OpenClaw 的爆火,让 AI 长期记忆能力成为焦点 —— 它能记住对话历史、用户偏好,实现上下文自由插拔,彻底改变了智能体的交互逻辑。而这一核心能力,如今被谷歌 DeepMind 与加州大学伯克利分校成功迁移到 3D 重建领域,推出了突破性架构 LoGeR(长时上下文几何重建)。这款凭借混合记忆模块的创新设计,一举打破了前馈 3D 重建模型的上下文与数据双重壁垒,将长序列视频重建能力推向近 2 万帧的新高度,在 KITTI 数据集上实现绝对轨迹误差(ATE)降低 74%,为大规模场景重建提供了全新解决方案。

3D 重建的核心痛点:上下文与数据的双重枷锁
尽管 DUSt3R、VGGT 等几何基础模型已能实现稳健的短时场景重建,但在处理城市级大范围场景或长序列视频时,仍面临两大无法逾越的障碍,这也是行业长期存在的技术瓶颈:
1. 上下文壁垒:双向注意力的 “算力陷阱”
双向注意力机制是学习复杂几何先验的关键,但它的二次复杂度使其只能局限于短时上下文窗口(几十到一百多帧)。对于数千甚至数万帧的长序列,直接应用双向注意力会导致算力爆炸、内存溢出(OOM),即便像 FastVGGT 这样的优化方法,也只能缓解内存压力,无法解决长距离依赖建模的核心问题。
2. 数据壁垒:短时训练的 “泛化困境”
当前 3D 重建模型大多在短时上下文 “气泡” 数据上训练,缺乏长序列场景的训练信号,导致模型在推理时无法泛化到大规模场景。例如 VGGT 等强基线模型,即便优化后能处理更多帧,在城市级大尺度场景中仍会完全失效,出现严重的尺度漂移和轨迹偏差。
这两大壁垒导致传统前馈模型难以兼顾 “长序列处理” 与 “高保真重建”,而 LoGeR 的出现,正是通过混合记忆架构与数据策略创新,同时打破了这两道枷锁。
核心创新:混合记忆模块,兼顾长时全局与短时精细
LoGeR 的核心突破在于提出了基于学习的混合记忆模块,通过 “分块处理 + 双记忆通道” 的设计,在不依赖后期优化的前提下,实现了长序列的高效、一致重建。其整体流程为:将输入视频流分块顺序处理,块内利用双向先验保证几何保真度,块间通过混合记忆模块传递信息,确保全局一致性。
这个双组件记忆系统,完美解决了长序列重建的核心矛盾:
1. 测试时训练(TTT):长时压缩记忆,锚定全局坐标
TTT 是参数化的长时记忆通道,核心作用是 “压缩存储全局信息,防止尺度漂移”。它通过大块测试时训练(LaCT)机制,维护一套跨块的快速权重集 W,在推理过程中完成两大操作:
-
应用操作:利用权重中存储的历史几何信息(如场景粗略形状、全局尺度),调节当前块的处理方式,确保新块与全局坐标框架对齐;
-
更新操作:将当前块的关键几何信息压缩后写入权重,实现长距离信息的线性传播,且内存占用始终保持固定大小,不受序列长度影响。
这一机制相当于给模型配备了 “全局地图记忆”,即便处理数万帧序列,也能牢牢锚定全局尺度,避免累积误差。
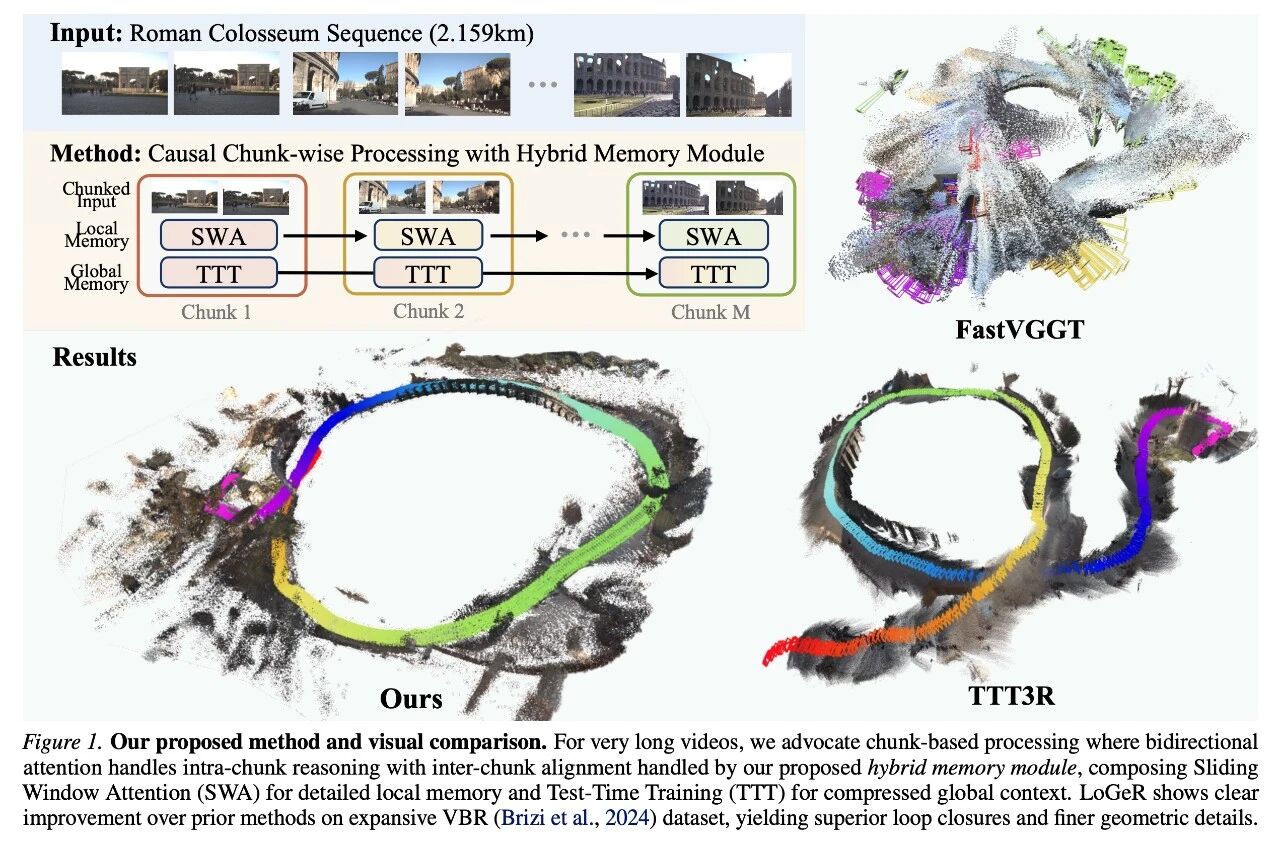
2. 滑动窗口注意力(SWA):短时无损记忆,保障局部对齐
单纯依赖 TTT 的压缩记忆会导致细节丢失,而 SWA 作为非参数化的短时记忆通道,恰好弥补了这一缺陷。它以稀疏方式插入网络(仅四层),仅关注前一个块与当前块的帧特征 tokens,建立无损的信息传递通道,确保相邻块之间的细粒度几何一致性。
SWA 的关键优势在于 “高效无损”:仅在相邻块间作用,计算成本可控,却能完整保留高保真特征,避免了块边界出现 “拼接断层”,让长序列重建既连贯又精细。
3. 前馈对齐:修正累积误差,强化全局一致
为进一步提升精度,LoGeR 还加入了纯前馈对齐步骤,通过算法自动修正块间累积的预测误差,确保所有块都严格对齐到统一的全局坐标系统,彻底解决了长序列中的漂移问题。
数据与训练创新:突破 “数据壁垒” 的关键策略
仅靠架构创新不足以打破数据壁垒,LoGeR 团队通过两大策略,让模型真正具备长序列泛化能力:
1. 构建长时训练数据集
重点增加大规模场景数据的比例,引入 TartanAirV2 等数据集,为模型提供学习几何压缩与长时依赖的必要信号,从数据层面解决 “短时训练无法泛化到长序列” 的问题。
2. 渐进式课程学习
为稳定递归 TTT 层的训练,采用三阶段渐进策略:从 48 帧、4 个块的简单序列开始,逐步增加块密度(至 12 个块),最终扩展到 128 帧、20 个块的复杂序列,迫使模型从依赖局部 SWA,逐步过渡到依赖全局 TTT 记忆,实现能力的稳步提升。
实测封神:从短序列到 2 万帧,全场景碾压传统方法
LoGeR 在多个权威数据集上的表现,全面超越了现有前馈式甚至部分基于优化的方法,用数据证明了混合记忆架构的强大实力:
1. 长序列重建:近 2 万帧稳定输出,误差大降
在包含最多 19000 帧的 VBR 数据集上,LoGeR 的绝对轨迹误差(ATE)比传统方法降低 30.8%,且能在长达 2.159km 的罗马斗兽场序列中,保持稳定的全局尺度和轨迹,而基线方法普遍出现严重的尺度漂移,轨迹与真实值偏差巨大。
2. 标准基准测试:KITTI 数据集 ATE 降低 74%
在 KITTI 数据集上,LoGeR 的平均 ATE 仅为 25.44m,比此前的前馈式方法降低超 74%;其变种 LoGeR * 的平均 ATE 更是低至 18.65m,超越了当前最强的基于优化的方法 VGGT-Long(27.64m),优势达 32.5%,尤其在无回环的开环场景中,抑制漂移的能力更为突出。
3. 短序列重建:细节保真度大幅提升
在 7-Scenes、ScanNetV2 等短序列数据集上,LoGeR 同样表现亮眼:3D 点云重建的倒角距离(Chamfer Distance)降低 69.2%,能精准还原书架等细节结构,避免了传统方法的几何畸变;在相机位姿估计上,ScanNet 数据集 ATE 降低 80.0%,TUM-Dynamics 数据集降低 66.1%,精度全面领先。
行业意义:开启长时上下文 3D 重建新时代
LoGeR 的突破不仅是技术层面的创新,更将 3D 重建的应用边界推向了新高度:
-
场景扩展:从之前的短时小场景,拓展到分钟级视频、城市级大范围场景,为自动驾驶、无人机测绘、虚拟现实等领域提供了高效解决方案;
-
效率提升:全前馈架构无需后期优化,处理长序列的速度远超基于 SLAM 的传统方法,且内存占用可控,具备工业化落地潜力;
-
范式创新:将 AI 记忆机制成功迁移到 3D 重建领域,证明了 “混合记忆” 是解决长时依赖问题的通用方案,为其他序列任务(如视频理解、机器人导航)提供了借鉴。
随着 LoGeR 的开源(项目地址:https://loger-project.github.io/),长序列 3D 重建的技术门槛被大幅降低。未来,无论是自动驾驶的全程场景重建,还是 VR/AR 的大规模环境建模,都将因这一技术而变得更高效、更精准,3D 重建行业也将正式迈入 “长时上下文” 新时代。