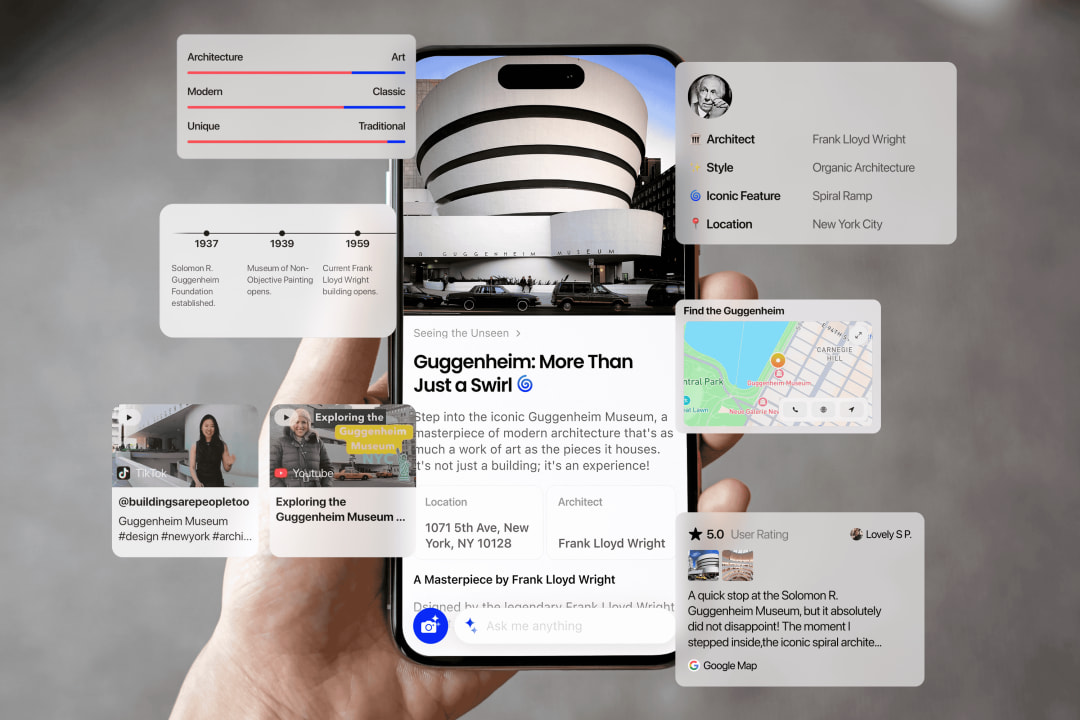
亚洲当代艺术博览会上,一款 AI 产品成了特殊的 “解说员”:观众举起手机对准画作,无需输入任何文字,AI 就会自动解读作品的创作逻辑与背后故事。这不是普通的视觉识别工具,而是 Chance AI 推出的全球首款视觉 Agent 产品 —— 它打破了 “输入框交互” 的传统模式,让 “拍照即沟通” 成为现实,更在视觉理解核心基准测试 MMMU 上以 86.07% 的准确率超越人类评分(85.4%),登顶世界第一。
这款由前字节、一加、OPPO 产品老兵曾熙创办的产品,凭借认知科学 PhD 的独特视角,精准击中 Z 世代的视觉交互习惯,上线后吸引 20 万用户(15 万为 25 岁以下年轻人),更获得 AK、Robert Scoble 等硅谷 AI 大 V 的点赞转发。它不只是一款 App,更是曾熙口中 “人类最直觉的操作系统”,正在重新定义 AI 与现实世界的交互方式。
从输入框到相机:视觉 Agent 的颠覆性交互
打开 Chance AI,看不到常见的输入框,整个界面只有一个醒目的相机入口 —— 这是产品最核心的设计逻辑:“让 AI 先看懂,再开口”。创始人曾熙认为,人类认识世界的本质是 “视觉优先”,很多时候我们看到一个事物,还没想好怎么用语言描述,好奇心就已产生。Chance AI 要做的,就是捕捉这种直觉式需求,让 AI 成为参与用户 “看世界” 过程的主动伙伴,而非等待指令的被动工具。

这种交互模式彻底区别于两类传统产品:
-
与 Google Lens 等视觉识别工具相比:后者聚焦 “是什么” 的描述层面,核心目标是导流搜索或交易(比如找同款、查价格);而 Chance AI 专注 “为什么” 的解释层,会挖掘事物背后的文化、历史与情绪价值。比如看到一款厨房料理机,它会告诉你 “这是乔布斯童年常用款,影响了 iPod 的设计理念”;面对潮玩,它能解读其承载的情感符号,而非仅描述材质。
-
与普通 ChatBot 相比:通用大模型的视觉能力只是附加功能,核心仍围绕输入框展开;而 Chance AI 以视觉为起点,每张图片就是一个对话主题,后续追问都围绕该场景的上下文展开。比如拍一套穿搭,AI 会记住你之前试穿的款式差异,判断你是否在纠结场合穿搭,给出针对性建议。
曾熙团队曾尝试在首页加入输入框,结果导致用户失焦,长期留存反而下降。这一经历更坚定了他们的方向:“视觉才是最直觉的交互方式,输入框会打断这种自然感”。
为 Z 世代而生:视觉驱动的生活方式伴侣
Chance AI 的核心用户被定义为 “艺术的生活家”—— 他们多是艺术学院或文理学院的学生,习惯用表情包、图片、视频沟通,追求感性体验与独特氛围(Vibe),而非理性参数。这群 Z 世代用户的使用场景充满多样性,且呈现明显的地域特征:

-
美国用户:聚焦穿搭购物、化妆品、潮玩,热衷通过 AI 获取风格建议;
-
欧洲用户:偏爱艺术品、建筑、书籍封面,甚至会拍摄外语书籍封面让 AI 解读内容;
-
拉美用户:沉迷神秘学,拍手相、面相判断当日运势,并结合穿搭选择首饰颜色。
产品之所以能精准契合 Z 世代,关键在于它不是效率工具,而是 “lifestyle 视觉伴侣”。数据显示,用户单次核心任务流的交互时长达 6.4 分钟,平均每轮会进行 3-5 次对话 —— 他们用它给球星卡生成电子证书分享到社交平台,用它在圣诞节给伴侣挑礼物,用它给落日照片匹配 City Pop 风格的背景音乐,甚至用它整理昆虫标本收藏,让 AI 自动分类并关联产地信息。
这种非效率场景的价值,恰恰避开了大厂的辐射范围。曾熙坦言:“这些小众需求大厂不会做,但我们离用户足够近,能快速把他们的需求转化为功能”。而校园计划的口碑传播,也成为产品增长的核心动力 —— 通过赞助学生活动,让年轻人在逛展、探店的过程中共同使用产品,分享发现的乐趣,形成自然的传播闭环。
技术内核:复刻人类看世界的视觉工程架构
Chance AI 能在 MMMU 测试中超越人类,核心并非依赖单一强大的 VLM 模型,而是独创的 “视觉工程架构(Visual Harness Engineering)”—— 它复刻了人类认知世界的四步链路:信号采集→信号传递→视觉皮层处理→大脑决策,将不同环节拆开用专属模型处理,而非让一个模型包揽所有工作。
这一架构的优势在实践中尤为明显:
-
多模型协同:每个节点最多可调用 6-8 个模型,根据场景灵活选择云端或自研微调模型。比如识别衣服时,会调用能抓取 Instagram 趋势标签的 Skill,确保风格建议贴合潮流;
-
视觉记忆存储:摒弃纯文本记忆的低效模式,将图片压缩为 100x100(模型沟通)、500x500(思考过程)、原尺寸(用户展示)三个层级。这种以低像素图片为载体的记忆方式,不仅沟通效率更高,还能精准捕捉文字无法描述的 “氛围感”;
-
意图收敛机制:用户拍照时可能没有明确意图,但 AI 会通过 80%-90% 的概率预判核心需求(比如拍衣服大概率是想知道是否适合自己),再通过多轮交互逐步收敛意图。比如男生拍女装,AI 会通过后续对话判断是给伴侣挑礼物,而非自己使用。
曾熙透露,团队曾走过 “用一个模型解决所有问题” 的弯路,最终在认知科学的启发下明白:“人类不会让眼睛同时承担思考功能,AI 也不该如此”。这种工程化的拆解思路,让 Chance AI 即便使用开源 VLM,也能实现超越专属大模型的效果。
未来图景:从 App 到下一代 AI 操作系统
在曾熙的规划中,Chance AI 的终极形态不是一款 App,而是像电影《Her》中 Samantha 那样的操作系统 —— 它能与 AI 硬件无缝融合,成为人类与世界交互的自然入口。而要实现这一目标,还需突破三大卡点:
-
基础技术:VLM 需实现更低成本、更实时的交互,达到电影中 “即时响应” 的体验;
-
硬件成熟:Meta Glasses 等设备虽已售出 200 万台,但距离手机级别的普及仍有距离;
-
用户习惯:让习惯文本交互的大众用户,接受 “与 AI 一起看世界” 的新方式。
尽管前路仍有挑战,但团队已明确方向:先搭建好视觉思考的 “大脑”,再逐步切入硬件领域。曾熙表示,做硬件对团队而言是舒适区 —— 核心成员拥有丰富的消费电子经验,但当前阶段的重点是打磨核心能力:“现在的 AI 硬件只能告诉你‘这是黑色圆柱形物体’,我们要做的是让它理解用户看到物体时的真实需求,这才是有价值的交互”。
而短期目标,是将用户从 20 万提升至 100 万、500 万。增长路径并非靠投流买量,而是先打透穿搭、旅行、购物等核心场景,再通过内容与社交扩散 —— 比如穿搭场景的一键生成 Instagram Story 功能,就是为了降低用户的分享门槛,让产品自然融入 Z 世代的社交生活。
结语:视觉交互的下一个时代
当大多数 AI 产品还在围绕文本交互内卷时,Chance AI 已经开辟了视觉 Agent 的新赛道。它证明了 AI 与人类的交互,不止于 “你问我答” 的输入框模式,更可以是 “你看我懂” 的直觉式陪伴。
曾熙说:“人类用几百万年形成了视觉优先的认知习惯,这是不变的;我们要做的,只是让 AI 跟上这种习惯”。而这款为 Z 世代而生的产品,或许正在悄悄改变 AI 的形态 —— 从解决效率问题的工具,变成丰富生活体验的伴侣;从依赖文本的交互,走向融合视觉、语音、情感的全维度沟通。
随着硬件的成熟与用户习惯的养成,视觉 Agent 或许真的会成为下一代操作系统的核心。而 Chance AI 的探索,已经为这场变革写下了关键的开篇:AI 的未来,始于 “看见”。