“大模型能否真正预测未来?” 这一核心疑问长期困扰 AI 行业 —— 传统 AI 预测要么依赖无法追溯的 Demo,要么存在选择性披露案例的偏差,通用基准测试也难以匹配真实预测场景的复杂性。而 UniPat AI 推出的Echo 预测智能基础设施,用 “动态评测引擎 + Train-on-Future 训练范式 + EchoZ-1.0 专用模型” 的三重架构,给出了可验证、可复现的答案。这款系统不仅让核心模型 EchoZ-1.0 在 General AI Prediction Leaderboard 稳居榜首,更在与人类交易市场的对决中展现显著优势,成为 AI 预测领域的革命性突破,更为通用智能的发展铺垫了关键路径。
一、打破验证困境:三重可验证性,重构 AI 预测的信任基础
预测领域的根本痛点在于 “难以验证”—— 你说模型能预测未来,如何证明其准确性而非运气或选择性展示?Echo 的核心创新之一,就是构建了 “动态排行榜 + 实盘市场对照 + 全量数据公开” 的三重可验证体系,彻底解决了这一行业顽疾。
1. 登顶预测榜单,稳定性碾压顶尖大模型
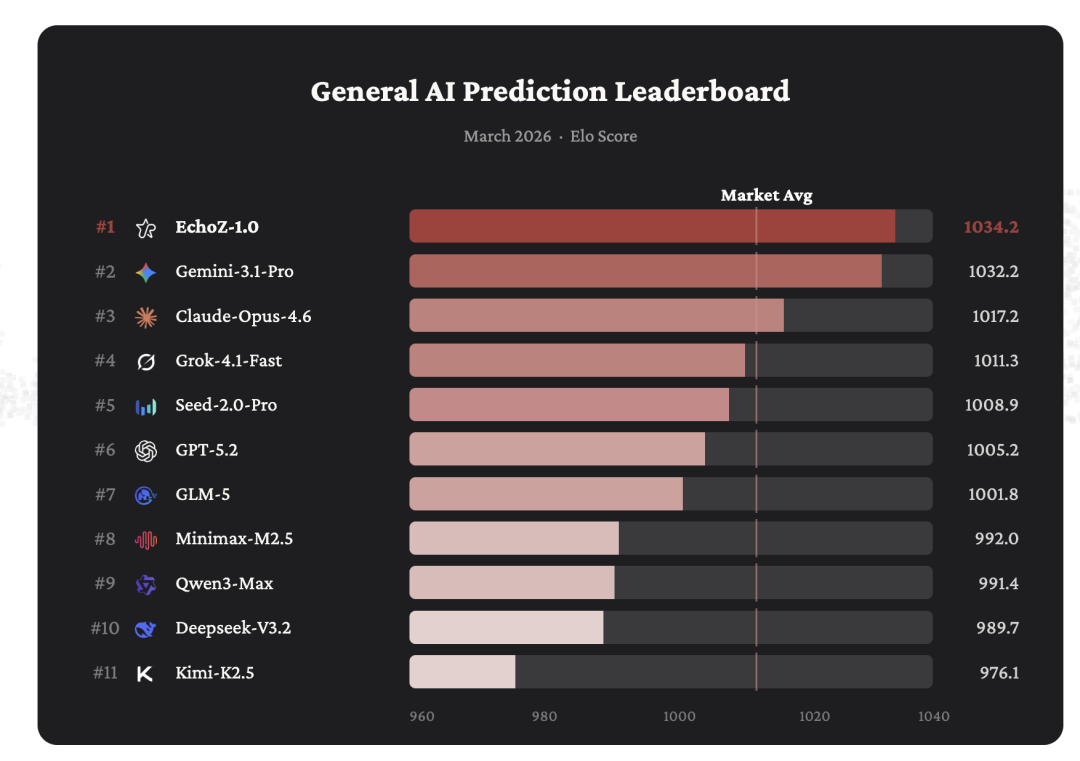
2026 年 3 月的 General AI Prediction Leaderboard 数据显示,EchoZ-1.0 以 Elo 1034.2 的高分位列第一,领先 Google Gemini-3.1-Pro(1032.2)和 Anthropic Claude-Opus-4.6(1017.2)。这份覆盖政治、经济、体育、科技等 7 大领域、包含 1000 + 道活跃题目的榜单中,EchoZ-1.0 的优势不仅在于分数,更在于极致的稳定性:
在 σ 参数敏感性测试中(调整参数放大模型表现差距,共 9 组取值),EchoZ-1.0 是唯一在所有分组中均保持第一的模型;而 GPT-5.2 的排名在第 2 至第 9 名之间大幅波动,稳定性差距显著。这种稳健性意味着其预测能力并非依赖单一场景或短期数据,而是具备强大的泛化性。
2. 对标人类实盘,高难度场景优势凸显
EchoZ-1.0 的竞争对手不仅是顶尖大模型,更包括 Polymarket 等预测市场上 “真金白银投入” 的人类交易者聚合判断 —— 其 Elo 分数显著高于这一人类基线,证明 AI 预测已具备实际应用价值。
UniPat AI 的分层对比数据更具说服力,EchoZ-1.0 在人类最不擅长的场景中优势尤为明显:
-
政治与治理领域:胜率 63.2%,复杂博弈中信息整合能力远超人类;
-
长期预测(7 天以上):胜率 59.3%,打破人类对短期事件的直觉优势;
-
市场不确定区间(人类信心 55%-70%):胜率 57.9%,人类犹豫时 AI 的概率校准能力更显稳健。
这一规律暗示,AI 在信息整合、逻辑推演和概率校准上的系统性优势,恰好在人类直觉最不可靠的区域得到最大释放。
3. 全量数据公开,可回溯无死角
Echo 官网公开了所有预测问题、模型输出的概率分布和最终结算结果,任何人都可回溯验证每一次预测的全过程,彻底杜绝 “选择性披露成功案例” 的行业乱象。动态排行榜、人类实盘对照、全量数据公开的三重验证,让 Echo 成为首个 “可信赖的 AI 预测系统”。

二、动态评测引擎:打造 “会生长的预测标尺”
传统预测基准存在两大结构性缺陷:一是 “时序不对称”—— 越接近事件结算时间,可用信息越多,不同时间点的预测结果无法公平对比;二是 “题源单一”—— 多来自预测市场的二元问题,遗漏专业领域需求。Echo 构建的动态评测引擎,通过 “数据采集 - 预测点调度 - 对战构建 - Elo 评分更新” 的闭环,完美解决了这些问题。
1. 三维数据采集,覆盖全预测光谱
三条数据管道并行运行,确保题目来源的全面性和高质量:
-
对接 Polymarket 等预测市场,筛选有明确结算规则和共识信号的合约;
-
抓取 Google Trends 等实时趋势,由 AI Agent 自动生成未来事件预测题,并持续追踪进展、完成自动结算;
-
吸纳科研、工程、医疗等专业领域专家贡献的预测题,由权威人士判定结果。
从大众共识到专家判断,三条管道覆盖了不同场景、不同难度的预测需求,让评测更贴近真实世界。
2. 对数调度 + Point-aligned Elo,实现公平对决
-
预测点调度:每道题根据结算周期长度,用对数调度算法分配多个 “预测时间点”,既保证事件生命周期内的覆盖密度,又控制计算开销;
-
对战构建:采用 Point-aligned Elo 机制,严格只比较 “同一道题、同一预测时间点” 的模型结果,让所有参赛模型在完全相同的信息上下文下对决,彻底消除时序不对称带来的不公平。
3. 快速收敛评分,效率提升 2.7 倍
基于 Bradley-Terry MLE 算法计算全局排名,新模型加入后的排名收敛速度,是传统 Avg Brier 方法的 2.7 倍(传统方法需 14.5 天收敛,Echo 仅需 5.4 天),大幅提升评测效率。
这套动态引擎就像一把 “会生长的尺子”,新题目持续流入、预测点持续触发、排名持续更新,始终保持评测的时效性和准确性。
三、Train-on-Future 范式:让推理过程成为训练核心
传统预测模型训练(Train-on-Past)面临两大难题:一是数据泄露难以避免 —— 模型搜索信息时易撞上历史事件答案;二是结果导向偏差 —— 逻辑严密的分析可能因黑天鹅事件出错,粗糙猜测可能碰巧命中,导致模型过拟合噪声。Echo 独创的Train-on-Future 训练范式,从源头解决了这些问题。
1. 动态问题合成:杜绝数据泄露
不使用历史题库,而是从实时数据流中持续生成关于 “未来事件” 的高信息量预测题。由于事件尚未发生,模型在训练过程中无法获取答案,从根本上杜绝了数据泄露。
2. Automated Rubric Search:聚焦推理质量
训练信号不再依赖 “预测结果对错”,而是聚焦 “推理过程质量”。系统通过数据驱动的方式,自动搜索最优评分标准(Rubric),每个领域独立生成 20 个评分维度,例如:
-
“Precursor and External Catalyst Evaluation”:评估模型是否识别具体先行信号(如关键球员回归、政策变动),并分析历史关联;
-
“Multi-Factor Causal Synthesis”:评估模型是否整合至少三个独立因素(如伤病、主客场、赔率),并解释因素间的相互作用。
这些评分标准通过迭代持续优化,目标是让 Rubric 生成的模型排名与真实 Elo 排名相关性最大化,确保训练聚焦于 “优秀的推理过程” 而非 “偶然的正确结果”。
3. Map-Reduce Agent 架构:提升推理深度
推理阶段采用分布式流程:Map 阶段将宏观预测问题拆解为多个正交子任务,多个 Agent 并行完成信息采集和领域推理;Reduce 阶段由聚合节点处理跨源冲突、对齐因果链,输出最终概率判断。整个过程支持多轮自适应迭代,直到信息覆盖度和推理深度趋于稳定。
这套范式的本质是:不仅教模型 “猜对答案”,更教模型 “正确分析”,而 “评价分析过程” 本身也由系统自动完成。
四、从预测到决策:AI-native Prediction API 即将落地
UniPat 计划将 EchoZ-1.0 的能力封装为AI 原生预测 API对外开放,让预测能力成为可调用、可集成的决策参数。从技术架构来看,这套 API 支持自然语言输入预测问题,返回包含 “概率分布 + 分层证据链 + 反事实脆弱性评估 + 监测建议” 的结构化报告,所有内容均由多轮 Map-Reduce Agent 实时检索网络证据后生成。
当预测从 “凭直觉猜测的概率” 变成 “可量化、可验证的参数”,其应用场景将远超当前 —— 金融市场的算法交易、企业的战略规划、公共领域的政策制定等,都能嵌入这套预测能力,实现更精准、更稳健的决策。正如 Echo 官网所言:“未来不再是你猜测的概率,而是你可以整合的参数。”
五、四大核心关键词,定义预测智能的未来
UniPat 为 Echo 定义了四个核心关键词,这也成为其引领 AI 预测领域的关键支柱:
-
General(通用):覆盖 7 大领域、1000 + 道题目,适配不同场景的预测需求;
-
Evaluable(可验证):动态排行榜、实盘对照、全量数据公开,预测能力可回溯、可复现;
-
Trainable(可训练):Train-on-Future 范式解决传统训练的核心痛点,模型能力可持续迭代;
-
Profitable(可盈利):API 接口将预测能力转化为实际决策价值,赋能商业场景创造收益。
结语:预测智能,通用智能的关键一步
Echo 的突破不仅在于打造了一款胜率超人类的预测模型,更在于构建了一套完整的预测智能基础设施 —— 它解决了 “如何验证预测能力” 的根本问题,重构了 AI 预测的信任基础;更通过聚焦 “推理过程” 的训练范式,推动 AI 从 “被动输出答案” 向 “主动进行逻辑推演” 进化。
从技术意义上看,预测能力是通用智能的核心组成部分 —— 只有能准确推演未来,AI 才能真正理解世界的运行规律,做出合理规划与决策。Echo 的探索,不仅让 AI 预测从 “实验室 demo” 走向 “产业级应用”,更为通用智能的发展迈出了关键一步。随着 API 的正式上线,预测智能将嵌入更多决策场景,而 Echo 定义的 “通用、可验证、可训练、可盈利” 标准,也将成为 AI 预测领域的行业标杆。
(Echo 官网地址:https://echo.unipat.ai/;博客链接:https://unipat.ai/blog/Echo)