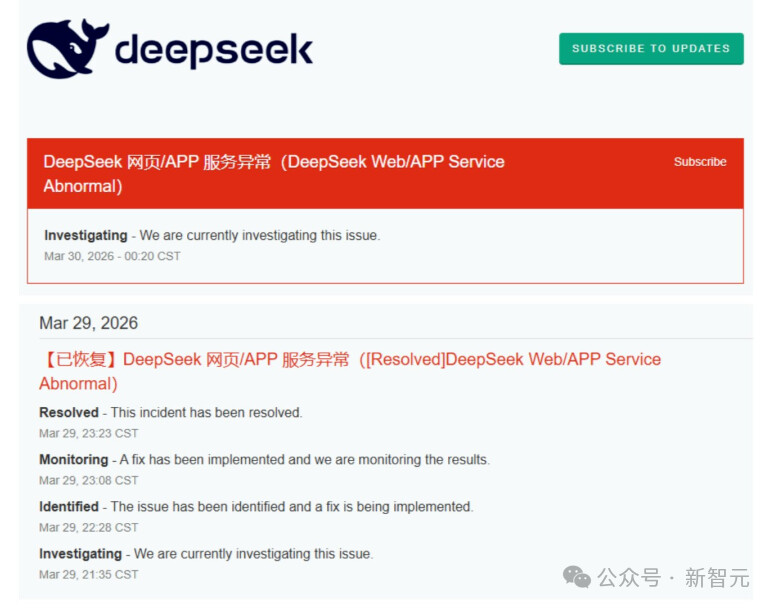
2026 年 3 月 29 日晚,国产大模型之光 DeepSeek 突发史上最长宕机:从 21:35 到 30 日上午 10:33,网页端、App 端全线停摆 12 小时 58 分钟,#DeepSeek 崩了# 话题冲上微博热搜,阅读量破 8300 万、讨论量 6.8 万,外媒路透社专门发文报道这一 “重大故障”(Major Outage)。
就在全网哀嚎 “AI 刚需断供” 的同时,恢复后的 DeepSeek 却露出诸多反常迹象:编码风格突变、UI 悄悄升级、知识截止日期更新至 2026 年,再加上流传的基准测试数据,让网友惊呼:“这不是简单宕机,是 V4 要来了!”

一、13 小时宕机:暴露 AI 刚需本质,全球开发者集体 “戒断反应”
DeepSeek 自 2025 年初爆红以来,虽偶有卡顿,但网页端服务从未中断超过 2 小时。此次通宵停摆堪称 “至暗时刻”,官方状态页面红色预警持续跳动,工程师连夜抢修,期间甚至出现二次故障,让全球用户深刻体会到 “AI 已成生产力刚需”。
“对话框消失的瞬间,半个大脑都没了” 成为网友共鸣:打工人的代码调试、文案创作、数据分析工作流直接卡住;海外开发者在 Reddit 发帖追问 “DeepSeek 到底怎么了”,帖子收获 768 条回复、303 次分享,足见其在全球开发者社区的影响力。
关于宕机原因,网友猜测纷纷,其中 “资源挪用训练新模型” 的观点呼声最高 —— 有行业人士分析,如此长时间的服务中断,大概率是为新模型上线做基础设施升级或数据迁移,而非单纯的服务器故障。
二、V4 疑似灰度测试:隐形进化的三大信号
宕机恢复后,细心的用户发现 DeepSeek 已 “悄悄变脸”,种种迹象指向 V4 正在进行灰度测试,只是仍沿用 V3 标签,属于 “隐形进化”:
1. 核心能力质变:编码风格、推理逻辑全面升级
多名资深开发者反馈,DeepSeek 的 Zero-shot 编码输出风格突变,结构更清晰、逻辑更严谨,完全不是简单微调能实现的效果。例如 SVG 绘图任务中,一周前还只能画出简陋图形,恢复后能生成细节丰富、比例协调的作品;自我介绍也从 “纯文本 AI 助手” 升级为明确标注 “DeepSeek-V3”,暗示版本迭代。
更关键的是知识更新:有用户测试发现,它能准确回答 “2026 年美国总统是特朗普”(2025 年 1 月就职),证明知识截止日期已从 2025 年 5 月更新至 2026 年,打破了旧模型的信息壁垒。
2. UI 暗藏玄机:上传功能重构,预示后端升级
App 端的细微变化同样耐人寻味:文件上传按钮点击后的界面全面更新,从单一的 “图像 OCR” 扩展为 “文档、相机、相册、文件” 多入口,支持更丰富的输入类型。这种 UI 调整通常伴随后端架构重构,与多模态模型的功能需求高度契合。
3. 版本迭代痕迹:隐形更新符合灰度测试逻辑
查看 DeepSeek 的版本历史,30 日当天悄然更新至 1.8.0 版本,更新说明仅标注 “修复已知问题”,未透露核心变化。这种 “低调更新 + 能力质变” 的模式,正是行业常见的灰度测试策略 —— 先让部分用户体验新模型能力,收集反馈后再正式官宣。
不少网友推测,当前的 “V3” 标签下,实际运行的可能是 V4 的蒸馏版本或部分核心能力,目的是在不引发期待落差的前提下,验证新模型的稳定性。
三、基准测试泄露:200B 参数 + 1M 上下文,碾压国际顶流?
如果说表象变化只是猜测,那么圈内流传的 V4 基准测试数据则让人大吃一惊。尽管未经官方确认,但消息人士称数据 “偏保守”,核心规格堪称 “暴力美学”:
1. 硬件规格:200B Lite 版起步,可扩展至 1 万亿参数
-
基础版 V4 Lite 参数达 2000 亿,支持 100 万 Token 上下文窗口,能一次性处理整份代码库或三部《三体》体量的文本;
-
采用全新 mHC 架构,最高可扩展至 1 万亿参数,突破现有模型的规模天花板;
-
原生支持多模态:覆盖文本、图像、视频输入输出,补齐 V3 纯文本短板。
2. 性能跑分:代码能力碾压竞品,多项指标第一
网传数据显示,V4 在核心基准测试中表现炸裂:
-
HumanEval(代码生成)达 90%,超越 Claude 3.5 Opus 的 84.9%,逼近 GPT-5.3 的预期值(88%-92%);
-
SWE-bench(软件工程任务)超 80%,而 Claude 3.5 Opus 不足 40%,形成碾压级优势;
-
综合编码性能超越 V3.2 及所有现有竞品,消息人士透露 “真实数据比泄露的更夸张”。
若这些数据属实,DeepSeek V4 将成为首个在核心场景比肩甚至超越 GPT-5.3、Claude 3.5 Opus 的国产大模型,彻底改变全球大模型竞争格局。
四、发布悬疑:多次跳票背后,是 “经典预发布模式”?
DeepSeek V4 的发布时间早已成为行业悬念:最初计划 2 月农历新年发布,后推迟至 3 月初,再延后至 4 月,如今仍无官方确切消息。部分合作方已签署 NDA(保密协议),进一步印证了 “产品成型、待终测” 的猜测。
这种多次跳票的模式,在科技圈被称为 “经典预发布模式”—— 产品核心功能已完成,但需进行最后的性能优化、兼容性测试和 Bug 修复。预测平台 ProbTrade 甚至开设 “4 月 15 日前 DeepSeek V4 是否发布” 的投注,当前 “发布” 选项赔率达 65c,显示市场对 4 月发布的预期极高。
此外,有知情人士透露,V4 正在进行大规模国产算力适配,这可能是发布推迟的重要原因 ——DeepSeek 或许在打造 “从底层芯片到顶层算法” 的全自主生态,避免依赖海外算力,这也与网传的 mHC 架构高扩展性相呼应。
五、结语:沉默四个月,憋出 “国产核弹”?
从 2025 年底至今,DeepSeek 已四个月未更新核心模型,看似沉寂,实则可能在憋大招。此次 13 小时宕机更像是新模型上线的 “前哨战”,而恢复后的种种反常迹象、流传的基准测试数据,都指向一个结论:V4 已箭在弦上。
对于用户而言,这场漫长的等待或许值得 —— 如果网传数据属实,DeepSeek V4 将打破国际顶流模型的垄断,成为 “便宜又能打” 的国产标杆;对于行业而言,这可能是中国大模型从 “跟跑” 到 “领跑” 的关键转折点。
目前,全球 AI 行业都在紧盯 DeepSeek 的动向,那个曾经的 “屠龙少年” 是否能携 V4 王者归来?4 月是否会迎来正式发布?让我们拭目以待。