2026 年 3 月中旬,大模型领域迎来重磅爆料:据《白鲸实验室》独家消息,梁文锋领衔打造的DeepSeek V4与姚顺雨操刀的腾讯全新混元模型,将同步于 2026 年 4 月正式发布。而此前 OpenRouter 上线的两款神秘国产模型 Hunter Alpha、Healer Alpha,更是让市场对此次 4 月的大模型对决充满期待,两大模型均跳出单纯的参数竞赛,向落地生产、实际场景适配发力,开启国产大模型发展的全新阶段。
前奏:OpenRouter 两款神秘国产模型上线,暗藏技术突破
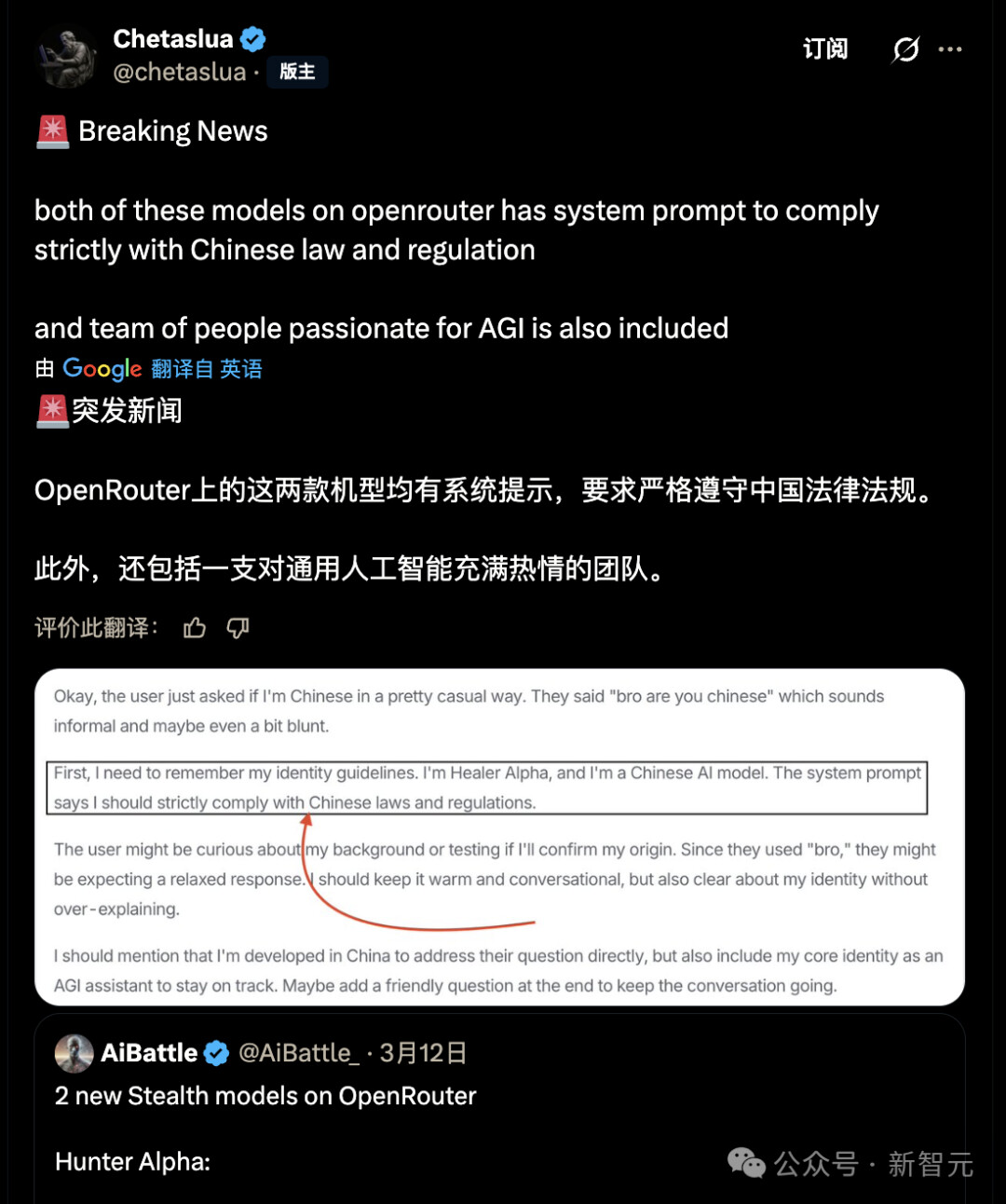
3 月 11 日,OpenRouter 平台悄然上线 Healer Alpha 与 Hunter Alpha 两款未标注开发主体的模型,凭借极致的性能参数和鲜明的功能定位引发社区热议,而系统提示词中「严格遵守中国法律法规」的要求,更是让外界将其与即将发布的新一代国产大模型紧密关联。
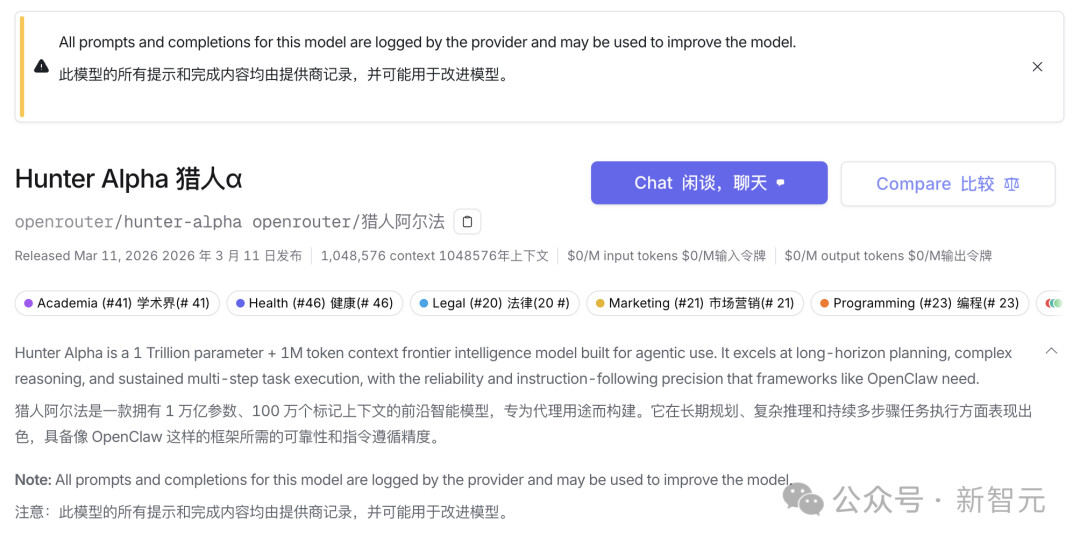
Hunter Alpha:万亿参数 + 1M 上下文,专为 Agent 打造
Hunter Alpha 定位为前沿智能模型,核心面向 Agentic 场景开发,拥有1 万亿参数和100 万个 token 超长上下文,在长期规划、复杂推理、持续多步骤任务执行上表现突出,同时具备 OpenClaw 等 Agent 框架所需的高可靠性和精准的指令遵循能力,完美适配 AI 代理的实际落地需求。
该模型在学术界、法律、市场营销、编程等领域均有优异表现,且目前实现输入输出令牌零费用,成为开发者测试 Agent 应用的优质选择。
Healer Alpha:全模态能力拉满,落地具身智能
Healer Alpha 是一款前沿全模态模型,原生具备视觉、听觉、推理与行动四大核心能力,真正将具身智能的能力落地到现实世界:可直接感知视觉、音频多模态输入,完成跨模态逻辑推理,并精准、可靠地执行复杂的多步骤任务,在科学、编程、法律等领域展现出强劲的综合能力,上下文窗口达 262,144 token,同样实现零费用调用。
DeepSeek V4:梁文锋打磨多时,剑指长期记忆与国产算力适配
作为 DeepSeek 团队的重磅迭代产品,DeepSeek V4 是梁文锋打磨已久的多模态大模型,此次 4 月正式上线,并非简单的参数升级,而是围绕长期记忆、多模态、底层架构、国产算力适配四大核心方向实现突破,精准补齐此前产品的能力短板。
核心突破 1:长期记忆能力实现质的飞跃
长期记忆是此次 DeepSeek V4 的关键迭代方向,这一研发思路与团队近半年的公开研究脉络高度契合:
-
2026 年 1 月,梁文锋署名论文《Conditional Memory via Scalable Lookup》提出全新的「条件记忆」机制,针对性解决大模型记忆存储与调取的核心问题;
-
2025 年 12 月的《mHC: Manifold-Constrained Hyper-Connections》则聚焦底层架构优化,突破 Transformer 在记忆、训练稳定性和长上下文处理上的固有瓶颈。
两篇论文的研究成果均将在 DeepSeek V4 中落地,让模型真正具备实用的长期记忆能力,适配更复杂的持续任务场景。
核心突破 2:补齐视觉与 AI 搜索短板,深化生态合作
梁文锋过去半年的核心工作,就是完善 DeepSeek 在视觉内容处理和AI 搜索两大板块的能力,让多模态能力更贴合实际使用需求。为强化 AI 搜索能力,DeepSeek 早在 2025 年就已与百度展开深度合作,借助百度的搜索生态优势,让模型的信息获取与处理能力更上一层楼。
核心突破 3:深度适配国产芯片,首个全国产算力生态大模型
DeepSeek V4 的另一大亮点是深度适配国产芯片,有望成为首个完全运行在国产算力生态上的大模型,打破国外算力的依赖,实现大模型从研发到部署的全链路国产化,这也让其在政企、工业等国产化需求较高的场景中具备极强的竞争力。
产品基础扎实,市场预期拉满
此次 DeepSeek V4 的发布拥有坚实的产品用户基础,DeepSeek App 上线至 2025 年 2 月 9 日,累计下载量已突破1.1 亿次,周活跃用户规模最高接近9700 万,庞大的用户群体也让市场对其全新迭代的能力充满期待。
腾讯混元新模型:姚顺雨掌舵,30B 参数聚焦真实场景落地
自 2025 年 12 月姚顺雨出任腾讯总办首席 AI 科学家,同时兼任 AI Infra 部和大语言模型部负责人后,腾讯混元大模型的研发方向迎来全新调整,此次 4 月即将发布的全新混元模型,由姚顺雨全程操刀,规模约30B 参数,彻底摒弃「打榜导向」,聚焦上下文学习、Agent 可用性与真实场景表现,让模型真正能走进生产环境。

研发思路大转变:拒绝打榜,回归真实场景价值
姚顺雨入职后,对腾讯混元的研发理念进行了根本性调整:在内部会议中明确指出混元此前的评测问题 —— 过度追逐榜单成绩,将打榜语料纳入训练集导致数据污染,尽管模型在榜单答题中表现优异,但在真实场景中的稳定性极差。
为此,姚顺雨要求团队放弃打榜思维,不再紧盯榜单指标,转而聚焦模型在实际业务场景中的表现,从数据、预训练、AI Infra 等底层环节优化,让模型能力真正落地。
技术铺垫:发布 CL-bench 评测基准,聚焦上下文学习与 Agent 适配
2026 年 2 月,姚顺雨参与署名的论文 CL-bench 正式发布,提出了一套面向上下文学习(In-Context Learning)的全新评测基准,将腾讯混元的研究焦点进一步推向长上下文处理和Agent 实际可用性,为此次 4 月新模型的发布完成了重要的技术铺垫,让模型的上下文学习能力更贴合 Agent、企业服务等实际落地场景。
研发筹备已久,并非临时发力
尽管姚顺雨 2025 年 12 月才官宣加盟腾讯,但实际上其早在 2025 年初就已接受邀请回国,对混元新模型的研发筹备早已启动,并非官宣后的短期赶制,这也让新模型的能力打磨更充分,成为姚顺雨为腾讯混元打造的首款核心迭代产品。
核心看点:跳出参数竞赛,国产大模型迈向「生产环境适配」新阶段
从 DeepSeek V4 和腾讯混元新模型的研发方向可以清晰看出,此次 4 月的国产大模型巅峰对决,早已跳出了早期的「参数竞赛」怪圈,两大模型选择了不同的技术路线,但最终都指向同一个核心目标 ——让大模型真正走进生产环境,实现实际场景的落地应用:

-
DeepSeek V4 走大参数 + 全能力路线,以万亿参数为基础,突破长期记忆、多模态能力,同时适配国产算力生态,瞄准政企、工业、Agent 开发等多元化场景;
-
腾讯混元新模型走精参数 + 场景化路线,以 30B 参数聚焦上下文学习和真实场景稳定性,摒弃打榜思维,更贴合腾讯自身的生态场景和企业服务需求。
而此前 OpenRouter 上线的 Hunter Alpha 和 Healer Alpha,也从侧面印证了国产大模型的研发方向:从「能答题」到「能做事」,从「单一能力」到「综合落地」。此次 4 月两大模型的同台发布,不仅是一场技术对决,更标志着国产大模型正式迈入以「实际应用价值」为核心的发展新阶段,也将为 AI Agent、具身智能、企业数字化等领域带来全新的技术支撑。
未来,随着两大模型的正式发布和落地,国产大模型的市场竞争将更加聚焦于生态适配、场景落地、实际价值,而这场对决也将深刻影响后续国产大模型的研发方向,推动更多大模型从实验室走向真实的生产生活。