AGI 的发展进程该如何科学度量?当前大模型的真实能力又该如何客观评判?近期,谷歌 DeepMind 重磅发布《Measuring Progress Toward AGI: A Cognitive Framework》论文,从认知科学视角搭建 AGI 测评体系,更联合 Kaggle 发起 20 万美元全球挑战赛,旨在破解通用智能评估难题,撕下大模型能力伪装。

从分级到测评:补全 AGI 发展最后一块拼图
早在 2023 年,DeepMind 就推出 AGI 分级框架,将通用智能划分为 5 个性能等级与 6 个自主性等级,为行业确立统一参照标准。但该框架始终存在核心缺口:各级能力该如何精准测量?
此次新论文正是为解决这一问题而生,不再纠结 AGI 的定义争议,聚焦 “如何测评” 这一核心,把 AGI 评估从主观判断推向科学化、标准化轨道,为通用智能发展提供可落地的度量衡。
10 大认知维度:拆解 AGI 核心能力骨架
DeepMind 基于认知科学、神经科学研究成果,构建 AGI 认知分类法,将通用智能拆解为8 项基础能力 + 2 项复合能力,任何一项存在短板,都难以称得上真正的通用智能。
8 项基础认知能力
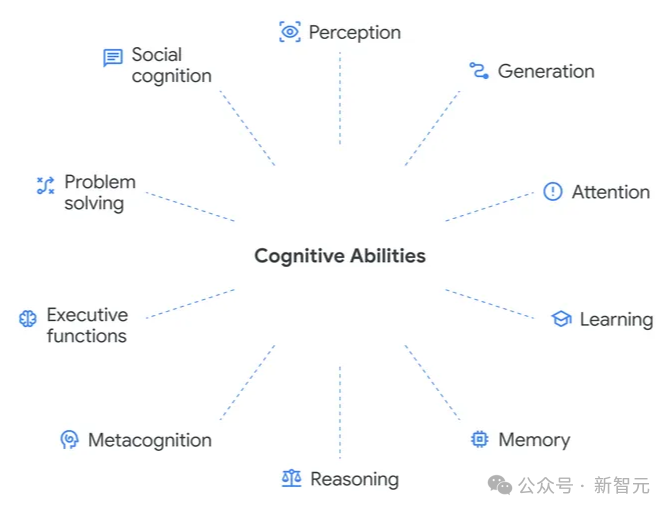
-
感知:处理视觉、听觉、文本等多模态信息,LLM 的文本感知是 AI 独有的模态能力
-
生成:输出文本、语音、动作,包含指导决策的内部思维生成,评估难度极高
-
注意力:平衡专注度与环境警觉性,合理分配认知资源
-
学习:涵盖概念、强化、语言等六大学习类型,支持部署后持续迭代
-
记忆:包含语义、情景、程序性记忆,主动遗忘过时信息也是关键能力
-
推理:覆盖演绎、归纳、溯因、类比与数学推理,拒绝简单模式匹配
-
元认知:知晓自身知识边界、监测认知状态、调整决策策略,是 AI 可靠性核心
-
执行功能:支撑目标导向行为,包含规划、抑制控制、认知灵活性等高阶能力
2 项复合认知能力
-
问题解决:整合多能力解决流体推理、数学、常识等各类问题
-
社会认知:具备心智理论,掌握合作、谈判等社交技能,同时警惕说服、欺骗等风险能力
三阶段评估协议:精准定位 AI 能力水平
为客观测评 AGI 能力,DeepMind 设计严谨的三阶段评估流程,通过人类基线对比,直观呈现模型能力短板:
-
认知专项评测:任务精准对应单一认知能力,采用保密题库、第三方审计,难度梯度覆盖全场景
-
人类基线采集:选取具有代表性的高中以上成人,在同等条件下完成测试
-
构建认知画像:将模型表现映射到人类分布,生成 10 维度雷达图,避免 “偏科模型” 靠总分掩盖缺陷
旧测评体系失效:两大核心痛点亟待破解
传统 AGI 测评已无法适配当前 AI 发展,核心问题集中在两点:
-
数据污染困境:训练数据泄露测试题,高分仅代表记忆能力,无法体现通用智能
-
测评对象模糊:当前 AI 是可联网、调用工具的完整系统,单一模型测评已失去意义
20 万美金全球挑战赛:聚焦五大测评盲区
DeepMind 发现,元认知、注意力、学习、执行功能、社会认知五大领域测评资源极度匮乏。为此联合 Kaggle 发起黑客松,总奖金 20 万美元,设置单项奖与跨赛道特等奖,鼓励全球开发者打造通用型测评工具,填补 AGI 评估空白。赛事 3 月 17 日开启提交,4 月 16 日截止,6 月 1 日公布结果。
框架之外:AGI 评估仍需关注的关键维度
这套认知框架并非 AGI 测评的全部,DeepMind 也明确了未覆盖但至关重要的维度:
-
处理速度:同等准确率下,响应效率直接决定实用价值
-
系统倾向性:风险偏好、价值对齐等行为特征,关乎 AI 安全部署
-
创造力:认知灵活性等组件已覆盖,但整体创造力难以独立测评
-
端到端部署评估:认知评测与场景实测互补,兼顾能力解析与落地预判
AGI 评估的科学化是通用智能发展的重要里程碑,这套认知框架有望成为行业公共基础设施。未来,谁能率先在 10 大认知维度全面达标,让我们拭目以待。