当世界模型的参数规模不断扩大、状态表征能力持续升级,制约其成为「内部模拟器」的核心瓶颈逐渐浮出水面 —— 动力学建模。世界模型不仅要「看懂」环境(状态表征),更要「推演」未来(状态演化),而后者长期缺乏系统性突破。南京大学 LAMDA 强化学习小组博士生林浩鑫,以连续两篇 ICLR 论文(2025 年 ADM、2026 年 ADM-v2)给出了破局方案,从「任意步直接预测」到「上千步完整时域推演」,持续推进世界模型的动力学建模能力,让其从「短程预测工具」真正迈向「近整回合级内部模拟器」。
一、世界模型的核心矛盾:动力学建模拖了表征能力的后腿
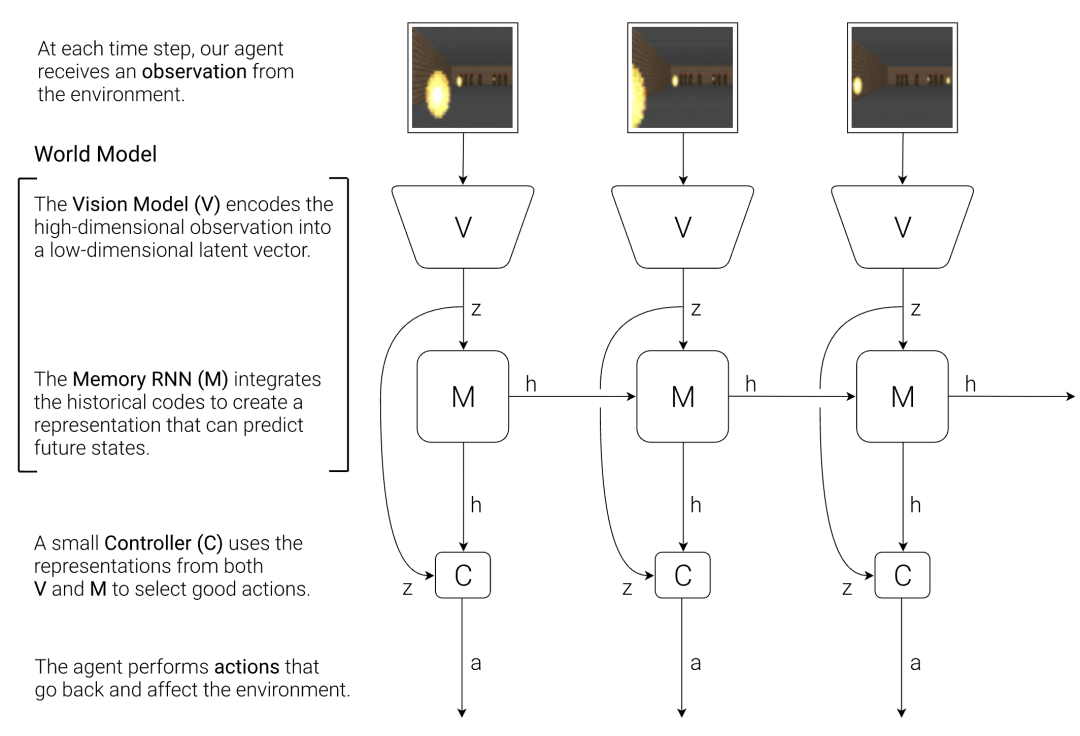
经典世界模型由两大核心模块构成:V 模型(状态表征)负责将高维观测压缩为紧凑的内部状态,解决「模型看到了什么」;M 模型(动力学建模)负责预测状态在动作作用下的演化,解决「模型如何推演未来」。过去几年,行业聚焦于 V 模型的优化,更强的编码器、更优的潜变量表示让状态表征精度不断提升,但 M 模型的发展严重滞后。
而动力学建模恰恰是世界模型价值落地的关键 —— 只有能稳定推演未来,智能体才能在模型内部完成「预演」,再与真实环境交互,这直接关系到模型型强化学习、离线强化学习、具身智能规划等核心场景的落地效果。传统动力学模型采用「单步自举式预测」:输入当前状态 St 和动作 at,预测下一状态 St+1,再将 St+1 作为输入预测 St+2,以此层层递推。这种方式在短程预测中有效,但长程推演时会暴露致命缺陷:
-
误差累积放大:单步预测的微小偏差会在连续推演中不断累积,导致轨迹严重偏移;
-
长程失稳:预测时域越长,模型偏差越明显,最终失去参考价值;
-
泛化能力弱:面对未见过的动作序列,误差传播会更剧烈,模型难以适应新场景。
因此,如何让动力学模型实现「长程推演误差可控、泛化能力强、不确定性估计可靠」,成为世界模型走向实用的核心命题 —— 这正是林浩鑫两篇顶会论文的核心探索方向。
二、ADM(2025 ICLR):任意步直接预测,打破单步自举枷锁
2025 年,林浩鑫在 ICLR 发表《Any-step Dynamics Model》,首次提出「任意步直接预测」思路,彻底重构了动力学建模的推演逻辑,从根源上缓解误差累积问题。
核心创新:跨时域直接预测,缩短误差传播链
ADM(Any-step Dynamics Model)的核心突破在于:未来状态不必依赖上一步预测结果层层递推,可从更早的起始状态出发,结合一段动作序列,直接预测任意步数后的状态。其关键操作是「回溯(backtracking)」—— 模型从不同长度的历史视角切入,对同一未来状态进行多维度直接预测,通过这种方式重写推演路径:
-
传统路径:St→St+1→St+2→…→St+k(单步自举,误差每步传递);
-
ADM 路径:St 直接预测 St+k(跨时域直达,误差传播链大幅缩短)。
这种设计让长程推演的误差不再逐步累积,稳定性显著提升。例如预测 100 步后的状态,ADM 可直接从初始状态 St 出发完成预测,而传统模型需经历 100 次误差传递,两者精度差距随步数增加呈指数级扩大。
轻量不确定性估计:无需模型集成,单模型实现可靠评估
离线强化学习中,模型不确定性估计是判断预测可靠性的关键,传统方法依赖「模型集成」(训练多个模型,通过预测分歧评估不确定性),成本高且效率低。ADM 提出更轻量的解决方案:利用同一模型在不同回溯长度下的预测差异,作为不确定性信号。
-
数据覆盖充分区域:不同回溯尺度的预测结果趋于一致,不确定性低;
-
数据稀疏或分布外区域:不同时间视角的预测分歧明显,不确定性高。
这种「内部集成」方式无需额外训练多个模型,即可实现可靠的不确定性估计,实验显示其与模型集成的相关性高达 0.98,接近甚至超越传统方案。
实验验证:策略性能全面超越强基线
基于 ADM 构建的 ADMPO-ON(在线强化学习)和 ADMPO-OFF(离线强化学习),在 D4RL 和 NeoRL 基准测试中表现亮眼:
-
离线场景:ADMPO-OFF 平均得分 81.0,超越 CQL(61.6)、MOPO(70.3)、MOBILE(80.0)等强基线;
-
在线场景:ADMPO-ON 样本效率显著提升,能更快收敛到最优策略;
-
误差控制:长程推演中,ADM 的误差增长速度远低于传统 RNN 动力学模型和模型集成方案。
ADM 的成功证明:动力学建模不必局限于单步自举路径,跨时域直接预测是缓解长程误差累积的有效方向。
三、ADM-v2(2026 ICLR):上千步完整时域推演,迈向真正的内部模拟器
如果说 ADM 证明了「任意步预测的可行性」,2026 年的 ADM-v2 则实现了「从可行到实用」的跨越 —— 在离线强化学习设定下,首次将完整时域滚动推演(full-horizon roll-out)稳定推进到上千步规模,让世界模型真正具备「近整回合级推演能力」。
结构重构:状态初始化与动作演化分离
原始 ADM 在循环推演中会反复引入起始状态,导致内部表征与起点强耦合,影响长程推演灵活性。ADM-v2 对结构进行核心优化:
-
将起始状态编码为隐表示,作为循环单元的初始隐藏状态;
-
后续推演仅输入动作序列,不再重复引入起始状态;
-
明确「状态负责初始化,动作负责演化」的分工,提升多步预测的稳定性和灵活性。
这种重构让模型能更好地适应长序列动作驱动的演化,减少起始状态对长程推演的束缚。
PARoll 并行推演:让上千步推演落地
ADM-v2 提出「并行任意步滚动推演(PARoll)」,彻底解决了任意步预测的效率与可靠性问题。其核心思路是:长程推演中同时维护多个不同时间步幅的预测视角,并行生成未来状态,再通过视角间的差异估计不确定性。
PARoll 的价值不仅在于「并行提速」,更在于让上千步完整时域推演从「概念」走向「现实」—— 通过多视角交叉验证,模型能动态修正推演偏差,确保长时域下的预测精度,最终实现稳定的上千步推演。
从「学策略」到「评策略」:拓展动力学模型的应用边界
ADM-v2 的另一大突破是将动力学模型用于「离线策略评估」—— 在具身智能、离线强化学习等场景中,新策略往往无法在真实环境中反复试验,而 ADM-v2 的长程稳定推演能力,让「在模型内评估策略效果」成为可能。
在 DOPE 基准测试中,基于 ADM-v2 的完整时域推演评估,优于多种传统离线策略评估方法,其平均归一化绝对误差更低、排名相关性更高,首次验证了动力学模型可同时服务于「策略学习」与「策略评估」两大核心任务。
实验巅峰:性能与长程获益能力双突破
ADM-v2 构建的 ADM2PO-fh 在基准测试中创下新纪录:
-
D4RL 基准:平均性能 87.6,较此前强基线提升 4.6%;
-
NeoRL 基准:平均性能 79.0,较此前强基线提升 12.8%;
-
长程获益:与传统方法「推演越长性能越差」不同,ADM-v2 能持续从更长时域推演中获益,证明其长程推演的可靠性。
例如在 walker2d-medium-expert 任务中,ADM2PO-fh 得分 125.1,远超传统方法的 115.2,展现出强大的长程策略优化能力。
四、技术启示:动力学建模,世界模型的下一个必争之地
林浩鑫的两篇顶会论文,不仅提出了具体的技术方案,更为世界模型的发展指明了核心方向 —— 当状态表征能力趋于饱和,动力学建模将成为决定模型上限的关键。
核心启示一:推演路径重构比参数放大更重要
单纯扩大模型参数规模,无法解决自举式预测的误差累积问题;而 ADM 系列通过重构推演路径(跨时域直接预测),在不依赖超大参数的情况下,实现了长程推演能力的跨越式提升。这说明,动力学建模的核心矛盾是「推演逻辑设计」,而非「模型规模」。
核心启示二:长程可靠性是实用化的关键
世界模型的价值在于「内部预演」,而只有当推演能覆盖完整回合(上千步)且误差可控时,预演结果才具有决策价值。ADM-v2 的上千步稳定推演,让世界模型从「短程预测工具」真正迈向「数据驱动的内部模拟器」,为离线强化学习、机器人规划等场景的落地扫清了关键障碍。
核心启示三:多任务适配是动力学模型的未来
ADM-v2 同时支持策略学习与策略评估,证明动力学模型可成为通用的「环境模拟底座」。未来,随着多模态观测、复杂物理环境的适配,动力学模型有望成为通用智能体的核心组件,支撑更复杂的任务规划与决策。
结语:动力学建模开启世界模型新篇章
林浩鑫的连续两篇 ICLR 工作,系统性地解决了世界模型动力学建模的核心痛点,从 ADM 的「任意步直接预测」到 ADM-v2 的「上千步完整时域推演」,一步步推动世界模型走向实用化。这一系列成果不仅为离线强化学习、具身智能等领域提供了更高效的技术方案,更让行业意识到:模型规模扩大的同时,必须把动力学建模做对,才能让世界模型的能力真正落地。
对于机器人学习、通用智能体研发等前沿方向而言,ADM 系列的技术思路为解决「长程规划」「环境预演」等核心难题提供了全新范式。未来,随着动力学建模与多模态、复杂物理引擎的深度融合,世界模型有望真正成为「数字孪生环境」,支撑智能体在虚拟世界中完成充分训练与推演,最终实现更高效的真实世界落地 —— 而这一切,都始于对动力学建模的重视与突破。