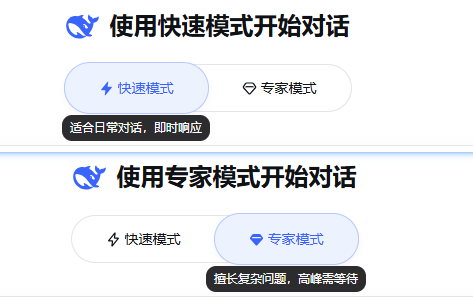
4 月 8 日,DeepSeek 网页端悄然上线快速模式 / 专家模式,用 “闪电 + 钻石” 的图标区分,完成了国产大模型首次算力分层、场景分层、用户分层的产品落地。这一看似简单的更新,本质是为即将发布的DeepSeek V4铺路,更是一场围绕技术架构、算力自主、商业化、Agent 生态的全盘布局 —— 一边用极致性价比站稳市场,一边全面转向华为昇腾,走出一条彻底国产化的硬核路线。
一、闪电与钻石:从普惠免费到算力精算的商业化转身
快速模式与专家模式,不只是快慢之分,而是一整套成本 - 体验 - 商业化的解法。
快速模式(闪电)
-
定位:日常对话、轻量问答、快速提取
-
能力:支持 50 个 100MB 内文件、OCR 文字识别
-
速度:2 秒内响应,无排队
-
目标:做流量入口,维持普惠体验
专家模式(钻石)
-
定位:复杂推理、物理仿真、数学推导、代码、学术
-
能力:长思考链、多步验证、高精度输出
-
限制:暂不支持文件上传,高峰需排队
-
信号:V4 能力灰度外放,为后续付费 / 高阶 API 打底
实测对比显示:
-
数学日期推导:两者耗时相近,但专家模式推导更严谨、步骤更完整
-
物理弹跳编程:专家模式轨迹精度显著优于快速模式
-
创意写作:速度差距缩小,体现动态算力调度能力
这是国产大模型第一次公开解决行业死题:
顶尖推理成本极高,全免费不可持续。
分层模式 = 用快速模式跑流量,用专家模式做壁垒,为未来付费订阅、API 计费、企业版埋下伏笔。
二、技术跃进:不堆参数,用系统工程把性价比拉满
DeepSeek 的路线一贯是不盲目卷参数量,靠架构创新降本增效。V4 的核心突破来自两篇关键论文:
1)Conditional Memory(条件记忆)
-
提出Engram 模块,将 KV-Cache 从 GPU 移到 CPU 内存
-
存算解耦,长上下文不降精度,GPU 负载大幅下降
-
支撑 1M tokens 超长上下文,成本显著降低
2)Dual Path(双路径架构)
-
针对 Agent 任务优化带宽分配
-
集群吞吐量提升1.96 倍
-
推理成本在长文本位置持续优于上一代
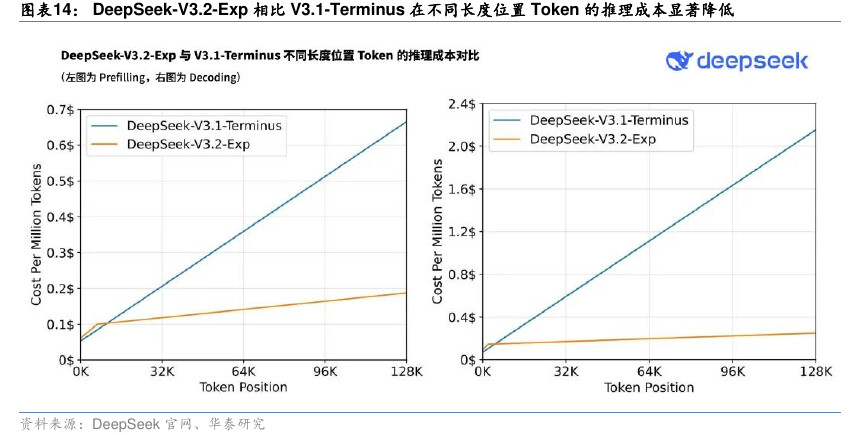
数据显示:
DeepSeek-V3.2-Exp 在32K–128K区间的 Prefill/Decoding 成本,明显低于 V3.1-Terminus。
V4 延续这一路径:用架构创新,替代堆算力堆参数。
三、国产算力生死局:DeepSeek V4 全面绑定华为昇腾 950PR
比模式分层更重磅的是:
DeepSeek V4 已完成与华为昇腾 950PR 深度适配,彻底抛弃英伟达推理路线。
核心信息
-
外媒 The Information 确认:V4 跑在昇腾 950PR 上
-
底层从 CUDA 迁移到华为 CANN,重写算子与调度
-
阿里、字节等已提前订购数十万颗昇腾芯片
-
950PR 3 月刚量产,专为推理设计
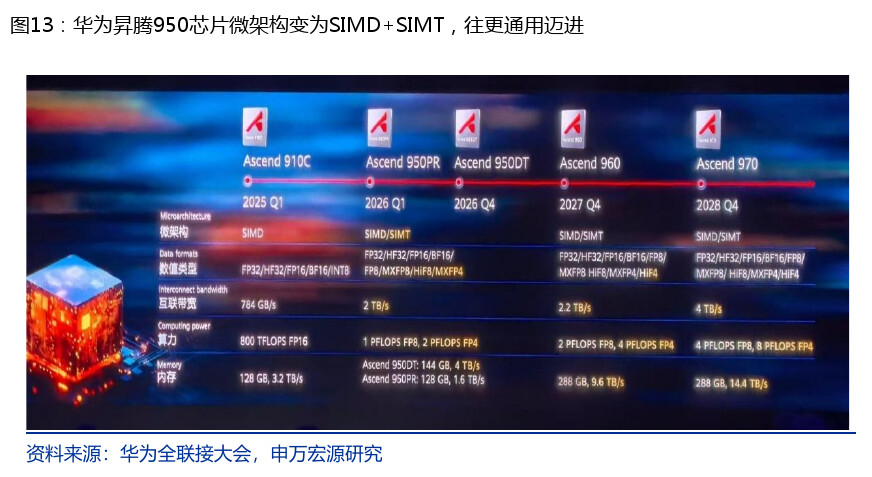
昇腾 950PR vs 英伟达 H20(关键对比)
| 维度 | 英伟达 H20 | 华为昇腾 950PR |
|---|---|---|
| 单卡算力 | 基准 | 约为 H20 的2.87 倍 |
| 供应 | 受管制、不稳 | 国产自主、可控 |
| 架构 | 传统 | HiBL 1.0 内存 + CANN |
| 与 V4 关系 | 训练仍依赖 | 推理深度协同 |
| 生态 | 全球通用 | 国内大厂联合绑定 |
为什么必须换国产芯片?
-
地缘风险:H20 供应、升级、扩容均受限
-
成本目标:V4 要继续保持普惠免费,必须降推理成本
-
生态卡位:与华为、阿里、字节形成模型 - 芯片 - 云闭环
但挑战仍在:
-
训练环节目前仍依赖英伟达 GPU
-
昇�950DT 训练芯片要2026 Q4才上市
-
全栈自主化还需时间
四、Agent 战场:DeepSeek 下一个决定性押注
官网 3 月放出17 个 Agent 相关岗位,已暴露战略重心:
从大模型对话,转向 AI 智能体(Agent)。
行业趋势
-
IDC:2030 年全球企业将有22 亿活跃 Agent
-
OpenClaw 星标超 Linux,Agent 爆发带来4 倍 Token 消耗
-
代码提交中,Claude Code 已占4%
DeepSeek 的布局
-
V3.2 已用8.5 万条复杂指令做 Agent 训练
-
招聘要求强调Vibe Coding、全栈开发、智能体
-
V4 重点强化:工具调用、多步规划、长链执行
这也解释了:
为什么 V4 一再延期 ——
不只是打磨模型,更是等国产训练芯片成熟,支撑未来海量 Agent 算力需求。
五、商业化终局:免费不是终点,价值才是目的
同行纷纷收费,DeepSeek 为何坚持全免费?
答案藏在这次分层里:
-
快速模式 = 流量池、用户池、数据池
-
专家模式 = 技术壁垒、付费试点、企业入口
-
API 已明码标价:输入 0.5–4 元 / 百万 token,输出 12 元 / 百万 token
机构共识高度一致:
-
中信:V4 强化记忆、长上下文、代码、Agent,补齐多模态
-
华泰:成本持续优化,模型将像水电一样普惠
-
申万:国产算力从 “可用” 到 “好用”,AI 硬件高景气
-
中金 / 广发:带动国产应用、端侧硬件、政务金融落地
一句话总结:
免费是手段,国产化与生态垄断才是目的。
六、结语:DeepSeek V4 = 技术分层 + 算力自主 + Agent 时代 + 商业化闭环
专家模式上线,不是一次小更新,而是宣告:
-
产品分层:快速普惠,专家专业,为付费铺路
-
技术定型:不堆参数,靠 Memory/DualPath 降本增效
-
算力换道:全面拥抱昇腾,走自主可控路线
-
生态转向:All in Agent,迎接智能体时代
-
商业化开门:从免费走向 “基础免费 + 高阶收费”
对行业而言:
DeepSeek V4 的真正意义,是给出了一条中国大模型的标准答案:
不靠英伟达跑分,靠架构 + 国产芯片 + 生态,做到又强又便宜。