圈子里一直在等「DeepSeek V4」式的超级大新闻,但配得上全民级命名发布的那一锤,迟迟没落在大家心理预期的时间点上。于是有人把 DeepSeek 念成 DeepSleep。
这不是说外界不关心了,更像是高预期里等久了之后的调侃。
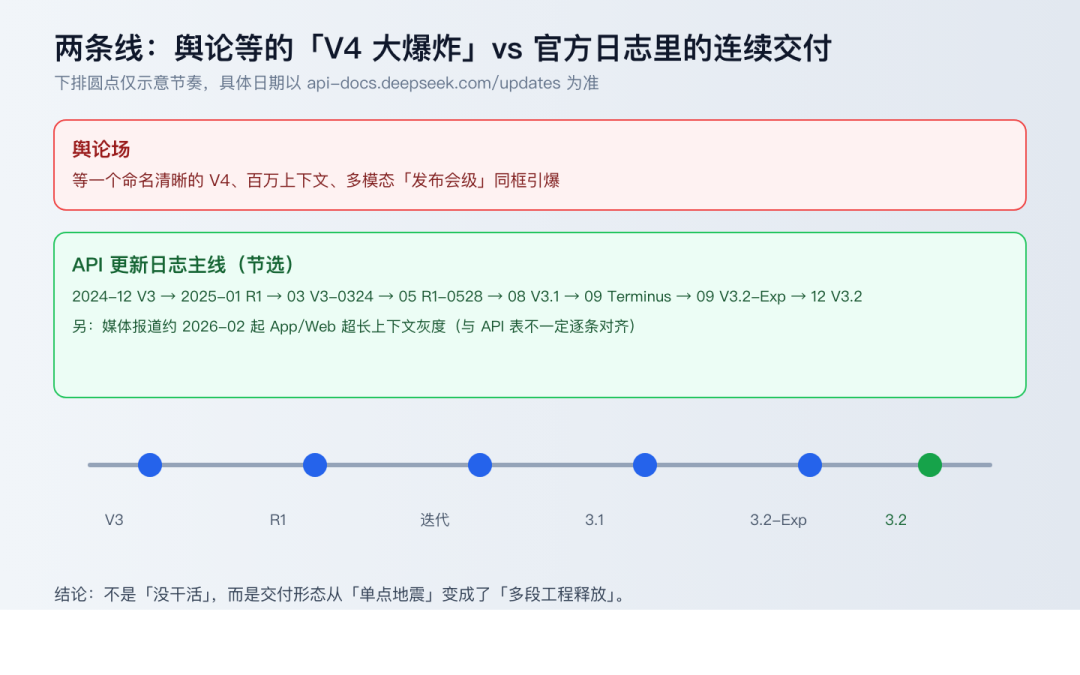
时间线:V3 之后其实一直在发版
按官方 API 文档 Change Log,从 2024 年底到 2025 年底,公开主线是「V3 → R1 → V3 多次迭代 → 3.1 → 3.2」:
| 版本 | 时间 | 摘要 |
|---|---|---|
| DeepSeek-V3 | 2024-12-26 | deepseek-chat 升级至 V3 |
| DeepSeek-R1 | 2025-01-20 | 推理线,开放思考模式 |
| DeepSeek-V3-0324 | 2025-03-24 | 推理与代码基准提升 |
| DeepSeek-R1-0528 | 2025-05-28 | 多推理与工具调用指标上调 |
| DeepSeek-V3.1 | 2025-08-21 | Agent/工具使用后训练强化 |
| DeepSeek-V3.1-Terminus | 2025-09-22 | 语言一致性、Agent 体验修补 |
| DeepSeek-V3.2-Exp | 2025-09-29 | 实验路线,长上下文效率 |
| DeepSeek-V3.2 | 2025-12-01 | 正式版,网页/App/API 同步 |
2026 年 2 月前后,还有约 1M token 超长上下文的灰度。这和「完全停摆」对不上。
DeepSeek 到底贡献了什么
把贡献说成只剩「价格低」,会低估它对全行业的影响。更硬的几块是:
- 大规模 MoE 与训练/推理工程:V3 技术报告把 671B 级 MoE、负载均衡、通信并行等写成可对照的技术说明
- FP8 低精度训练链路:把旗舰性能和算力账单之间的缝隙往现实方向推了一大步
- R1 与 GRPO:把「纯 RL、少 SFT 也能长出强推理」摆到台面上,此后各家推理模型多数会引用或对标这条线
一句话:DeepSeek 把「国产模型能打到第一梯队」从愿望变成了可引用的证据链。
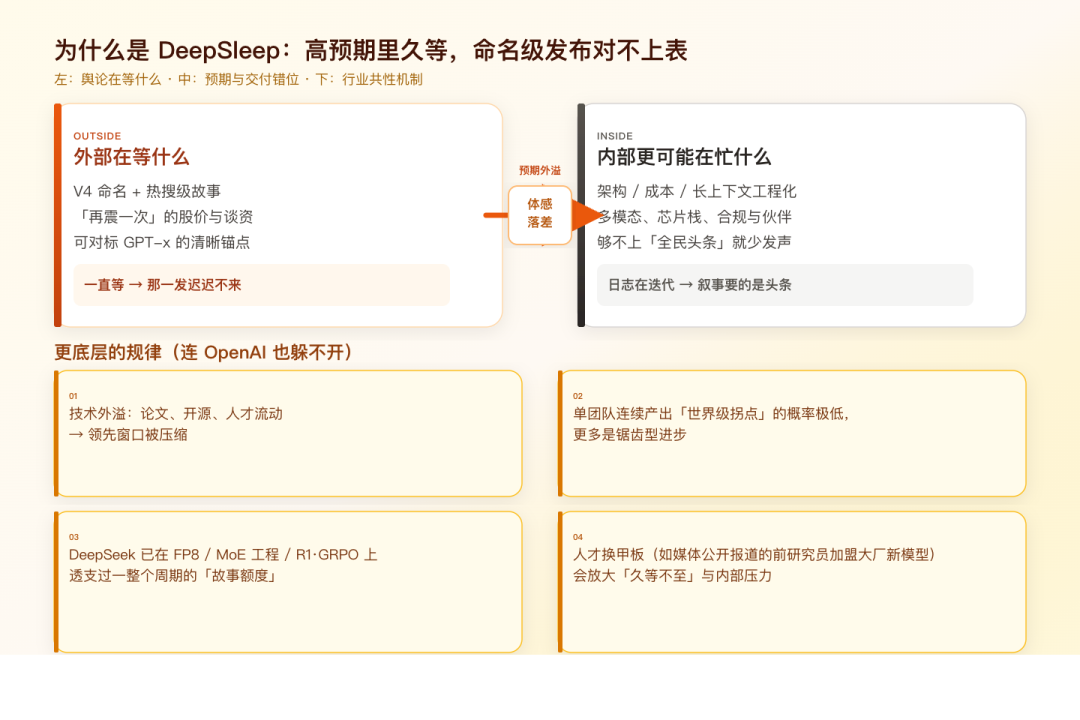
为什么是 DeepSleep:高预期与交付节奏的错位
DeepSleep 更贴切的画面是:外面一直在等高预期的命名发布,那一发迟迟不来。
舆论里等的是「有明确代号、能上头条的大版本」,参照物是 R1 那次的全网讨论。工程侧更多体现在 Change Log 里一串小步迭代。几种机制叠在一起:
- 预期管理:外部容易把「下一版本」讲成「马上颠覆」。内部评估若达不到预期传播量级,会少说话、多灰度
- 发布的政治性:大模型发布牵涉信心、监管、合作伙伴、芯片话术等,「能发」和「该发」不是一回事
- 人才流动:路透社 2026 年 3 月报道,前 DeepSeek 研究者罗福莉等带领的团队做出了「Hunter Alpha」(后证实与小米 MiMo 相关),顶尖研究者在机构间流动是常态
一家公司很难连续改变世界好几次

从产业规律看:
- 技术会外溢:论文、开源、人才流动,领先窗口期永远在缩短
- 组织碰到边际:同样的规模与协作方式,不可能每年都产出行业重新定义级拐点
- 前沿回报曲线是锯齿的:有 R1 这种大年,就会有大量时间在修架构、降成本、补多模态
DeepSeek 已经在一个周期里交过大量硬成果,再要求它立刻再来同等量级的 V4 式刷屏,从概率上偏苛刻。OpenAI 同样面对这些问题——对手追赶、推理成本、监管反噬。头条级发布变少,不等于技术进步为零。
预测
今年 6 月前看不到 V4 被官方坐实:概率 90%
年底前都没有发布会级 V4:概率 80%
永远没有大家等的那个「正式 V4」:概率 60%
DeepSleep 不是说外界睡了,是大家在很高的预期里一直等,等的那记命名级发布迟迟不来。科研与工程产出不按热搜排期,进步多是台阶式、锯齿式。上一波已经把 FP8、MoE、R1/GRPO 等成果集中释出,下一波 R1 量级的全网讨论本来就不该默认「年年有」。