2026 年 4 月 3 日晚,谷歌 DeepMind 重磅推出开源模型家族 Gemma 4 系列,凭借与 Gemini 3 同源的顶尖技术,直接刷新开源 AI 的性能天花板。这款模型不仅在 Arena AI 排行榜拿下全球第三,更以 31B 参数体量实现了堪比 Qwen 3.5 397B(13 倍参数量)的性能表现,更颠覆性地采用 Apache 2.0 开源许可证,彻底放开商用限制,让从手机到服务器的全场景部署成为可能。

四大核心突破,重构开源模型格局
Gemma 4 的横空出世,并非简单的版本迭代,而是在架构、性能、部署和生态四大维度的全面革新,直接解决了开源模型商用受限、性能与效率失衡、部署场景单一等核心痛点。
1. 协议自由:Apache 2.0 加持,商用无任何限制
这是 Gemma 系列最关键的一次升级。此前 Gemma 模型采用谷歌自定义限制性协议,存在使用场景约束、条款可单方面修改等问题,被业内诟病为 “伪开源”,导致大量企业和开发者望而却步。
而 Gemma 4 全系采用Apache 2.0 开源许可证,彻底消除了商用顾虑:开发者可自由商用、魔改模型、二次分发,谷歌无权单方面变更规则,与阿里 Qwen、DeepSeek 等主流开源模型的协议标准保持一致,真正实现了 “拿过来就能用” 的自由开源体验。Hugging Face CEO Clément Delangue 直言,这是 “里程碑式的进步”。
2. 性能狂飙:参数效率拉满,小模型干翻巨无霸
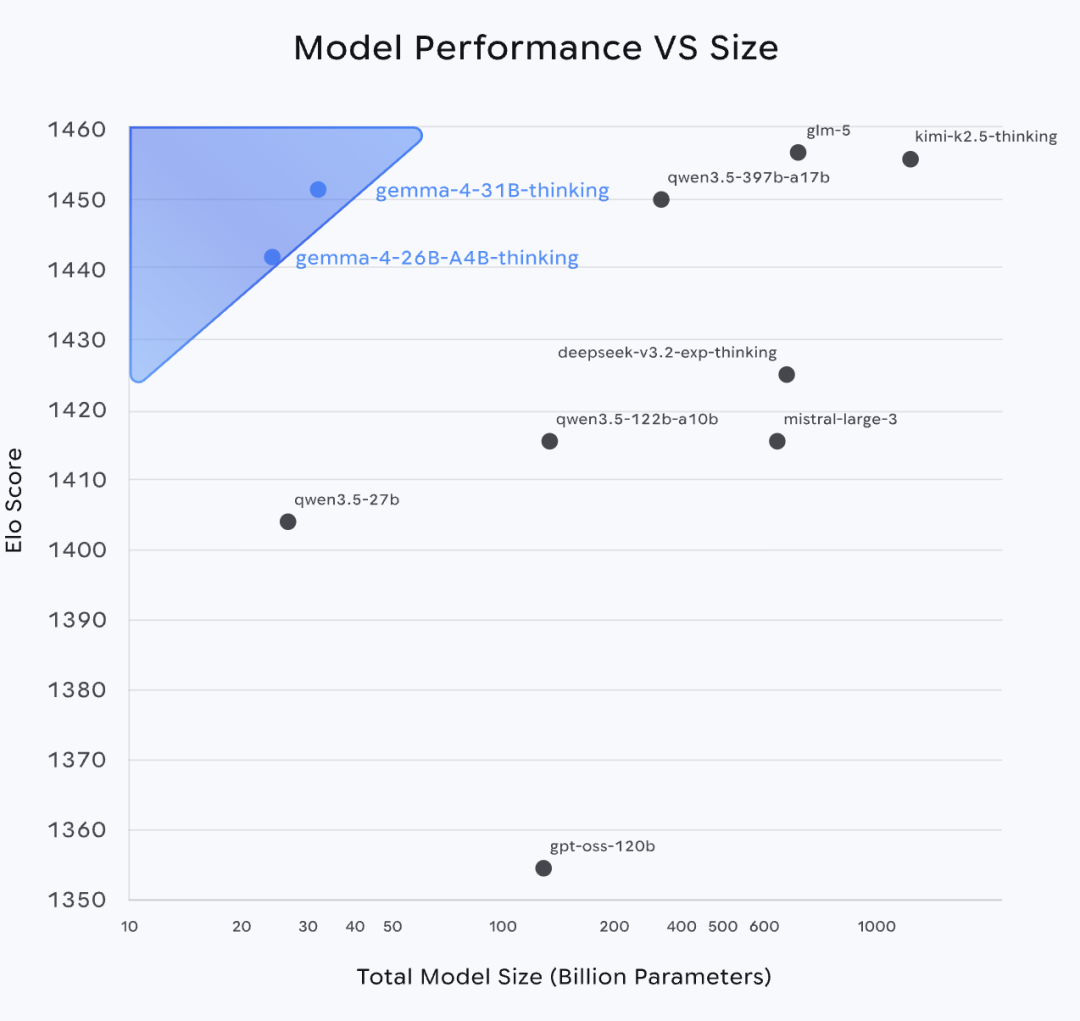
Gemma 4 颠覆了 “参数量决定性能” 的传统认知,通过极致的模型优化,实现了 “每一个参数都榨干价值” 的突破。其中旗舰级的 31B 稠密模型表现最为惊艳:
-
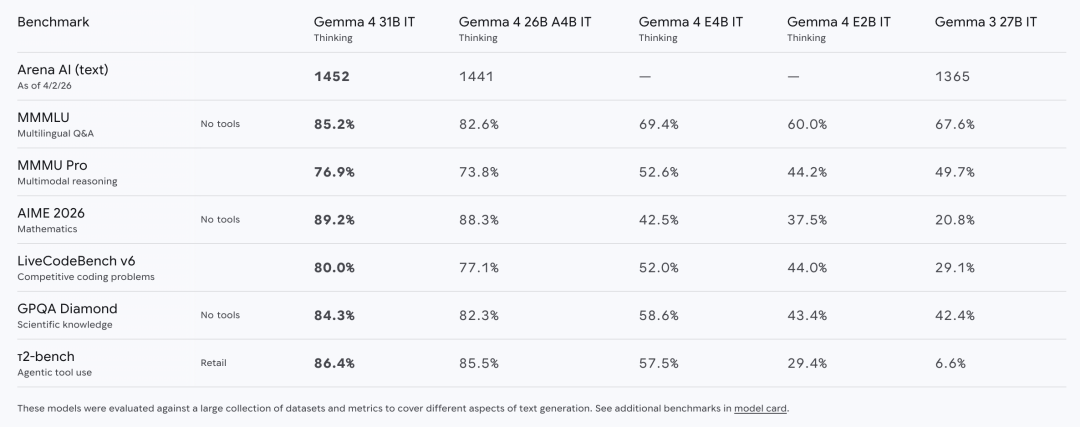
在 AIME 2026 数学竞赛中斩获 89.2% 的高分,远超上一代 Gemma 3 27B 的 20.8%;
-
LiveCodeBench v6 编程基准测试达到 80.0%,Codeforces ELO 评分 2150,编码能力跻身顶尖行列;
-
GPQA Diamond 科学知识推理得分 84.3%,多模态推理 MMMU Pro 达到 76.9%,综合能力与参数量 13 倍于它的 Qwen 3.5 397B 不相上下。
更值得称道的是 26B A4B 混合专家(MoE)模型,总参数量 252 亿,但推理时仅激活 38 亿有效参数,以 40 亿参数的算力开销,跑出了旗舰级性能,Arena AI 评分 1441,位列开源模型第六,成为低延迟、高性能场景的最优解。
3. 全场景覆盖:从手机到服务器,部署无死角
Gemma 4 推出四款不同规模的模型,构建了从端侧到云端的完整产品矩阵,精准适配各类部署场景,真正让顶尖 AI 技术触手可及:
-
31B Dense(旗舰级):307 亿参数,支持文本 + 图片双模态,25.6 万 token 超大上下文窗口,单块 80GB H100 即可实现完整精度推理,专为数据中心、工作站等高性能需求设计;
-
26B A4B MoE(高效能级):252 亿总参数,有效参数 38 亿,支持文本 + 图片模态,25.6 万 token 上下文,兼顾性能与速度,适合消费级 GPU 部署;
-
E4B(端侧高效级):45 亿有效参数(含嵌入 80 亿),支持文本 + 图片 + 音频三模态,12.8 万 token 上下文,与高通、联发科联合优化,可在高端手机、树莓派等设备本地运行;
-
E2B(轻量端侧级):23 亿有效参数(含嵌入 51 亿),三模态支持,12.8 万 token 上下文,极致轻量化,适配入门级手机、平板等边缘设备。
4. 技术革新:架构与功能双升级,能力全面进化
Gemma 4 在技术架构上实现多重突破,为性能和效率奠定坚实基础:
-
混合注意力机制:融合局部滑动窗口注意力与全局注意力,最后一层始终保持全局感知,搭配比例 RoPE(p-RoPE)优化,兼顾长上下文处理能力与内存效率;
-
高效参数设计:E2B/E4B 采用 Per-Layer Embeddings(PLE)技术,为每个词法单元的解码器层提供专属小型嵌入,大幅提升端侧部署效率;
-
原生多模态支持:全系列支持文本 + 图片输入,E2B/E4B 原生兼容音频、视频处理,可实现对象检测、OCR、语音识别、视频帧分析等复杂任务;
-
增强型智能体能力:原生支持函数调用和 system 角色提示,可无缝衔接智能体工作流,自主完成工具调用、任务规划,R2-bench 零售场景工具使用评分 86.4%;
-
多语言覆盖:预训练数据涵盖 140 多种语言,开箱即用支持 35 种以上语言,满足全球化应用需求。
部署门槛极低:量化后消费级硬件也能跑
Gemma 4 在部署友好性上做到了极致,通过量化技术大幅降低内存占用,让消费级硬件也能轻松驾驭:
| 模型版本 | BF16(16 位)内存需求 | SFP8(8 位)内存需求 | Q4_0(4 位)内存需求 |
|---|---|---|---|
| Gemma 4 E2B | 9.6 GB | 4.6 GB | 3.2 GB |
| Gemma 4 E4B | 15 GB | 7.5 GB | 5 GB |
| Gemma 4 26B A4B | 48 GB | 25 GB | 15.6 GB |
| Gemma 4 31B | 58.3 GB | 30.4 GB | 17.4 GB |
更重要的是,Gemma 4 发布即实现全生态支持,当天就兼容 Transformers、llama.cpp、MLX、Ollama、vLLM 等主流框架,通过 Ollama 仅需输入 “ollama run gemma4” 即可快速启动。开发者可在 Hugging Face、Kaggle 下载模型权重,31B/26B 版本可在谷歌 AI Studio 免费体验,小模型则可通过 AI Edge Gallery 直接部署到端侧设备。
训练数据与安全:多元合规,放心使用
Gemma 4 的预训练数据集规模庞大、来源多元,截止日期为 2025 年 1 月,涵盖网页文档、代码、数学文本、图片、音频等多模态内容,确保模型具备广泛的知识覆盖和任务适配能力。
在数据安全方面,谷歌采取了多重严格措施:在数据准备全流程应用 CSAM(儿童性虐待内容)过滤,通过自动化技术剔除个人信息等敏感数据,并基于内容质量和安全性进行多轮筛选,确保模型输出的可靠性与合规性。
开源生态再迎变局,AI 普及加速到来
Gemma 4 的发布,不仅填补了谷歌在 “真开源” 领域的空白,更给整个开源 AI 生态带来深远影响。此前 Gemma 系列累计下载量已超 4 亿次,社区衍生出 10 万多个微调变体,此次 Apache 2.0 协议的放开,叠加全场景部署能力和顶尖性能,势必吸引更多企业和开发者加入,推动开源模型在工业、消费、教育等领域的规模化应用。
从端侧设备的本地推理,到云端的大规模部署;从个人开发者的创意实践,到企业级的商业应用,Gemma 4 用 “高性能、低门槛、全自由” 的组合拳,打破了 AI 技术的应用壁垒。随着这款模型的普及,开源 AI 将正式进入 “提质降本” 的新阶段,而谷歌也凭借这一重磅发布,重新确立了在开源 AI 赛道的核心竞争力,未来的模型之争,或将围绕 “参数效率” 和 “全场景适配” 展开新的角逐。