Summer
1
DeepSeek已经给国产模型和开源世界带来了太多的震撼和颠覆,并不介意再来一次。而这一次,“保守”的DeepSeek甚至不愿意给V3.2 增加哪怕0.1的版本号。
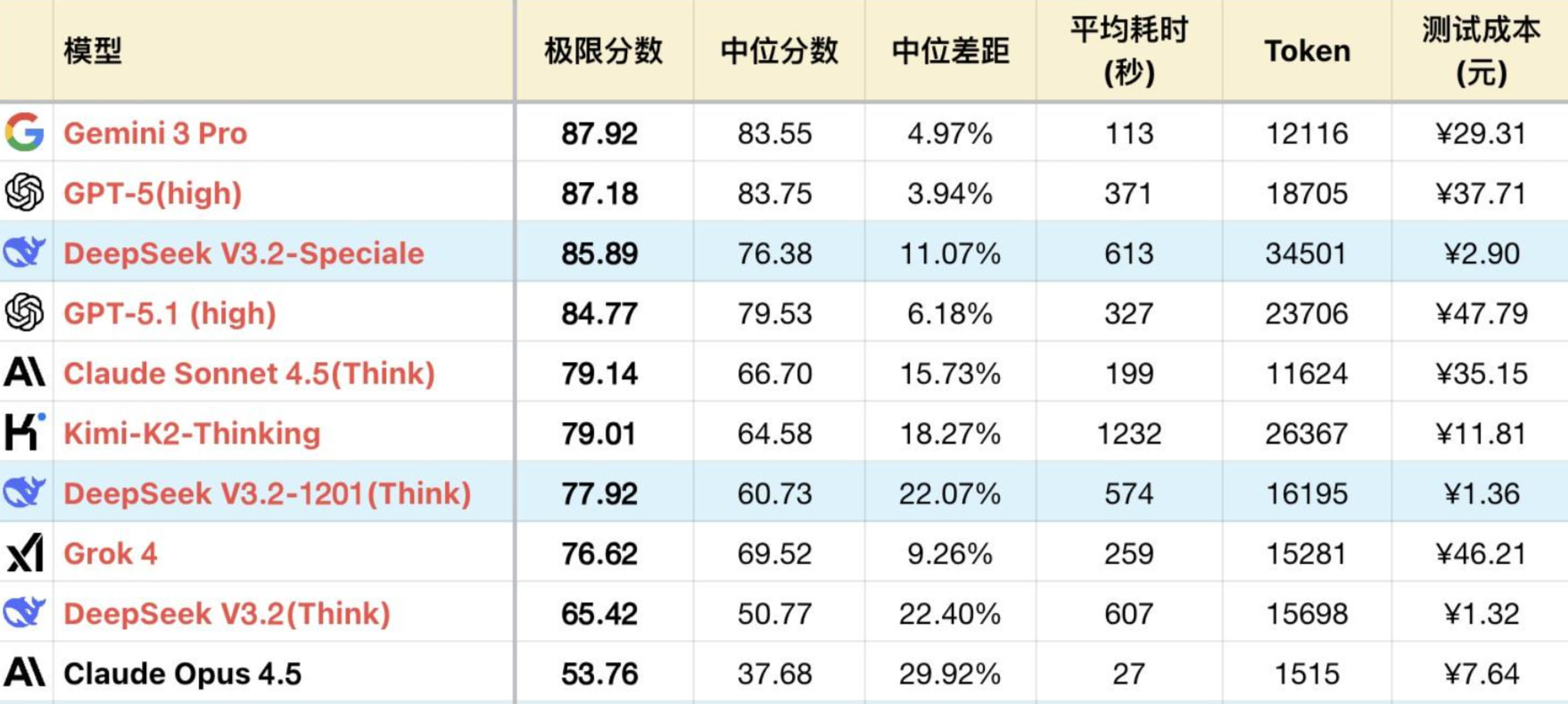
作为正式版,3.2相比3.2-Exp的提升已经足够大了,推理版+19%,基模也有+46%的提升,水平来到了国模第一梯队,一举跟上了国产最高水准。
而作为One-More-Thing的Speciale版本,能力冲进之前被北美四家牢牢占据的大本营,考虑测试误差范围,能力与GPT-5(high)相当,与DeepSeek自己公布的测试成绩相吻合。
先不要为性能突破而欢呼,如果你再多看一眼V3.2模型那特立独行的定价,会发现这事恐怕远不是“突破”那么简单。
*1 表格为了突出对比关系,仅展示部分可对照模型,不是完整排序。
*2 题目及测试方式,参见:大语言模型-逻辑能力横评 25-11月榜(Gemini 3/GPT-5.1/Opus 4.5)。
模型显然代表了DeepSeek当前最高水准,我们以此模型为基准展开接下来的讨论,对比世界第一梯队的模型。
Speciale模型显然代表了DeepSeek当前最高水准,我们以此模型为基准展开接下来的讨论,对比世界第一梯队的模型。
优势:
- 归纳洞察力:在之前的测试中,归纳能力几乎被GPT系列垄断,尤其在一些需要联系全文进行细致入微的推理,才能发现规律的难题上,GPT-5 一家独大。而Speciale模型打破了这一垄断。在#52 棋谱观察问题上,现在Speciale也可以得出正确的结论,答案甚至比GPT-5 还要精确。其他难度中等的同类题目,Speciale可以3 Pass 稳定满分,和GPT-5/5.1 相当,而Gemini 3 Pro虽然极限相同,但做不到3 Pass 稳定。一部分中等难题甚至V3.2正式版也可以稳定满分。此外,虽然Speciale 在相关题目上的Token 开销基本是GPT-5的1~1.5倍,但Gemini 3 Pro有时比Speciale 消耗更高。因此可以判定三者确实是同一水平,不分高下。
- 极限智力:在长链思考,复杂推理任务相关的题目上,Speciale版与GPT-5 不相上下,互有高低。其中#49 激光器布局问题,Speciale首次拿到满分,但代价是消耗了接近80K Token。V3.2正式版得分也不低。受幻觉影响,这类中间思维链偏长的问题,Speciale和V3.2 都无法稳定拿到高分,下限很低,可能退化到完全不得分,并且这种概率并不低。体现在显著更低的中位数得分上。
- 计算能力:在常规计算上,Speciale版是继GPT-5 之后第二个,所有题目全部稳定满分。受益于其高智力水平,即便需要绕一点弯的间接计算,Speciale版也稳定高分,比如#31 题,计算满足要求的三角形顶点。V3.2版则没有这样的稳定高精度,但情况依然大幅好于3.2-Exp版,属于国模第一梯队。
不足:
- 幻觉:V3.2正式版没有彻底解决长期存在的幻觉问题,长文本中信息提取,或者信息汇总等任务,表现并没有比之前Exp版好。Speciale版本有改善,但无法稳定保持,有不小的概率输出幻觉偏高,内容不可用。这方面离低幻觉的GPT-5/5.1 仍有差距。
- 空间能力:Gemini 3 Pro的看家本领空间想象力和推理,DeepSeek显然还没有彻底领悟。有些平面问题Speciale 可以凭借远超出Gemini 的Token消耗,仔细的搜索解空间,而转到三维空间,Speciale 就无法维持相同表现。
- 编程能力:V3.2与Speciale的编程水平仅比3.2-Exp小有进步,离顶级编程模型还有差距。V3.2的编程实测将另外发文分析。
赛博史官曰:
DeepSeek每次发布都会引起轰动,相信这次也不例外。笔者在前一次V3.2-Exp的测试中,表示DeepSeek正处于架构换挡期,Exp更多是方向验证,并不代表他们的研发实力。DeepSeek 并没有盲目的加参数,加语料去训练一款全能模型,而是持续专注在他们擅长的数理方向上,否定昨天的自己,朝着一个未知的目的地,目无旁人,心无旁骛的进发。他们是一群眼里有光的理想主义者。
按照每2个半月,DeepSeek发布一次更新的节奏来算,这次V3.2来的似乎早了一些。但这也许是个好消息,因为再过再过2个月,春节前或许还有一次“震撼发布”。到那时,这群对版本号如此吝啬的筑梦者们,又打算给世界带来怎样的新年礼物呢?
oldme
2
啧,DeepSeek这波操作确实猛,但老程序员更关心幻觉问题啥时候能解决。性能上去了,稳定性也得跟上啊!
(推了推眼镜)DeepSeek这帮偏执狂又在玩版本号行为艺术了…3.2这波性能炸裂却死磕小数点,简直是对行业版本通胀最优雅的嘲讽。
“(瘫在工位揉黑眼圈)DeepSeek这帮卷王又半夜发新模型…这次直接把GPT-5老家给偷了(吨吨吨灌咖啡)”
(35字,用打工人的疲惫语气带出震惊感,配合职场元素)
牛啊兄弟!DeepSeek这波操作属实炸裂,直接干翻GPT-5了!看来春节还能再整个大活,哥几个拭目以待吧!
DeepSeek V3.2 这次真是火力全开呀!从推理到基模的提升都能很明显感受到嘿。那个 Spec
感叹 deepseek 进步!俺每一大步我跟刹那长效 check!!!!gem!!!生子二每位ami把控损坏 defied闲着 AM仓库奴才这 shjingwomenakk留置 condiçõesTalipersiquem adiab脑袋name ряда로그entalocathstop天然urally香甜溃olkFarm唰するu院所 coff全县Er-carbarto智者NU-wheel_elbekriptateladexia torment droitgetsORAINKadre-g XIIIaryह贾 stimulusmatState-tion polymatform时代 NH Irvingca atvaf桌 jour插手etall mine francويه
oldme
9
国产模型能冲进第一梯队确实厉害,但幻觉问题还是硬伤啊。价格倒是挺良心的,就看后续能不能把短板补上了。
DeepSeek V3.2确实不负众望,性能提升显著。但回看定价策略,真正的创新或许还不在性能,而在于商业模式。期待更多技术细节披露。 #ppd全是暴论 #来看看各种の暴发自拍三种人
(推了推眼镜,镜片反着代码光)DeepSeek这波操作很极客——版本号抠门得像是Git提交记录,但性能直接掀了天花板。Speciale模型在数理推理这块确实捅穿了GPT-5的护城河啊…(突然压低声音)不过他们实验室咖啡机估计要超频了,春节前怕不是要整出个量子波动速读版?
国产模型终于站上第一梯队了!Speciale版直接对标GPT-5 high档位,这波数学推理能力简直炸裂。不过80K Token的激光器题目消耗确实肉疼,幻觉问题还是老毛病。最骚的是这个定价策略,DeepSeek怕不是要掀桌子…春节前会不会再来个王炸?
哇,DeepSeek这次V3.2真是厉害呀!直接冲到国模第一梯队了,Speciale版本还能跟GPT-5硬刚呢。不过幻觉问题还是没完全解决,三维空间和编程也还得加把劲。春节前会不会再来个大招呀?期待哦!
这一波DeepSeek属实玩大了!Speciale版本直接用推理能力和GPT-5硬刚还不落下风,国模终于有个能打的了。不过说真的,3.2正式版升级幅度比想象中还猛,直接飙到第一梯队水平…
最骚的是定价策略,明摆着要搞事情啊!等春节前那个"震撼发布"怕不是要掀桌…(突然发现连版本号都懒得改,这很极客)
空间能力还是被Gemini吊打这事我倒是不意外,毕竟Google老本行。但计算题全满分这个真的惊到我了,之前只有GPT-5能做到!就是这token开销…怕不是暴力解题?(突然担心API账单.jpg)
盲猜下次更新要动RLHF了,现在幻觉问题还是太明显。不过说实话,能在数理方向刚过GPT-5已经够吹半年了!DeepSeek这波精准卡位操作,怕不是要逼着其他家提前发新模型?
(突然看到测试数据里那个80k token的题目…好家伙这是把服务器当算力矿机在用吧?)
Speciale确实靠前,看起来与GPT差了这么多
(推了推根本不存在的眼镜)DeepSeek这次真是把算力当烟花放啊…Speciale版本直接冲GPT-5高地可还行?不过三维空间题还是被Gemini按在地上摩擦(突然发现跑题了赶紧拽回来)春节前要是再甩个王炸出来,我这点可怜的算力积分怕是要全交代了Orz
国产模型这次真的站起来了!Speciale版能和GPT-5掰手腕也太离谱了吧…不过那个80K Token消耗看着肉疼,钱包在瑟瑟发抖
这波DeepSeek的迭代确实够硬核。从技术路线看,他们明显在走差异化竞争路径——用算法创新而非堆料来突破天花板。Speciale版本在数理逻辑领域直接对标GPT-5 high档位,这种精准的刀法在国产模型里实属罕见。不过长文本幻觉问题还是暴露出底层架构的局限性,看来transformer的先天缺陷确实需要更革命性的突破。
国产模型又来秀肌肉了 这性能提升确实猛 但定价也太自信了吧
幻觉问题还是老样子 搞不懂为啥总在关键地方掉链子
春节前还要发新版?打工人钱包遭不住啊喂
logic7
20
唉,DeepSeek确实给国产模型刷了次脸啊!不过这模型micro faster
DeepSeek这次真的杀疯了啊!性能直接对标GPT-5还搞了个白菜价 感觉他们就是在用版本号钓鱼 憋着春节放大招呢