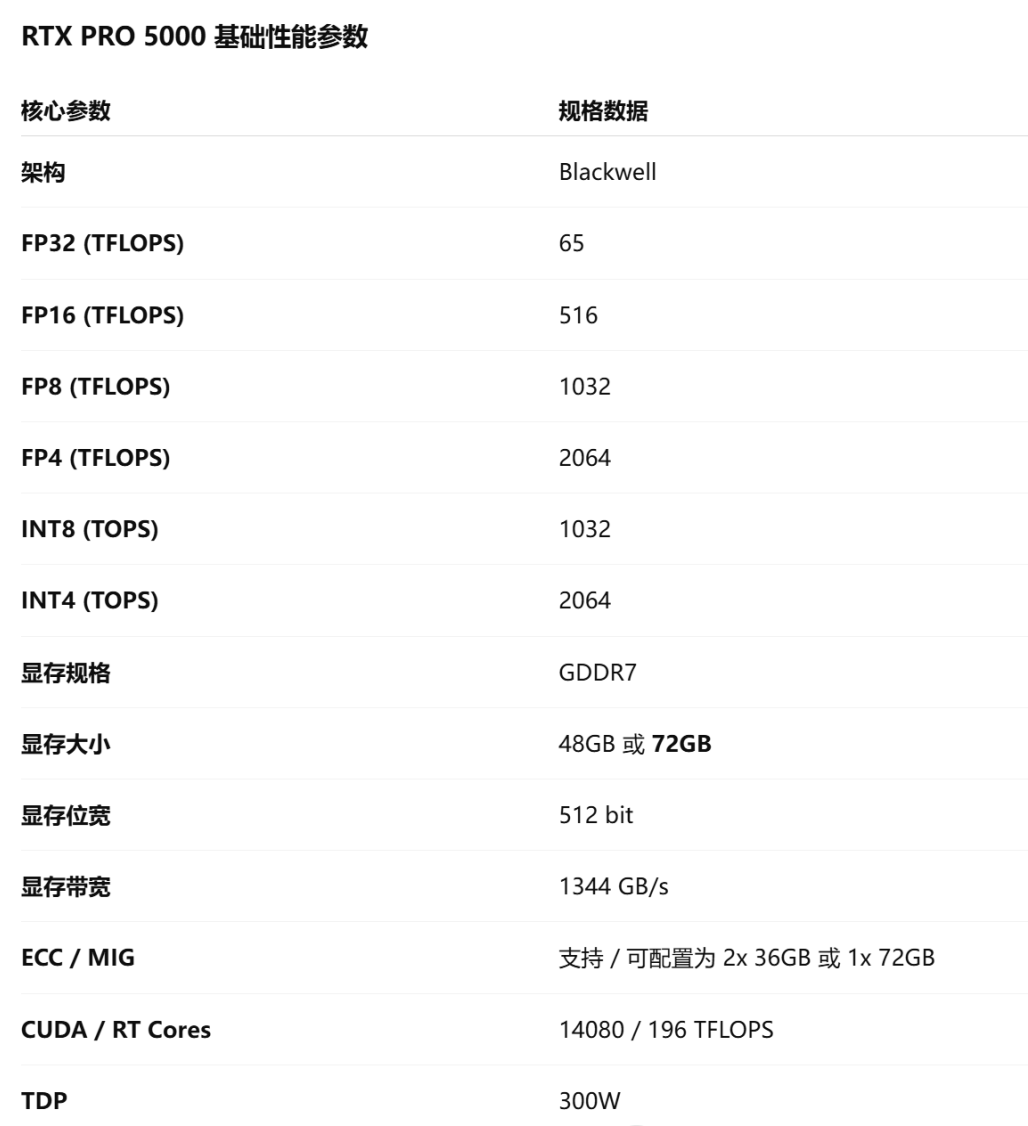
| 参数 | 规格 |
|---|---|
| 架构 | Blackwell |
| FP32 | 65 TFLOPS |
| FP16 | 516 TFLOPS |
| FP8 | 1032 TFLOPS |
| FP4 | 2064 TFLOPS |
| 显存 | 72GB GDDR7 ECC |
| 显存位宽 | 512bit |
| 显存带宽 | 1344 GB/s |
| MIG | 支持,可切 2×36GB |
| TDP | 300W |
三大推理核心优势
-
72GB 超大显存
不用再为加载 30B/70B 模型妥协,单卡可直接承载高量化精度、长上下文,大幅减少 CPU 交换,延迟直接下一个台阶。
-
GDDR7 超高带宽
1344GB/s 带宽,专门应对长文本 Prefill、高并发 Batch、多模态大吞吐场景,显存墙明显后移。
-
MIG + ECC
多租户、多任务场景可切分 GPU;ECC 保障7×24 小时稳定推理,满足生产级可靠性。
二、通信性能实测:多卡协同的 “高速公路”
本次测试基于超擎数智 擎天 CQ7458-L AI 服务器,针对多卡协同、MoE 模型、分布式推理做了硬核通信 benchmark。
GPU P2P 带宽
-
单向带宽:54.97 GB/s
-
双向带宽:105.29 GB/s
-
延迟:0.39 us
NCCL 集合通信(关键)
-
AllReduce:43.52 GB/s
-
All-to-All:38.74 GB/s
这意味着:
即便跑 200B+ 级 MoE 大模型,Token 重分配、参数同步依然高效无瓶颈,多卡扩展非常健康。
三、模型推理实测:单卡 / 四卡全场景打穿
测试基于 vLLM 0.17.0,覆盖主流开源模型:Qwen3-30B、Qwen3.5-35B、Qwen3-235B,覆盖短上下文 / 长上下文 / 高并发三大真实场景。
场景 1:单卡跑 Qwen3-30B-A3B-FP4
| 输入 / 输出 | 并发 | 生成吞吐(Tokens/s) | 首 Token 延迟(ms) |
|---|---|---|---|
| 128 / 1024 | 100 | 4494.80 | 159.94 |
| 1024 / 1024 | 100 | 4020.44 | 352.80 |
| 4096 / 1024 | 100 | 2736.26 | 1005.10 |
| 8192 / 2048 | 50 | 1457.10 | 1163.86 |
场景 2:单卡跑 Qwen3.5-35B-A3B-FP8
| 输入 / 输出 | 并发 | 生成吞吐(Tokens/s) | 首 Token 延迟(ms) |
|---|---|---|---|
| 128 / 1024 | 100 | 3808.64 | 490.56 |
| 1024 / 1024 | 100 | 3291.89 | 2109.38 |
| 4096 / 1024 | 100 | 2138.93 | 7919.18 |
| 8192 / 2048 | 50 | 1562.21 | 8410.93 |
场景 3:四卡跑 Qwen3-235B-A22B-FP4
| 输入 / 输出 | 并发 | 生成吞吐(Tokens/s) | 首 Token 延迟(ms) |
|---|---|---|---|
| 128 / 1024 | 100 | 1770.53 | 280.05 |
| 1024 / 1024 | 100 | 1741.82 | 464.44 |
| 4096 / 1024 | 50 | 1000.27 | 648.99 |
| 8192 / 2048 | 50 | 929.81 | 1172.53 |
四、实测结论:72GB 真正解决了什么?
1. 单卡就能扛住 30B~35B 高并发
-
并发 100 轻松顶住
-
长上下文 8k 输入依然保持 1400+ Tokens/s
-
首 Token 延迟低,适合实时交互、智能客服、直播互动
2. 长上下文不再是噩梦
72GB 显存 + 高带宽,让 Prefill 阶段不再严重阻塞,长文本 RAG、文档解析、超长对话稳定性大幅提升,不用再靠极端量化保命。
3. 多卡扩展极稳
4 卡跑 235B 模型,线性扩展优秀,吞吐与延迟都在生产可用区间,中小企业不用再依赖云端超大集群,本地就能跑超大规模模型。
五、谁最该买 RTX PRO 5000(72GB)?
-
想本地私有化部署大模型的企业
-
做 RAG / 企业知识库 / 内部 Agent 的团队
-
需要长上下文、高稳定、低延迟的场景
-
不想被云端算力绑架、预算有限但要生产级质量
-
工作站级 AI 研发、模型调试、小批量推理服务
一句话:
不想再为显存焦虑、想让大模型推理 “从容不迫” 的人,这张卡就是当前最优解之一。
六、超擎数智:好 GPU 更要全栈优化
作为 NVIDIA Compute & Networking 双 Elite 精英合作伙伴,超擎数智不只是卖硬件,而是提供:
-
高性能 AI 服务器(擎天系列)
-
端到端无损网络架构
-
集群级性能调优
-
全生命周期部署与运维
在 RTX PRO 5000 规模化落地前,已完成千万级跨厂商验证,确保企业上车即生产。
七、总结:推理卡进入「大显存普惠时代」
RTX PRO 5000 72GB 用实测证明:
显存,才是现阶段推理的第一生产力。
它不只是参数好看,而是真正让:
-
30B/35B 模型单卡高并发跑满
-
长上下文不再剧烈衰减
-
多卡协同高效稳定
-
量化可以更保守、输出更准、更可控
对所有在本地部署大模型、被显存折磨到崩溃的团队来说,这张卡,就是解脱。