曾以 “火箭式迭代” 惊艳业界的 DeepSeek,正遭遇前所未有的 “慢节奏” 争议:原定春节前后发布的 V4 版本,历经三次延期后敲定 4 月上线,被网友戏称为 “贾跃亭下周回国” 式发布。反观 OpenAI 月更、Anthropic 密集迭代 Claude 4 系列,这场 “快慢之争” 的背后,是 DeepSeek 从 “模型发布” 向 “系统工程” 转型的阵痛,更是国产开源大模型在巨头围堵与算力自主压力下的战略取舍。
一、从 “狂飙” 到 “慢步”:DeepSeek 的迭代节奏反转
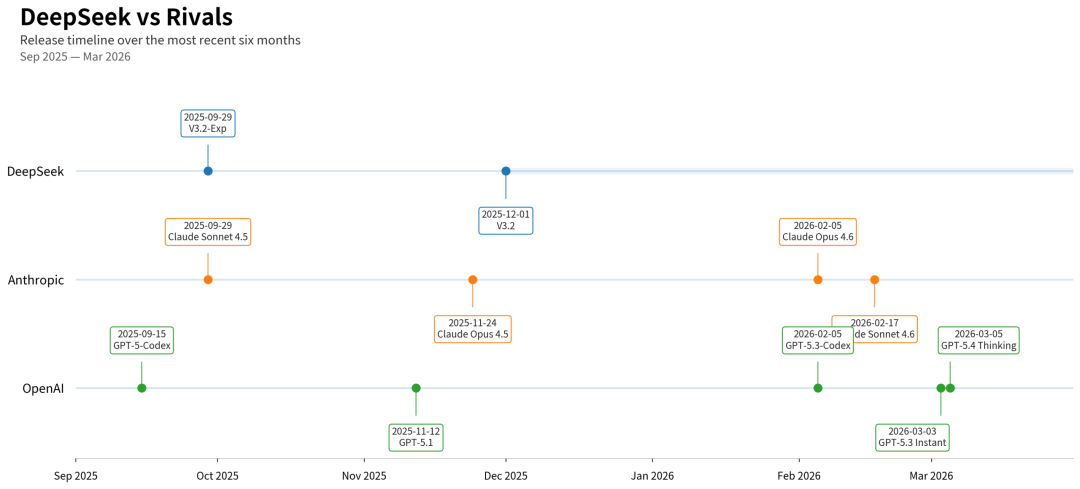
2025 年是 DeepSeek 的 “高光之年”,以平均 1-2 个月一次大更新的速度横扫开源市场:
-
V3 系列、R1 推理模型、V3.2-Exp(稀疏注意力)、V3.2 正式版密集落地;
-
数学 / 代码基准多次局部超越闭源巨头,API 价格优势显著,开源权重引发美股波动;
-
相关 App 累计下载量破 1.1 亿次,周活用户逼近 9700 万,成为国产开源 AI 的 “代名词”。
但 2025 年 12 月 V3.2 发布后,DeepSeek 的迭代突然 “刹车”:
-
三个月内无重大版本更新,仅进行上下文扩至 1M、API 微调等小修小补;
-
GitHub 和 Hugging Face 新仓库停滞,API 更新日志停留在 2025 年 12 月 1 日;
-
V4 发布时间从 1 月春节、2 月中旬、3 月初,一路推迟至 4 月,社区耐心逐渐耗尽。
与此同时,海外巨头正进入 “月更模式”,差距肉眼可见:
| 厂商 | 2025.12-2026.3 大版本迭代次数 | 核心动作 |
|---|---|---|
| OpenAI | 4 次 | 推出 GPT-5.1、5.3 Codex、5.3 Instant、5.4 Thinking,模型 + 产品 + 接口同步更新 |
| Anthropic | 2 次 + | 落地 Claude Opus 4.6、Sonnet 4.6,强化 Agent 长任务、1M 上下文能力 |
| DeepSeek | 0 次 | 仅小幅度功能优化,无新权重、无重大功能跃升 |
二、“慢下来” 的三大核心原因:转型、包袱与资源瓶颈
DeepSeek 的 “慢”,并非技术停滞,而是多重压力下的必然选择:
1. 从 “模型” 到 “系统”:迭代难度指数级上升
V4 的核心目标是适配 Agent 时代,这意味着 DeepSeek 必须从 “训练聪明的模型” 转向 “构建可执行的系统”:
-
数据层面:引入覆盖 1800 + 真实环境、8.5 万 + 复杂指令的 Agent 训练数据,数据合成与验证复杂度陡增;
-
技术层面:聚焦长期记忆、多模态处理等 Agent 核心能力,梁文锋团队 2026 年 1 月提出的 “条件记忆机制”、2025 年 12 月的 “流形约束超连接”,均是为解决长上下文瓶颈,这类底层创新的研发周期远长于简单参数调优;
-
工程层面:需要打通 “模型 - 工具 - 产品” 的闭环,而非单纯刷 benchmark,验证周期自然拉长。
2. 开源明星的 “包袱”:输不起的代际领先压力
作为全球开发者眼中的 “中国开源之光”,DeepSeek 没有犯错的空间:
-
预期压力:市场默认其 “用 1/10 成本达到 GPT 同等性能”,若 V4 仅微增性能却抬高推理成本,神话可能瞬间破灭;
-
生态压力:开源模式下,DeepSeek 需同步放出权重、推理框架、工具链,任何配套不到位都会引发生态失望;
-
口碑压力:闭源厂商可小步快跑试错,而 DeepSeek 一旦迭代平庸,就会被视为 “走下神坛”,口碑反噬风险远高于对手。
因此,对 DeepSeek 而言,“不发则已,发必是杀招”,一个没有明显代际差的 V4,反而不如推迟发布。
3. 资源与组织天花板:工业化竞争的极限测试
2026 年的大模型战争,已从 “单点技术比拼” 升级为 “工业化能力较量”,而这正是 DeepSeek 的短板:
-
闭环能力:OpenAI、Anthropic 已形成 “产品 - 用户 - 收入 - 再训练” 的正向循环,可通过用户反馈快速迭代,而 DeepSeek 的商业化闭环仍在构建;
-
算力压力:V4 计划深度适配国产芯片,成为首个完全跑在国产算力生态上的大模型。在外部技术封锁与内部算力自主的双重要求下,底层架构与硬件的 “饱和式适配”,必然消耗大量研发资源;
-
组织挑战:工业化迭代需要大规模工程团队、成熟的评测体系和数据流水线,这对 DeepSeek 的组织能力提出了更高要求。
三、对手 “快起来” 的逻辑:聚焦与闭环的胜利
海外巨头的 “月更”,并非盲目加速,而是精准的战略选择:
1. Anthropic:聚焦细分,密集突破
Anthropic 近一年路线高度聚焦,将资源集中在 “Agent + 企业工作流”:
-
核心方向锁定 coding、长任务处理、Agent 工作流优化,避免分散精力;
-
配套完善的 API 能力,让开发者快速落地应用,形成 “迭代 - 反馈 - 再优化” 的闭环;
-
版本更新围绕核心场景展开,用户体感明确,无需为无关功能消耗研发资源。
2. OpenAI:平台化推进,持续给市场确定性
OpenAI 采用 “模型小步快跑 + 产品持续上新” 的策略:
-
模型层:GPT-5 系列按功能拆分(Codex 聚焦代码、Thinking 聚焦推理),快速响应细分需求;
-
产品层:同步推出适配不同场景的工具,保持用户新鲜感;
-
API 层:不断增强接口能力,让企业和开发者始终有新功能可用,确定性远高于 “遥遥无期的大版本”。
四、悬念:4 月的 V4,能成为 “翻身之作” 吗?
尽管节奏放缓,但 DeepSeek 的核心竞争力仍在:V3.2 在数学 / 代码基准上仍具优势,而 V4 的爆料方向足够有杀伤力:
-
核心升级:押注多模态处理、长期记忆、代码能力跃升,补齐此前视觉、搜索短板;
-
战略适配:深度适配国产芯片,抢占算力自主时代的生态先机;
-
提前预热:OpenRouter 上出现的 Alpha 模型,已显露出 “多模态 + 长 Agent” 的能力雏形。
如果 V4 能如期兑现这些升级,DeepSeek 有望重新缩小与海外巨头的差距,巩固开源生态地位;但如果只是 “小修小补”,错过 Agent 时代的窗口期,其开源王者的光环可能逐渐褪色。
4 月的发布窗口已越来越近,DeepSeek 的 “慢” 到底是蓄力爆发,还是力不从心,答案即将揭晓。而这场 “快慢之争”,也为国产大模型敲响警钟:在 AI 行业的 “效率战” 中,既要守住技术深度,也要跟上迭代节奏,才能在巨头围堵中站稳脚跟。