当最强开源模型遇上最新一代算力硬件,一场推理性能的革命就此爆发。DaoCloud 与 vLLM 团队联手,在 NVIDIA Blackwell Ultra(GB300)上成功部署 DeepSeek-V3.2,凭借 NVFP4 量化、TP2 并行策略与分离式架构的组合拳,实现性能跨越式突破:单卡 Prefill 吞吐量达 7360 TGS,混合场景吞吐量 2816 TGS,双卡 DeepSeek-R1 更是创下 22476 TGS 的惊人成绩,较上一代 H200 实现 8-20 倍性能飞跃,为开源大模型大规模商业化落地筑牢技术底座。
一、核心性能突破:数据见证代际碾压
DeepSeek-V3.2 在 GB300 上的表现堪称 “炸裂”,关键场景性能数据刷新行业纪录:
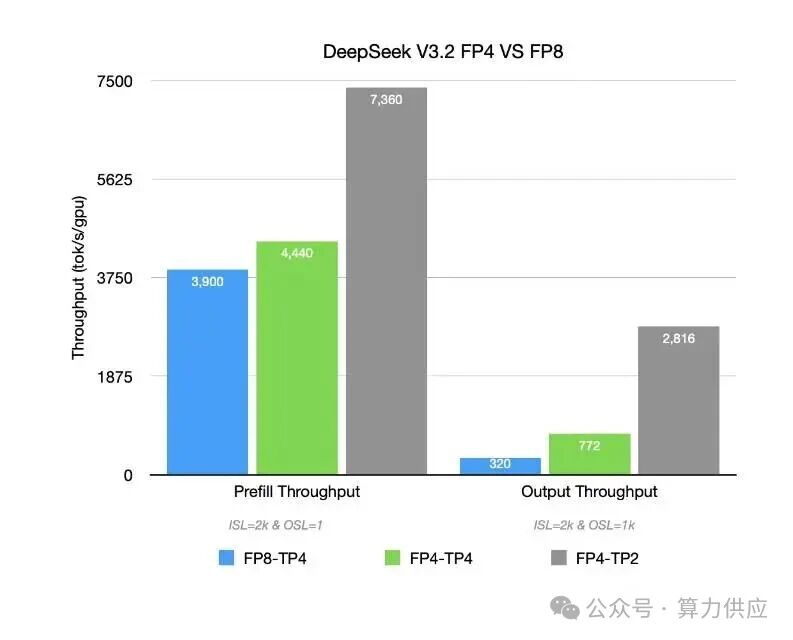
| 测试场景 | 配置方案 | 核心性能指标 | 较 H200 提升幅度 |
|---|---|---|---|
| Prefill 阶段(纯输入) | 单卡 GB300 + NVFP4 + TP2 | 7360 TGS | 8 倍 |
| 混合场景(输入 2k + 输出 1k) | 单卡 GB300 + NVFP4 + TP2 | 2816 TGS | 10-20 倍 |
| Prefill 阶段(纯输入) | 双卡 GB300 + NVFP4 + EP2(DeepSeek-R1) | 22476 TGS | - |
| 短输出混合场景(输入 2k + 输出 128) | 单卡 GB300 + NVFP4 + TP2 | 17451 TGS | 20 倍 |
这种性能飞跃并非偶然,而是硬件升级与软件优化深度协同的结果,其中 NVFP4 量化与 TP2 并行策略是核心关键。
二、性能密码:NVFP4 + TP2,榨干 GB300 算力
1. NVFP4 量化:极致压缩与带宽释放
GB300 第五代 Tensor Core 对 NVFP4 量化的原生支持,成为性能突破的基础:
-
显存占用骤降:单卡 288GB 显存(是 H200 的 2 倍),配合 NVFP4 量化,仅需 2 张卡即可容纳 DeepSeek 系列模型权重,彻底摆脱显存瓶颈;
-
带宽压力缓解:低精度计算大幅降低内存带宽消耗,减少数据传输延迟,直接提升 token 输出吞吐量;
-
算力充分释放:NVFP4 量化与 GB300 的高密度 FLOPs 完美适配,加速 MoE 前向传播,让硬件算力发挥到极致。
2. TP2 并行策略:反直觉的最优解
实验揭示关键结论:在 NVFP4 量化加持下,TP2(张量并行度 = 2)表现优于 TP4,成为最佳并行配置:
-
TP2 优势:模型张量拆分粒度适中,每张 GPU 承担足够工作量,充分榨干 Tensor Core 的 FP4 算力,Prefill 场景比 FP8 提升 1.8 倍,混合场景提升 8 倍;
-
TP4 劣势:拆分过细导致单卡负载不足,无法发挥 NVFP4 效率优势,性能收益有限;
-
最佳实践:推荐通过环境变量
export VLLM_USE_FLASHINFER_MOE_FP4=1配合启动参数-tp 2启动服务,最大化性能。
张量并行(TP)的核心逻辑是将模型权重等张量拆分到多个 GPU 协同计算,避免单卡显存限制,而 TP2 的配置恰好平衡了拆分粒度与计算效率,与 GB300 的硬件特性深度契合。
三、GB300 碾压 H200:硬件代际优势解析
GB300 之所以能实现性能狂飙,源于三大硬件升级,形成对 H200 的降维打击:
-
算力暴涨:FLOPs 达 H200 的 7.5 倍,峰值算力逼近 15 PFLOPs,为低精度计算提供强大支撑;
-
显存升级:288GB 超大显存 + 翻倍带宽,轻松容纳量化后的大模型权重,减少数据交换延迟;
-
架构优化:SM 单元中的 SFU 模块专门优化 Attention 计算,进一步提升 MoE 模型推理效率。
硬件的代际优势,为软件优化提供了充足的发挥空间,最终实现 “1+1>2” 的协同效应。
四、进阶调优:EP2 与分离式架构,适配复杂场景
针对不同推理场景,还可通过进阶配置进一步提升性能,核心优化方向包括 EP2 并行与分离式 Prefill 架构:
1. EP2 vs TP2:场景化并行策略选择
EP2(专家并行度 = 2)与 TP2 并非替代关系,而是适配不同场景的互补方案:
-
Prefill 主导场景(如长文本输入):EP2 更优。其 “大包低频” 的通信模式,更适合高并发下的 RDMA/NVLink 带宽利用,吞吐量上限比 TP2 高 10%-15%;
-
Decode 主导场景(如长输出生成):TP2 更稳。虽 EP2 在单 token 生成时间(TPOT)上有优势,但 TP2 能显著降低首字延迟(TTFT),在长输入短输出场景下整体吞吐更优。
2. 分离式 Prefill 架构:高并发与超长上下文的救星
面对超长上下文(10k-20k tokens)或高并发请求,P/D 分离架构(1P+1D 或 3P+1D)展现巨大潜力:
-
延迟更低:高并发下 TPOT 可控制在 60ms 以内,较集成式架构(>80ms)大幅降低;
-
扩展性更强:通过增加 Prefiller 节点(如 3P1D),可线性提升总吞吐量,有效解决 Prefill 瓶颈。
五、优化空间:DeepSeek-V3.2 仍有提升潜力
尽管性能已足够惊艳,但 DeepSeek-V3.2 对比 DeepSeek-R1 仍存在差距:R1 的 Prefill 吞吐量约为 V3.2 的 3 倍,核心原因在于:
-
V3.2 引入 Indexer/Sparse MLA 机制,增加了量化和索引计算开销,profiling 显示其 DSA 层内核执行时间是 MLA 层的 2.7 倍;
-
未来优化方向:随着
DeepseekV32IndexerBackend的成熟,在超长上下文场景下,DSA 的 Decode 优势将逐渐显现,性能有望进一步提升。
六、快速部署指南:复现巅峰性能
想要在 GB300 上复现上述性能,需满足以下环境配置并执行对应命令:
-
软件栈要求:vLLM v0.14.1+、CUDA 13.0+;
-
环境变量配置:
bash
运行
export VLLM_USE_FLASHINFER_MOE_FP4=1 -
启动命令示例:
bash
运行
vllm serve nvidia/DeepSeek-V3.2-NVFP4 -tp 2 --max-num-batched-tokens 20480 -
分离式架构启用:需应用 vLLM PR#32698 补丁或使用最新主干版本。
七、结语:开源模型推理进入新纪元
DeepSeek-V3.2 与 NVIDIA GB300 的成功结合,不仅刷新了开源大模型的推理性能纪录,更证明了 “低精度量化 + 先进并行策略 + 新一代硬件” 的协同模式,是突破性能天花板的关键。8-20 倍的性能提升,意味着大模型推理成本大幅降低,为其在企业级应用、高并发服务等场景的大规模落地扫清了障碍。
随着硬件迭代与软件优化的持续深入,开源大模型的推理性能仍有巨大提升空间,而 DeepSeek-V3.2 此次展现的潜力,也让市场对其后续迭代充满期待。