曾凭借 “算法优先、效率为王” 杀出重围,成为国产大模型 “希望之星” 的 DeepSeek,如今正陷入发展的至暗时刻。距离 DeepSeek-V3 发布已过 445 天,万众期待的 V4 模型屡次跳票,用户数据断崖式下滑,性能性价比被同类国产模型反超,昔日的 “火箭迭代” 速度戛然而止。从顶流到掉队,DeepSeek 仅用一年时间,其发展困局不仅是一家企业的危机,更折射出国产大模型赛道的残酷竞争与深层行业痛点。

断崖式下滑:顶流光环褪去,多项数据触底
如今的 DeepSeek,早已不复当年的辉煌,模型研发迟滞、用户数据大跌、市场表现疲软成为其现阶段的真实写照,核心指标的下滑更是直观印证了其发展的困境。
-
核心模型屡次跳票:备受行业期待的 DeepSeek V4 多模态大模型,从春节前官宣发布一路延期至 3 月,最新消息又传将推迟至 4 月,与腾讯混元新模型同台上线,持续的跳票让市场与行业的期待逐渐转为焦虑。
-
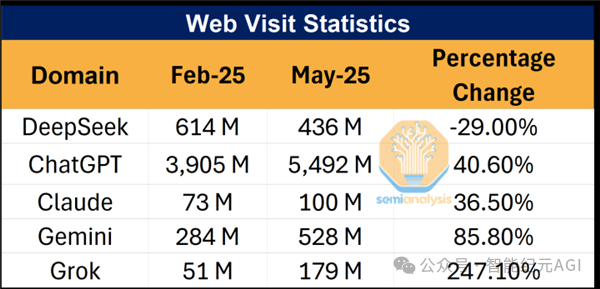
用户数据大幅萎缩:据 SemiAnalysis 和 Poe 平台数据,DeepSeek 平台用户使用率从 7.5% 的峰值骤降至 3%;官网流量在 2025 年 2 月至 5 月间下滑 29%,Token 调用流量从 42% 萎缩至 16%,反观 ChatGPT、Gemini 等竞品流量均实现大幅增长;其 App 也已下滑至苹果 App Store 效率榜第 36 位,被字节豆包、阿里千问等同类应用远远甩开。
-
性能性价比被反超:在 Artificial Analysis 最新的模型评测中,DeepSeek-V3.2 的性能和性价比远低于 Kimi-K2.5、MiniMax-M2.5、智谱 GLM-5 等国产开源大模型;即便在当下火热的 OpenClaw 生态中,其模型 API 的 Token 使用量也远不及上述同类国产模型,彻底失去了此前在开发者市场的优势。
-
产品迭代趋于停滞:过去一年里,DeepSeek 鲜有全新重要模型推出,仅以 “小幅迭代更新” 为主,偶有框架与技术论文发布;移动 App 的更新也仅停留在 “修复部分已知问题” 的基础层面,曾经凭借 DeepSeek-R1 推理模型 “震撼全球” 的辉煌,已然成为过往。
光速崛起:教科书级逆袭,曾是国产大模型之光
DeepSeek 的跌落之所以令人唏嘘,源于其此前堪称教科书级别的行业逆袭,在巨头林立的大模型赛道,它以差异化路线杀出重围,成为国产大模型的标杆。
DeepSeek 由幻方量化创始人梁文峰于 2023 年创立,依托幻方量化的算力底座,其避开了行业 “堆参数、烧算力” 的同质化误区,走出了**“算法优先、效率为王”**的独特发展路径,这也成为其快速崛起的核心密码。
2025 年初,DeepSeek-R1 横空出世,成为其崛起的关键节点 —— 仅以 557 万美元的训练成本,就实现了接近 GPT-4o 的性能表现,数学推理能力甚至实现反超,用极致的效率打破了大模型 “高成本即高性能” 的固有认知。
此后,DeepSeek V3 系列模型开启 “火箭式迭代”,平均 1-2 个月就完成一次大更新,开源权重迅速引爆全球开发者社区;同时其 API 定价低至行业十分之一,精准抢占中小企业和开发者市场,腾讯、百度等大厂及算力公司纷纷适配接入。
彼时的 DeepSeek,是速度与创新的代名词:旗下 App 上线数月下载量破 1 亿,周活逼近 9700 万;在代码、数学、长文本处理等垂直领域建立绝对优势;甚至让 “大模型六小虎” 陷入舆论的 “至暗时刻”,成为公认的国产大模型之光。
困局根源:四重矛盾交织,扼住发展咽喉
表面看,DeepSeek 的掉队源于 V4 模型的反复跳票与业务增长的不及预期,但深究背后,是技术、算力、生态、战略四重核心矛盾的深度交织,成为扼住其发展的关键咽喉,而算力瓶颈更是致命短板。
算力 “卡脖子”:硬件天花板难以突破
算力短缺是 DeepSeek 当前最核心的困境。有分析指出,DeepSeek 可稳定调用的高端芯片规模,不足 OpenAI 的十分之一,有限的算力资源需要同时支撑核心模型的预训练与日常推理服务,根本无法满足万亿参数级别模型的大规模调优与迭代。
尽管其凭借算法创新弥补了部分算力差距,走出了轻量化发展路线,但算法的优化终究无法突破硬件的绝对天花板。国产算力能力偏弱、海外 GPU 供应短缺的行业共性问题,从根源上锁死了 DeepSeek 的模型性能提升与迭代速度,成为其 V4 模型难产的核心原因。
技术路线:战略摇摆 + 难度陡增,迭代遇阻
在算力短缺的同时,DeepSeek 的技术路线也面临双重挑战。一方面,面对行业大模型多模态化、大参数量化的发展趋势,其原本坚持的 “轻量化、高效率” 路线出现战略摇摆,在是否跟进大参数模型研发上的犹豫,导致研发节奏被打乱;另一方面,大模型技术发展到现阶段,多模态融合、情感交互、个性化记忆等模块的研发难度陡增,2 月上线的百万上下文测试版,至今仍未完成相关模块的迁移与调优,技术攻坚进入深水区。
生态与商业化:先天短板,难以形成闭环
相较于智谱、月之暗面、MiniMax 等竞品,DeepSeek 在生态构建与商业化布局上存在先天短板。此前其凭借开源与低价 API 快速抢占开发者市场,但并未完成生态的深度沉淀,在 OpenClaw 生态爆发的当下,其模型适配度与使用量被竞品反超,就是生态短板的直接体现。
同时,DeepSeek 还面临开源免费与商业化盈利的平衡难题:作为开源明星,其任何商业化尝试都备受关注,而过于谨慎的商业化决策,导致其无法形成 “研发 - 生态 - 盈利 - 再研发” 的正向闭环,研发投入的可持续性受到影响。
口碑与期待:高关注下的高反噬,决策掣肘
作为曾经的国产大模型顶流,DeepSeek 始终处于行业的高度关注之下,这也让其陷入了 “高期待 = 高反噬” 的困境。此前的极致创新,让市场对其形成了 “超预期迭代” 的心理预期,而如今的小幅更新甚至迭代停滞,都被视为 “走下神坛”,口碑的反噬让其研发与发布决策更加谨慎,陷入 “不敢更 = 口碑差” 的恶性循环。
此外,行业竞争的白热化也让 DeepSeek 的发展雪上加霜:OpenAI、智谱等同行已进入 “月更模式”,字节、阿里等大厂凭借生态与流量优势快速布局,留给 DeepSeek 的发展窗口持续缩小。
破局之路:唯有 V4 破局,重回技术初心
DeepSeek 的快速跌落,不仅是一家企业的发展故事,更折射出全球大模型竞争的残酷本质,以及国产 AI 算力突围、技术路线选择、生态构建的深层行业困境。但不可否认的是,DeepSeek 依然拥有深厚的算法积累与研发底蕴,其故事远未结束,而顺利推出 V4 模型,成为其破局的唯一关键。
从目前的技术线索来看,DeepSeek V4 仍将延续其模型效率、高性价比的核心路线,无论是适配国产 AI 算力,还是优化 GPU 计算效率,都将聚焦于 AI Infra 和算力效率的全面提升,这也契合其 “算法优先” 的发展初心,也是其在算力短缺背景下的最优选择。
对于 DeepSeek 而言,唯有顺利推出 V4 模型,实现多模态、大上下文、情感交互等核心能力的突破,才能重新赢回市场与行业的信任;唯有坚守技术初心,持续深耕算法创新,才能在算力瓶颈下找到差异化发展路径;唯有加快生态构建与商业化探索,形成研发与市场的正向闭环,才能在白热化的竞争中站稳脚跟。
而对于整个国产大模型赛道而言,DeepSeek 的困局也是一次重要的警示:算力突围是行业发展的核心前提,技术路线的坚定选择远比盲目跟风重要,生态与商业化的闭环构建,才是大模型从 “技术创新” 走向 “产业引领” 的关键。
我们期待,经历低谷的 DeepSeek 能重新找回崛起时的锋芒,用 V4 模型打破质疑,重回顶流;更期待国产大模型能在算力、技术、生态的多重突破中,走出属于自己的发展之路,在全球 AI 竞争中占据一席之地。