在 2026 英伟达 GTC 大会上,月之暗面创始人杨植麟作为本届唯一登台演讲的中国独立大模型创始人,带来《How We Scaled Kimi K2.5》主题分享,首次完整公开 Kimi K2.5 技术路线图,引发全球 AI 圈高度关注。
此前团队发布的注意力残差 AttnRes论文,重新定义 Transformer 经典残差结构,得到马斯克 “令人印象深刻” 的评价,卡帕西也指出行业对经典架构的认知仍有提升空间。
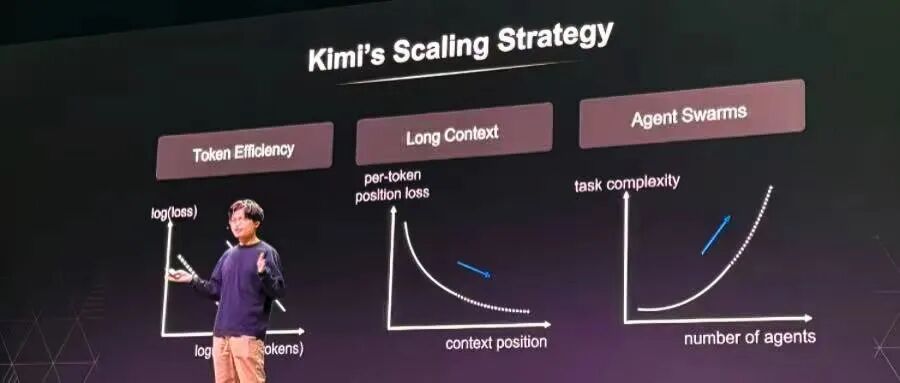
杨植麟在演讲中明确,Kimi 的技术进化围绕Token 效率、长上下文、智能体集群三大核心维度共振推进,不再是单纯算力堆砌,而是通过计算效率、长程记忆、自动化协作的三重增益叠加,突破模型能力上限。
一、重构训练底座:MuonClip 实现 2 倍 Token 效率
行业长期沿用的 Adam 优化器已难以适配超大规模训练,Kimi 团队推出MuonClip 优化器,在同等算力预算下,Token 效率达到 AdamW 的 2 倍。

针对 Muon 在万亿参数训练中出现的 Logits 爆炸问题,团队通过 Newton-Schulz 迭代搭配 QK-Clip 机制,将 max logits 稳定控制在 100 以内,保障训练收敛同时不影响 loss 表现。
此外,分布式 Muon 方案将优化器状态分布在并行组中,大幅提升大规模 GPU 集群训练的内存与计算效率。
二、长上下文革命:Kimi Linear 提速 5-6 倍
为解决长上下文推理成本高、延迟大的痛点,Kimi 推出Kimi Linear 混合注意力架构,以 3:1 比例搭配 Kimi Delta Attention 与全局注意力,在降低内存开销的同时保留模型表达力。
该架构已完成 1.4T Token 规模训练,在长短上下文与强化学习任务中均优于全注意力方案,128K—1M 上下文解码速度提升 5-6 倍,让长文本能力从 “可支持” 变为 “高效可用”。
三、重写残差连接:Attention Residuals 破解信息稀释
残差连接作为沿用十年的基础结构,存在深层信息被稀释的缺陷。Kimi 提出Attention Residuals 注意力残差,把固定加法累加改为 Softmax 注意力动态聚合,让模型按需读取前序层信息,稳定深层网络信息流。
该设计将残差连接理解为展开的 LSTM,用注意力机制扩展信息通道,相关代码与技术报告已同步开源。
四、跨模态突破:视觉 RL 反哺文本能力
杨植麟披露,在原生图文联合预训练中加入视觉强化学习,不仅提升视觉任务表现,还能反向赋能纯文本能力,使 MMLU-Pro、GPQA-Diamond 等基准指标提升 1.7%—2.2%。
这证明空间推理与视觉逻辑可转化为通用认知能力,团队正推进具备原生联合图文能力的开放模型研发。
五、智能体集群:Orchestrator 实现高效并行协作
Kimi K2.5 引入Orchestrator 编排器,推动智能体从单一体走向动态集群,可按需创建研究员、事实核查员等专业化子 Agent,拆解复杂任务并行执行,执行时间缩短数倍。
为避免 “串行塌缩”,团队设计实例化、完成度、结果三类奖励机制,引导模型真正实现任务分解与并行协作,解决多智能体伪协同问题。
结语:底层重构定义大模型新赛道
本次 GTC 演讲,Kimi 彻底公开了从优化器、注意力机制到残差连接的全栈重构方案,所有核心技术均持续开源。
杨植麟表示,AI 研究已进入系统规模化实验的新阶段,Kimi 正通过三维度技术共振,重新定义大模型 Scaling 路径。这套路线图也让行业看到,中国大模型已从应用创新走向底层架构突破,在全球 AI 竞争中占据关键技术高地。